
































![Linux 基础知识 [已完结]](/images/img-75.png)
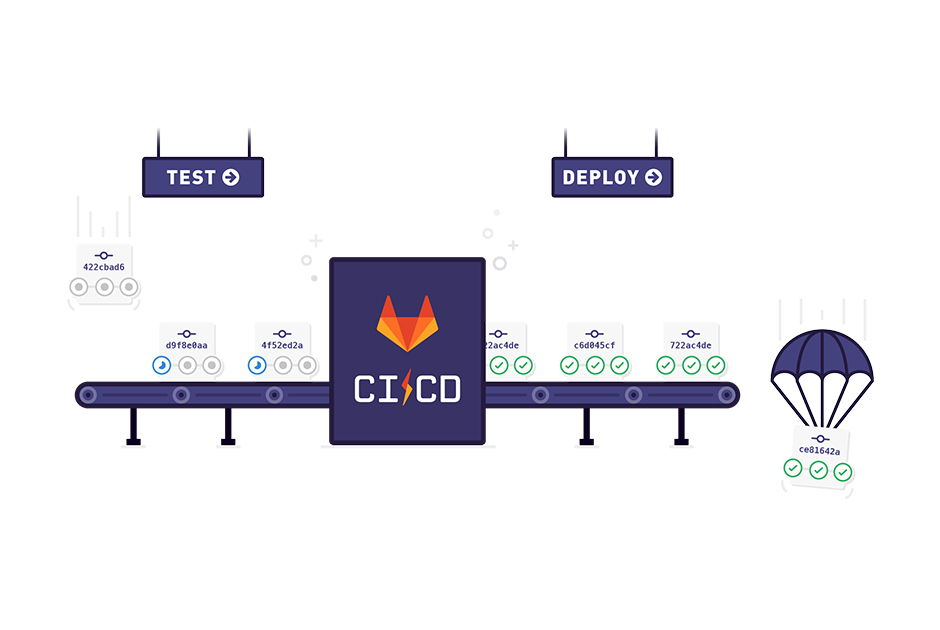
GitLab-CI/CD
传统的应用开发发布模式
开发团队 在开发环境中完成软件开发,单元测试,测试通过,提交到代码版本管理库。
运维团队 把应用部署到测试环境,供QA团队测试,测试通过后部署生产环境。
QA 团队 purple 进行测试,测试通过后通知部署人员发布到生产环境。
传统发布面临的挑战
错误发现不及时 很多错误在项目的早期可能就存在,到最后集成的时候才发现问题。
人工低级错误发生 产品和服务交付中的关键活动全都需要手动操作。
团队工作效率低 需要等待他人的工作完成后才能进行自己的工作。
开发运维对立 开发人员想要快速更新,运维人员追求稳定,各自的针对的方向不同。
经过上述问题我们需要作出改变,如何改变?
持续集成与持续交付软件开发的连续方法基于自动执行脚本,以最大程度地减少在开发应用程序时引入错误的机会。从开发新代码到部署新代码,他们几乎不需要人工干预,甚至根本不需要干预。
它涉及到在每次小的迭代中就不断地构建,测试和部署代码更改,从而减少了基于错误或失败的先前版本开发新代码的机会。
此方法有三种主要方法,每种方法都将根据最适合您的策略的方式进行应用。
持续集成(Continuous Inte ...
GitLab-CI语法
用 .gitlab-ci.yml配置任务此文档用于描述.gitlab-ci.yml语法,.gitlab-ci.yml文件被用来管理项目的runner 任务。如果想要快速的了解GitLab CI ,可查看快速引导。
gitlab-ci.yml从7.12版本开始,GitLab CI使用YAML文件(.gitlab-ci.yml)来管理项目配置。该文件存放于项目仓库的根目录,它定义该项目如何构建。开始构建之前YAML文件定义了一系列带有约束说明的任务。这些任务都是以任务名开始并且至少要包含script部分:
12345job1: script: "execute-script-for-job1" job2: script: "execute-script-for-job2"
上面这个例子就是一个最简单且带有两个独立任务的CI配置,每个任务分别执行不同的命令。
script可以直接执行系统命令(例如:./configure;make;make install)或者是直接执行脚本(test.sh)。
任务是由Runners接管并且由服务器中runne ...

Golang-函数
在编程中经常会调用相同或者类似的操作,这些相同或者类似的操作由同一段代码完成,函数的出现,可以避免重复编写这些代码。函数的作用就是把相对独立的某个功能抽象出来,使之成为一个独立的实体。
例如,开发一个支持人与人之间进行对话的社交网站,对话这个功能比较复杂,可以将它封装为一个函数,每次调用该函数就可以发起对话;大型网站都有日志功能,对所有重要操作都会记录日志,而日志处理需要由多行Go文件操作相关代码组成,将这些代码组装为函数,则每次写日志时调用此函数即可。
Go语言函数支持的特性包括:
参数数量不固定(可变参数)。
匿名函数及其闭包。
函数本身作为值传递。
函数的延迟执行。
把函数作为接口调用。
声明函数使用函数函数变量可变参数匿名函数和闭包延迟执行语句函数的声明以关键字func为标识,具体格式如下:
123func 函数名(参数列表) (返回参数列表){ 函数体}
函数名:函数名由字母、数字和下划线构成,但是函数名不能以数字开头;在同一个包内,函数名不可重复。注意:可暂时简单地将一个包理解为一个文件夹。
参数列表:参数列表中的每个参数都由参数名称和参数类 ...

k8s企业级DevOps实践-Kong的两种打开方式
概述KONG的核心对象为:upstream、target、service、route
upstream: 是对上游服务器的抽象;
target: 代表了一个物理服务,是 ip + port 的抽象;
service: 是抽象层面的服务,他可以直接映射到一个物理服务(host 指向 ip + port),也可以指向一个upstream 来做到负载均衡;
route: 是路由的抽象,他负责将实际的 request 映射到 service。
KONG监听的端口为:8000、8001、8443、8444、8100
8444: 带ssl的管理端口
8000/8443: 分别是用来监听来自客户端的Http 和 Https请求,等价于 Nginx 默认的 80 端口
8001: 端口便是默认的管理端口,可以通过 HTTP Restful API 来动态管理 Kong 的配置
8100: 为prometheus获取metrics指标端口
案例Nginx Conf01:
12345678910upstream helloUpstream { server localhost:30 ...
k8s企业级DevOps实践-Kong in Kubernetes
Kong介绍本文介绍将 Kong 微服务网关作为 Kubernetes 集群内部业务项目之间通讯的最佳实践,之前写过一篇文章使用 Nginx Ingress Controller 作为集群统一的流量入口:使用 Kubernetes Ingress 对外暴露服务,但是相比于 Kong Ingress Controller来说,Kong 支持的功能更加强大,更适合微服务架构:
拥有庞大的插件生态,能轻易扩展 Kong 支持的功能,比如 API 认证,流控,访问限制等;
Kong 服务本身和 Admin 管理 API 都集成在一个进程,通过端口区分两者,简化了部署的复杂度;
Kong 节点的配置统一持久化到数据库,所有节点通过数据库共享数据,在 Ingress 更新后能实时同步到各个节点,而 Nginx Ingress Controller 是通过重新加载机制响应 Ingress 更新,这种方式代价比较大,可能会导致服务的短暂中断;
Kong 有成熟的第三方管理 UI 和 Admin 管理 API 对接,从而能可视化管理 Kong 配置。
kong是一个云原生的、高性能的、可扩展的API ...
Golang-内置容器
变量和常量虽能存储数据,但是在编写一些逻辑稍复杂的程序中,往往需要存储更多、更复杂且不同类型的数据,这些数据一般存储在Go语言的内置容器中。
Go语言的内置容器主要有数组、切片和映射。下面详细介绍以上三种内置容器的特点和使用方法,学习目标:在编程中能使用恰当的容器存储数据并对其进行增加、删除和修改等操作。
数组 Array切片 Slice映射 Map
数组是具有相同类型且长度固定的一组数据项序列,这组数据项序列对应存放在内存中的一块连续区域中。
数组中存放的元素类型可以是整型、字符串或其他自定义类型。数组在使用前需先声明,声明时必须指定数组的大小且数组大小之后不可再变。
数组元素可以通过数组下标来读取或修改,数组下标从0开始,第一个元素的数组下标为0,第二个元素的数组下标为1,以此类推。
声明数组初始化数组数组增删range关键字遍历数组数组声明格式如下:
1var 数组变量名 [数组长度]元素类型
例如,声明数组student,长度为3,元素类型为string:
1var student [3]string
12345678910package mainimport &q ...
Golang-流程控制、斐波那契数列
流程控制Go语言基本上继承了C/C++语言所有流程控制语句流程控制语句主要包括:条件判断语句(if和switch)、循环控制语句(for、break和continue)和跳转语句(goto)。
if 判断for 循环switch 分支goto 跳转Go语言中,通过if关键字构成的条件判断语句进行条件判断,格式如下:
1234567if 表达式1 { 分支1} else if 表达式2 { 分支2} else { 分支3}
当表达式1的执行结果为true时,执行分支1,否则对表达式2的执行结果进行判断;
若表达式2的结果为true,执行分支2;
如果都不满足,则执行分支3。
当表达式1的执行结果为true时,执行分支1,否则对表达式2的执行结果进行判断;
若表达式2的结果为true,执行分支2;
如果都不满足,则执行分支3。
注意⚠:表达式后跟的左括号必须与表达式放在同一行中,否则程序在编译时将会触发错误,导致程序编译无法通过。另外,if、else if和else分支中对应的右括号可以另外换行,也可以与对应的左 ...
Golang-常量与运算符
常量概述: 常量与运算符是基本概念,对于Go语言,可以使用它们进行赋值、计算和比较。Go语言支持的运算包括算术运算、比较运算和逻辑运算等。
所谓常量,就是值不能变的量,比如常用的数学常数“π”就是一个常量。大多数的编程语言会使用全大写的变量名表示常量,所以约定俗成,如果常量的名字是全大写的变量,一般不做修改。
常量的定义显式定义隐式定义常量组定义常量枚举iota常量的声明以关键字const开头,后接变量类型并进行赋值,行尾没有其他标点符号。常量的显式声明格式如下:
1const 常量名 常量类型 = value
注意⚠️:一个常量被声明后可以不使用,但是变量一旦声明则必须使用。
1234567891011package mainimport "fmt"func main() { const a float64 = 3.1415 const b string = "Hello World" fmt.Println(a)}// 3.1415由于Go是编译型语言,定义常量时可以省略常量类型,因为编译器可以根据变量的值来推断其类型。常 ...
Golang-变量与基础数据类型、指针
Golang中的变量
声明变量标准格式批量声明1var 变量名 变量类型
例:声明变量num的类型为int
1var num int 使用关键字var和小括号,可以同时声明多个变量。
12345var( a int b string c bool)
初始化变量每种类型的变量初始化后都会有对应的默认值:
整型和浮点型变量的默认值为0。
字符串变量的默认值为空字符串。
布尔型变量默认为false。
切片、映射、函数和指针变量默认为nil。
注意:nil相当于其他编程语言中的null、None和NULL等,指代零值,在Go语言中只能赋值给切片、映射、函数、接口、指针或通道类型。
标准格式类型推导短变量声明并初始化1var 变量名 变量类型 = 表达式
例:声明变量num类型为int并赋值为1
1var num int = 1 在标准格式基础上,把变量类型省略后,编译器会根据等号右边的表达式推导变量的类型。例:初始化变量age值为20
1var age = 20同样会根据等号右边的表达式推导变量的类型。
1age := 30
多重赋值
1name, age := "Tom&qu ...

k8s企业级DevOps实践-Prometheus监控k8s集群、事件收集告警
服务监控对于运维开发人员来说,不管是哪个平台服务,监控都是非常关键重要的。在传统服务里面,我们通常会到zabbix、open-falcon、netdata来做服务的监控,但对于目前主流的K8s平台来说,由于服务pod会被调度到任何机器上运行,且pod挂掉后会被自动重启,并且我们也需要有更好的自动服务发现功能来实现服务报警的自动接入,实现更高效的运维报警,这里需要用到K8s的监控实现Prometheus,它是基于Google内部监控系统的开源实现。
Prometheus介绍Prometheus是由golang语言编写,这样它的部署实际上是比较简单的,就一个服务的二进制包加上对应的配置文件即可运行,然而这种方式的部署过程繁琐并且效率低下,这里不以这种传统的形式来部署Prometheus来实现K8s集群的监控,而是用到Prometheus-Operator来进行Prometheus监控服务的安装,这也是生产中常用的安装方式。
从本质上来讲Prometheus属于是典型的有状态应用,而其有包含了一些自身特有的运维管理和配置管理方式。而这些都无法通过Kubernetes原生提供的应用管理概念实现 ...

k8s企业级DevOps实践-HPA容器的弹性伸缩
HPA概述Horizontal Pod Autoscaler(HPA)是根据资源利用率或者自定义指标自动调整replication controller, Deployment 或 ReplicaSet,实现部署的水平自动扩缩容,让部署的规模接近于实际服务的负载。如果是DaemonSet这种无法缩放的对象,他是不支持的。
HPA控制原理K8s中的MetricsServer会持续采集Pod的指标数据,HPA 控制器通过 Metrics Server(需要提前安装) 的 API(Heapster 的 API 或聚合 API)获取集群中资源的使用状态,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的副本控制器(Deployment、RC 或 ReplicaSet)发起 scale 操作,然后副本控制器会调整 Pod 的副本数量,完成扩缩容操作。
假设存在一个叫 A 的 Deployment,包含3个 Pod,每个副本的 Request 值是 1 核,当前 3 个 Pod 的 CPU 利用率分别是 60 ...

k8s企业级DevOps实践-最小linux系统alpine制作Docker基础镜像
Alpine简称高山的 是一款非常适合做k8s基础镜像的linux
小巧:基于Musl libc和busybox,和busybox一样小巧,最小的Docker镜像只有5MB;
安全:面向安全的轻量发行版;
简单:提供APK包管理工具,软件的搜索、安装、删除、升级都非常方便。
适合容器使用:由于小巧、功能完备,非常适合作为容器的基础镜像。
12345678910111213141516# nodejs环境,FROM alpine+glibc环境WORKDIR /appRUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories &&\apk --no-cache add ca-certificates wget &&\wget -q -O /etc/apk/keys/sgerrand.rsa.pub http://alpine-pkgs.sgerrand.com/sgerrand.rsa.pub &&\wget ht ...
k8s企业级DevOps实践-集群服务发现及Ingress的实现服务访问
Service服务访问我们已经能够通过Deployment来创建一组Pod来提供具有高可用性的服务。虽然每个Pod都会分配一个单独的Pod IP,然而却存在如下两个问题:
Pod IP仅仅是集群内可见的虚拟IP,外部无法访问。
Pod IP会随着Pod的销毁而消失,当ReplicaSet对Pod进行动态伸缩时,Pod IP可能随时随地都会变化,这样对于我们访问这个服务带来了难度。
Service 负载均衡/Cluster IPservice是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP 。使用Service对象,通过selector进行标签选择,找到对应的Pod:
myblog/deployment/svc-myblog.yaml
12345678910111213apiVersion: v1kind: Servicemetadata: name: myblog namespace: demospec: ports: - port: 80 protocol: TCP ...
k8s企业级DevOps实践-k8s的持久化存储
Volume在K8s上,Pod的生命周期可能是很短,它们会被频繁地销毁和创建,自然在容器销毁时,里面运行时新增的数据,如修改的配置及日志文件等也会被清除。解决这一问题时可以用K8s volume来持久化保存容器的数据,Volume的生命周期独立于容器,Pod中的容器可能被销毁重建,但Volume会被保留。
本质上,K8s volume是一个目录,这点和Docker volume差不多,当Volume被mount到Pod上,这个Pod中的所有容器都可以访问这个volume,在生产场景中,我们常用的类型有这几种:
emptyDir
hostPath
PersistentVolume(PV) & PersistentVolumeClaim(PVC)
StorageClass
emptyDiremptyDir是最基础的Volume类型,pod内的容器发生重启不会造成emptyDir里面数据的丢失,但是当pod被重启后,emptyDir数据会丢失,也就是说emptyDir与pod的生命周期是一致的,这个使用场景实际上是在生产环境某些时候,它的最实际实用是提供Pod内多容器的volum ...
k8s企业级DevOps实践-Kubernetes中DaemonSet启动日志收集
下载filebeat12wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.4.0-linux-x86_64.tar.gztar -xf filebeat-7.4.0-linux-x86_64.tar.gz
制作filebeat镜像12345678910cat filebeat-7.4.0-linux-x86_64/dockerfileFROM registry.cn-shanghai.aliyuncs.com/wikifx/base:alpine-glibc-ShanghaiWORKDIR /appCOPY . .RUN chmod +x filebeatENTRYPOINT ["/app/filebeat", "-e", "-path.home", "./", "-path.data", "./data"]
编排文件编写12345678910111213141516171 ...
k8s企业级DevOps实践-k8s调度策略:NodeSelector/nodeAffinity/污点与容忍
为何要控制Pod应该如何调度
集群中有些机器的配置高(SSD,更好的内存等),我们希望核心的服务(比如说数据库)运行在上面
某两个服务的网络传输很频繁,我们希望它们最好在同一台机器上
……
NodeSelector调度 label是kubernetes中一个非常重要的概念,用户可以非常灵活的利用 label 来管理集群中的资源,POD 的调度可以根据节点的 label 进行特定的部署。
查看节点的label:
1$ kubectl get nodes --show-labels
为节点打label:
1$ kubectl label node k8s-master disktype=ssd
当 node 被打上了相关标签后,在调度的时候就可以使用这些标签了,只需要在spec 字段中添加nodeSelector字段,里面是我们需要被调度的节点的 label。
12345678910111213...spec: hostNetwork: true # 声明pod的网络模式为host模式,效果通docker run --net=host volumes: - name: ...
k8s企业级DevOps实践-workload(工作负载)、副本保障机制、Pod驱逐策略、服务的滚动更新和回滚
只使用Pod, 将会面临如下需求:
业务应用如何启动多个副本
Pod重建后IP会变化,外部如何访问Pod服务
运行业务Pod的某个节点挂了,如何自动帮我把Pod转移到集群中的可用节点启动起来
我的业务应用功能是收集节点监控数据,需要把Pod运行在k8s集群的各个节点上
Workload (工作负载)控制器又称工作负载是用于实现管理pod的中间层,确保pod资源符合预期的状态,pod的资源出现故障时,会尝试 进行重启,当根据重启策略无效,则会重新新建pod的资源。
ReplicaSet: 代用户创建指定数量的pod副本数量,确保pod副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能
Deployment:工作在ReplicaSet之上,用于管理无状态应用,目前来说最好的控制器。支持滚动更新和回滚功能,还提供声明式配置
DaemonSet:用于确保集群中的每一个节点只运行特定的pod副本,通常用于实现系统级后台任务。比如ELK服务
Job:只要完成就立即退出,不需要重启或重建
Cronjob:周期性任务控制,不需要持续后台运行
StatefulSet:管理有状态应用
De ...
k8s企业级DevOps实践-Pod管理、健康检查、ConfigMap和Secret的定义与容器编排
核心组件静态Pod的方式:
123456789101112131415161718192021222324## etcd、apiserver、controller-manager、kube-scheduler[root@k8s-master ~]# kubectl -n kube-system get poNAME READY STATUS RESTARTS AGEcoredns-58cc8c89f4-gnmdb 1/1 Running 2 22hcoredns-58cc8c89f4-r9hlv 1/1 Running 2 22hetcd-k8s-master 1/1 Running 3 22hkube-apiserver-k8s-master 1/1 Running 3 22hk ...
k8s企业级DevOps实践-Kubernetes架构、Kubernetes集群安装(两种方式)
Kubernetes架构引言学习kubernetes的架构及工作流程,使用Deployment管理Pod生命周期,实现服务不中断的滚动更新,通过服务发现来实现集群内部的服务间访问,并通过ingress-nginx实现外部使用域名访问集群内部的服务。
目标让Django demo项目可以运行在k8s集群中,可以使用域名进行服务的访问。
理解架构及核心组件
使用kubeadm快速搭建集群
运行第一个Pod应用
Pod进阶
Pod控制器的使用
实现服务与Node绑定的几种方式
负载均衡与服务发现
使用Ingress实现集群服务的7层代理
Django项目k8s落地实践:网页链接
基于ELK实现kubernetes集群的日志平台可参考:网页链接
集群认证与授权
纯容器模式的问题
业务容器数量庞大,哪些容器部署在哪些节点,使用了哪些端口,如何记录、管理,需要登录到每台机器去管理?
跨主机通信,多个机器中的容器之间相互调用如何做,iptables规则手动维护?
跨主机容器间互相调用,配置如何写?写死固定IP+端口?
如何实现业务高可用?多个容器对外提供服务如何实现负载均衡?
容器的业务中断了, ...

Nginx负载调度策略和一致性hash算法
Nginx的负载均衡算法静态调度算法(和节点无关的调度算法)
rr轮询(默认的调度算法) 平均轮询
wrr权重轮询(通过此参数进行权重调度#weight=number;) 能者多劳
ip_hash(人话:同一个ip的客户分配到同一台rs上,且不支持backup参数,和weight参数。) 当一个请求到达时,先将客户端IP通过哈希算法哈希出一个值,在随后的客户端请求中,客户端IP的哈希值只要相同,就会分配至同一台服务器,该调度算法可以解决动态网页的session共享问题。(会话保持) LVS负载均衡中的-p参数、keepalive配置里的persistence_ timeout 50参数都类似这个nginx里的ip_hash参数,其功能均为解决动态网页的session共享问题。
会话保持比较流行的解决方案: 1. 弃用此方案,将用户会话存储在后端共享缓存的redis中。供所有前端web服务器从指定的redis缓存服务器中找到共享的会话。 2. cookies技术,服务器根据客户端的请求信息生成cookie并发送给客户端。当客户端请求到第二台节点上时,服务器通过 ...