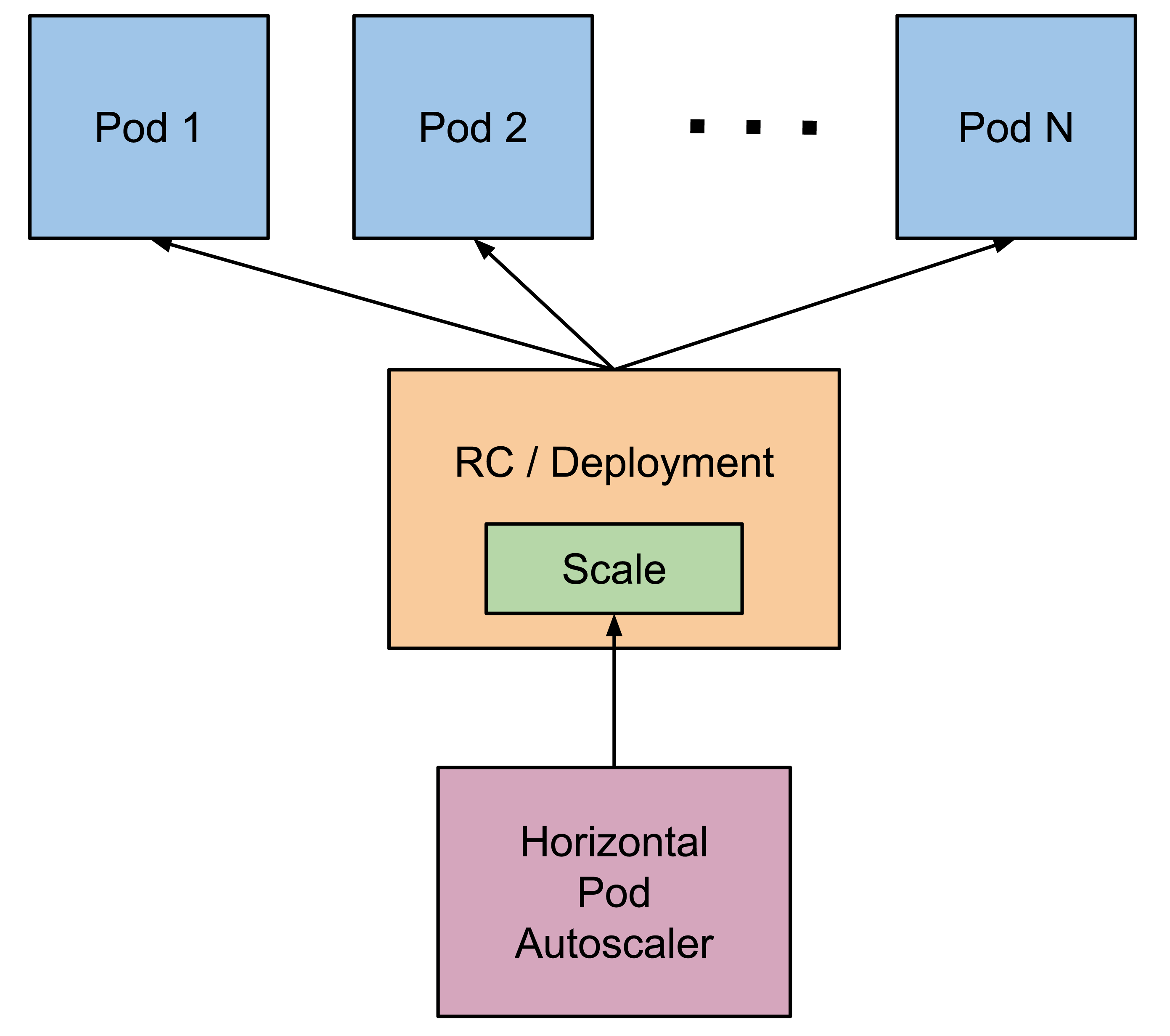
HPA概述
Horizontal Pod Autoscaler(HPA)是根据资源利用率或者自定义指标自动调整replication controller, Deployment 或 ReplicaSet,实现部署的水平自动扩缩容,让部署的规模接近于实际服务的负载。如果是DaemonSet这种无法缩放的对象,他是不支持的。
HPA控制原理
K8s中的MetricsServer会持续采集Pod的指标数据,HPA 控制器通过 Metrics Server(需要提前安装) 的 API(Heapster 的 API 或聚合 API)获取集群中资源的使用状态,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的副本控制器(Deployment、RC 或 ReplicaSet)发起 scale 操作,然后副本控制器会调整 Pod 的副本数量,完成扩缩容操作。
假设存在一个叫 A 的 Deployment,包含3个 Pod,每个副本的 Request 值是 1 核,当前 3 个 Pod 的 CPU 利用率分别是 60%、70% 与 80%,此时我们设置 HPA阈值为 50%,最小副本为 3,最大副本为 10。接下来我们将上述的数据带入公式中:
总的 Pod 的利用率是 60%+70%+80% = 210%
当前的 Target 是 3
算式的结果是 70%,大于50%阈值,因此当前的 Target 数目过小,需要进行扩容 重新设置 Target 值为 5,此时算式的结果为 42% 低于 50%,判断还需要扩容两个容器 此时 HPA 设置 Replicas 为 5,进行 Pod 的水平扩容。
经过上面的推演,可以协助开发者快速理解 HPA 最核心的原理,不过上面的推演结果和实际情况下是有所出入的,如果开发者进行试验的话,会发现 Replicas 最终的结果是 6 而不是 5。这是由于 HPA 中一些细节的处理导致的。 主要包含如下三个主要的方面:
噪声处理 通过上面的公式可以发现,Target 的数目很大程度上会影响最终的结果,而在 Kubernetes 中,无论是变更或者升级,都更倾向于使用 Recreate 而不是 Restart 的方式进行处理。这就导致了在 Deployment 的生命周期中,可能会出现某一个时间,Target 会由于计算了 Starting 或者 Stopping 的 Pod 而变得很大。这就会给 HPA 的计算带来非常大的噪声,在 HPA Controller 的计算中,如果发现当前的对象存在 Starting 或者 Stopping 的 Pod 会直接跳过当前的计算周期,等待状态都变为 Running 再进行计算。
冷却周期 在弹性伸缩中,冷却周期是不能逃避的一个话题,很多时候我们期望快速弹出与快速回收,而另一方面,我们又不希望集群震荡,所以一个弹性伸缩活动冷却周期的具体数值是多少,一直被开发者所挑战。在 HPA 中,默认的扩容冷却周期是 3 分钟,缩容冷却周期是 5 分钟。
界值计算 我们回到刚才的计算公式,第一次我们算出需要弹出的容器数目是 5,此时扩容后整体的负载是 42%,但是我们似乎忽略了一个问题:一个全新的 Pod 启动会不会自己就占用了部分资源?此外,8% 的缓冲区是否就能够缓解整体的负载情况?要知道当一次弹性扩容完成后,下一次扩容要最少等待 3 分钟才可以继续扩容。为了解决这些问题,HPA 引入了边界值 △,目前在计算边界条件时,会自动加入 10% 的缓冲,这也是为什么在刚才的例子中最终的计算结果为 6 的原因。
HPA工作流程
- 创建HPA资源,设定目标CPU使用率限额,以及最大/最小实例数,一定要设置Pod的资源限制参数: request,否则HPA不会工作。
- 控制管理器每隔30s(在kube-controller-manager.service中可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况。
- 然后与创建时设定的值和指标做对比(平均值之和/限额),求出目标调整的实例个数。
- 目标调整的实例数不能超过第一条中设定的最大/最小实例数。如果没有超过,则扩容;超过,则扩容至最大的实例个数。
- 重复第2-4步。
自动伸缩算法
HPA Controller会通过调整副本数量使得CPU使用率尽量向期望值靠近,而且不是完全相等。另官方考虑到自动扩展的决策可能需要一段时间才会生效:例如当pod所需要的CPU负荷过大,从而在创建一个新pod的过程中,系统的CPU使用量可能会同样在有一个攀升的过程。所以在每一次作出决策后的一段时间内,将不再进行扩展决策。对于扩容而言,这个时间段为3分钟,缩容为5分钟(在kube-controller-manager.service中可以通过 --horizontal-pod-autoscaler-downscale-delay, --horizontal-pod-autoscaler-upscale-delay进行调整)。 HPA Controller中有一个tolerance(容忍力)的概念,它允许一定范围内的使用量的不稳定,现在默认为0.1,这也是出于维护系统稳定性的考虑。例如设定HPA调度策略为cpu使用率高于50%触发扩容,那么只有当使用率大于55%或者小于45%才会触发伸缩活动,HPA会尽力把Pod的使用率控制在这个范围之间。 具体的每次扩容或者缩容的多少Pod的算法为:Ceil(前采集到的使用率 / 用户自定义的使用率) * Pod数量)。 每次最大扩容pod数量不会超过当前副本数量的2倍。
HPA使用场景
使用kubectl scale命令可以实现对pod的快速伸缩功能,但是我们平时工作中我们并不能提前预知访问量有多少,资源需求多少。这就很麻烦了,总不能为了需求总是把pod设置为最多状态,这样太浪费资源;也不能当请求量上来以后再去伸缩pod,这样会有好多请求不成功。
HPA版本说明
目前版本有:autoscaling/v1、autoscaling/v2beta1和autoscaling/v2beta2 三个大版本 。
- autoscaling/v1 只支持CPU一个指标的弹性伸缩
- autoscaling/v2beta1 支持自定义指标
- autoscaling/v2beta2 支持外部指标
kubectl explain hpa ##默认查询到的是autoscaling/v1版本 kubectl explain hpa --api-version=autoscaling/v2beta1 ##如果使用其他版本,可以使用--api-version指明版本
HPA操作演示
例如:我有个deployment叫myapp现在只有一个副本数,最多只能8个副本数,当pod的cpu平均利用率超过百分之50或内存平均值超过百分之50时,pod将自动增加副本数以提供服务。
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp #设置相关连的工作负载
minReplicas: 1 ##至少1个副本
maxReplicas: 4 ##最多4个副本
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 10 ##注意此时是根据使用率,也可以根据使用量:targetAverageValue
# 内存方式不建议用,开发人员技术能力参差不齐,防止内存溢出疯狂扩容
# - type: Resource
# resource:
# name: memory
# targetAverageUtilization: 10 ##注意此时是根据使用率,也可以根据使用量:targetAverageValue
等价于:
kubectl autoscale deployment myapp-hpa --cpu-percent=10 --min=1 --max=4
# kubectl describe hpa name 查看创建详细