启动过程
网络调试
临时关启网卡
ifup {interface} || ifconfig {interface} up
ifdown {interface} || ifconfig {interface} down添加多块网卡
[felix@es-node03 ~]$ cat /etc/sysconfig/network-scripts/ifcfg-ens160
TYPE=Ethernet #设备类型为以太网设备
BOOTPROTO=none #是否启用该设备 static静态IP 或dhp 或none无(不指定),如是none,配上IP地址和 static效果一样
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens160 #网卡名字
UUID=6b1f051d-11c8-4d83-ba66-c6d98414ca84 #网卡UUID,全球唯一
DEVICE=ens160 #设备名字,再内核中识别的名字
ONBOOT=yes #启用该设备,如果no,表示不启动此网络设备
IPADDR=192.168.200.153 #IP地址
PREFIX=24 #子网掩码,24相当于255.255.255.0
GATEWAY=192.168.200.1 #网关
DNS1=172.18.16.1 #首选DNS
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
cp /etc/sysconfig/network-scripts/ifcfg-ens160 /etc/sysconfig/network-scripts/ifcfg-ens161
#更改内容ens161
NAME=ens161
UUID=6b1f051d-11c8-4d83-ba66-c6d98414ca84 #删除UUID
DEVICE=ens161
IPDADDR=192.168.200.154
systemctl restart NetworkManager
systemctl restart network配置临时IP
ifconfig {interface} {ip addr}查看端口监听状态
netstat命令:查看系统中网络连接状态信息 常用的参数格式:netstat- lntup
- -a -all显示本机所有连接和监听的端口
- -n --numeric don't resolve names以数字形式显示当前建立的有效连接和端口
- -u 显示ud协议连接
- -t显示tcp协议连接
- -p,--programs显示连接对应的PID与程序名
- -u显示udp协议连接
[root@es-node03 ~]# netstat -lntup
Active Internet connections (only servers)
协议 接收 发送 本地IP地址 远程IP地址 状态 PID
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:8070 0.0.0.0:* LISTEN 3790/python3LISTEN:(Listening for a connection.)侦听来自远方的TCP端口的连接请求 SYN-SENT:(Active; sent SYN. Waiting for a matching connection request after having sent a connection request.)再发送连接请求后等待匹配的连接请求 SYN-RECEIVED:(Sent and received SYN. Waiting for a confirming connection request acknowledgment after having both received and sent connection requests.)再收到和发送一个连接请求后等待对方对连接请求的确认 ESTABLISHED:(Connection established.)代表一个打开的连接 FIN-WAIT-1:(Closed; sent FIN.)等待远程TCP连接中断请求,或先前的连接中断请求的确认 FIN-WAIT-2:(Closed; FIN is acknowledged; awaiting FIN.)从远程TCP等待连接中断请求 CLOSE-WAIT:(Received FIN; waiting to receive CLOSE.)等待从本地用户发来的连接中断请求 CLOSING:(Closed; exchanged FIN; waiting for FIN.)等待远程TCP对连接中断的确认 LAST-ACK:(Received FIN and CLOSE; waiting for FIN ACK.)等待原来的发向远程TCP的连接中断请求的确认 TIME-WAIT:(In 2 MSL (twice the maximum segment length) quiet wait after close. )等待足够的时间以确保远程TCP接收到连接中断请求的确认 CLOSED:(Connection is closed.)没有任何连接状态
服务器中存在大量
[root@es-node03 ~]# cat /proc/sys/net/ipv4/tcp_fin_timeout
2
#通过缩短时间 time walt时间来快速释放链接
vim /etc/sysctl.conf
net.ipv4.tcp_fin_timeout = 2DNS相关配置
/etc/hosts文件,优先级高于DNS解析
cat /etc/hosts
192.168.200.148 node1
192.168.200.149 node2
192.168.200.153 node3/etc/resolv.conf 注:在 centos5版本,配置dns用这个文件。在 centos6 7以后,直接在网卡配置文件中指定DNS1=192168.1.1
[root@es-node03 ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 172.18.16.1问:为什么hosts优先级高于dns
[root@es-node03 ~]# grep "hosts:" /etc/nsswitch.conf
#hosts: db files nisplus nis dns
hosts: files dns myhostname #files(/etc/hosts)放在了dns前面)系统路由信息
[root@es-node03 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.200.1 0.0.0.0 UG 0 0 0 ens160
表示任何网段 默认网关 所有主机添加删除路由条目
route add -net 192.168.300.0 netmask 255.255.255.0 dev ens161
网段 掩码 出接口
route del -net 192.168.300.0 netmask 255.255.255.0路由跟踪:查看经过多少三层设备的数量
[root@es-node03 ~]# traceroute 172.18.16.1
traceroute to 172.18.16.1 (172.18.16.1), 30 hops max, 60 byte packets
1 localhost (192.168.200.1) 22.189 ms 22.913 ms 23.730 ms
2 * * *ping命令
ping {ip addr}
- -c 数目 在发送指定数目的包后停止
- -i 秒数 设定间隔几秒送一个网络封包给一台机器,预设值是一秒送一次
- -I ens161 指定从哪个接口出去
arping -I ens160 192.168.200.1 #观察mac地址是否一样,一样则没有人冒充网关
ARPING 192.168.200.1 from 192.168.200.153 ens160
Unicast reply from 192.168.200.1 [E8:BD:D1:F6:6A:B3] 4.658ms
Unicast reply from 192.168.200.1 [E8:BD:D1:F6:6A:B3] 3.815ms
Unicast reply from 192.168.200.1 [E8:BD:D1:F6:6A:B3] 4.710mswatch命令
watch作用:实时监测命令的运行结果,可以看到所有变化数据包的大小
- -d,--differences #高亮显示指令输出信息不同之处;
- -n,--interval seconds #指定指令执行的间隔时间(秒)
例:每隔1秒高亮差异显示ens33相关信息
watch -d -n 1 ifconfig ens160
Every 1.0s: ifconfig ens160 Tue Jun 16 10:32:20 2020
ens160: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.200.153 netmask 255.255.255.0 broadcast 192.168.200.255
inet6 fe80::250:56ff:fe9d:b0b prefixlen 64 scopeid 0x20<link>
ether 00:50:56:9d:0b:0b txqueuelen 1000 (Ethernet)
RX packets 9665169 bytes 8799755781 (8.1 GiB)
RX errors 0 dropped 20 overruns 0 frame 0
TX packets 7473274 bytes 6814218750 (6.3 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0tcpdump抓包
tcpdump常用参数:
- -c 指定包个数
- -n ip,端口用数字方式显示
- -i 指定接口
- port 指定端口
[root@es-node03 ~]# tcpdump -n -c 30 port 22 -i ens160SYN洪水攻击
SYN洪水攻击主要源于: tcp协议的三次握手机制 SYN洪水攻击的过程:
- 在服务端返回一个确认的SYN-ACK包的时候有个潜在的弊端,如果发起的客户是一个不存在的客户端,那么服务端就不会接到客户端回应的ACK包。
- 这时服务端需要耗费一定的数量的系统内存来等待这个未决的连接,直到等待超关闭时间,才能施放内存。
- 如果恶意者通过通过ip欺骗,发送大量SYN包给受害者系统,导致服务端存在大量未决的连接并占用大量内存和tcp连接,从而导致正常客户端无法访问服务端,这就是SYN洪水攻击的过程。
使用awl伪装MAC对内网的服务器施实syn洪水攻击 awl下载地址:https://pincheng.lanzous.com/ij9dxdq3aqd
[root@es-node03 ~]# tar -xf awl-0.2.tar.gz
[root@es-node03 ~]# cd awl-0.2/
[root@es-node03 ~/awl-0.2]# ./configure && make -j 4 && make install
[root@es-node03 ~/awl-0.2]# which awl
/usr/local/bin/awl
[root@es-node03 ~/awl-0.2]# ping 192.168.200.153
PING 192.168.200.153 (192.168.200.153) 56(84) bytes of data.
64 bytes from 192.168.200.153: icmp_seq=1 ttl=64 time=0.322 ms
[root@es-node03 ~]# arp -n | grep 153
192.168.200.153 ether 00:50:56:9d:0b:0b C ens160
#获取目标主机mac地址awl 的格式如下: awl -i ens160 -m 00:50:56:9d:0b:0b -d 192.168.200.153 -p 80 参数如下:
- -i 发送包的接口,如果省略默认是eth0
- -m 被攻击机器的mac地址,程序不能根据被攻击IP得到MAC,需要手工指定.先ping 目标IP,再arp -a就可以看到. 如果省略则为ff:ff:ff:ff:ff:ff :这表示向同一网段內的所有主机发出ARP广播,进行SYN攻击,还容易使整个局域网瘫痪
- -d 被攻击机器的IP
- -p 被攻击机器的端口. 这里注意,手动指定-i参数很重要,比如我们的网卡是ens160,那就要指定 -i ens160,alvin的实测结果显示,不这样指定的时候,攻击无效。
[root@es-node03 ~]# netstat -na | grep "SYN_RECV"
tcp 0 0 192.168.200.153:80 218.149.245.64:17552 SYN_RECV
tcp 0 0 192.168.200.153:80 111.187.179.3:49721 SYN_RECV
tcp 0 0 192.168.200.153:80 59.171.38.91:26277 SYN_RECV
tcp 0 0 192.168.200.153:80 17.139.112.127:34437 SYN_RECV
...文件相关属性
[root@f felix]# ls -lih
total 8.0K
537327051 drwxr-xr-x 2 root root 6 2019-09-29 16:59 felix1
2385 - rw-r--r- - 1 root root 0 2019-09-30 11:00 felix10.txt
inode 文件类型 权限 SElinux 硬链接数 属主 属组 大小 修改时间 文件名索引节点inode&磁盘块Block
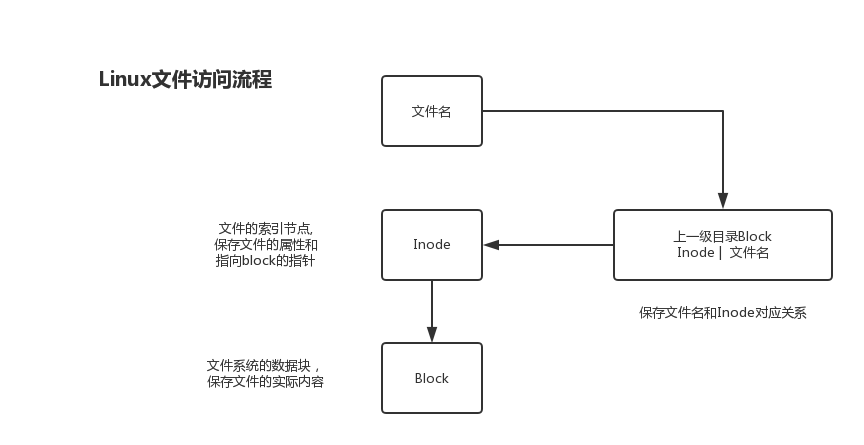
inode:
概念:索引节点的概念出在ext文件系统中(ext2 ext3 ext4),在磁盘进行格式化(建立文件系统)操作时,会生成大量的inode和block,找到一个文件最终都要通过索引节点inode才能找到(相当于书的目录)。
定义:类似于文件的身份证,索引节点是文件在系统中的唯一标识。索引节点是硬盘上的一块存储空间。大小256字节或512字节。
作用:索引节点里存放的数据是文件的属性(大小、时间、用户和组、权限等)唯独不包含文件名(文件名在上级目录的block里)。同时存放指向文件Block的指针(类似于软链接)。
特点:1.在ext3/ext4文件系统(C5/C6默认文件系统)下,一个非空文件至少要占用一个且只有一个Inode以及一个或多个Block。在文件系统进行初始化时,Block数量远大于inode数量。 2. Inode节点号相同的文件,互为硬链接文件,可以认为是一个文件的不同入口。 3. Inode在某一个文件系统(分区)内是唯一的。
Block:
作用:用来存放实际数据的实体单元(ext文件系统一般最大为4KB),即用来存放真实数据,例如:照片、视频等普通文件数据,单个大的文件需要占用多个Block块来存储,特别小的单个文件如果不能占满整个Block块,剩余的空间也无法再利用。
特点:
- 磁盘读取数据是按Block为单位存取的。
- 每读取一个Block就会消耗一次磁盘I/O
- 若文件比较大,一个文件可能占用多个Block。
- 若文件比较小,一个Block剩余空间会被浪费,无论内容有多小。
- block大小也是格式化时确定的,命令是 mkfs.ext4 -b 2048 -I 256 /dev/sdb。
inode&block管理:
查看Inodes数量:df -i
[root@f felix]# df -i
文件系统 总数 已使用 剩余 使用百分比 挂载点
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/vda3 207092736 99830 206992906 1% /查看Block数量:df -h
[root@f felix]# df -h
文件系统 大小 已使用 空闲 使用百分比 挂载点
Filesystem Size Used Avail Use% Mounted on
/dev/vda3 198G 4.3G 194G 3% /生产环境下排查硬盘满的原因及解法: 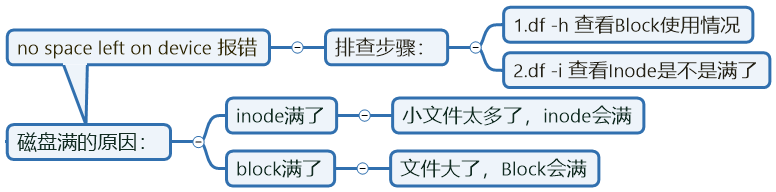
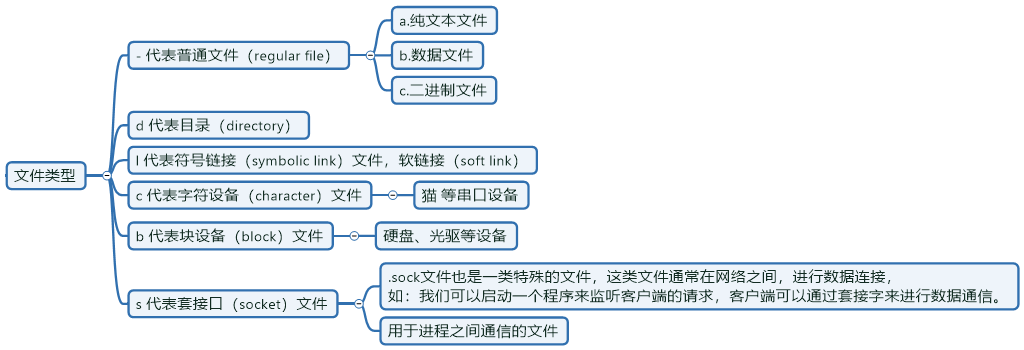
linux文件类型
文件权限机制
权限是操作系统用来限制对资源访问的机制,权限一般分为读、写、执行。系统中每个文件都拥有特定的权限、所属用户及所属组,通过这样的机制来限制哪些用户、哪些组可以对特定文件进行什么样的操作。 
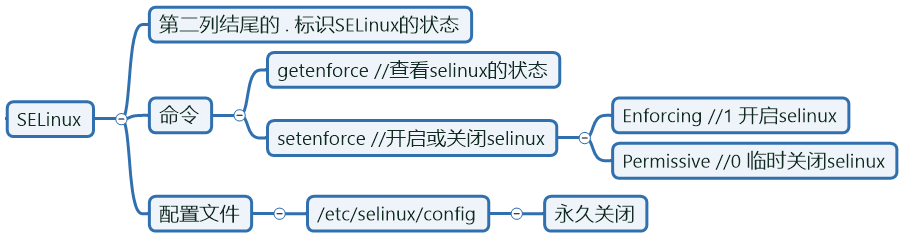
SELinux
Linux软硬链接
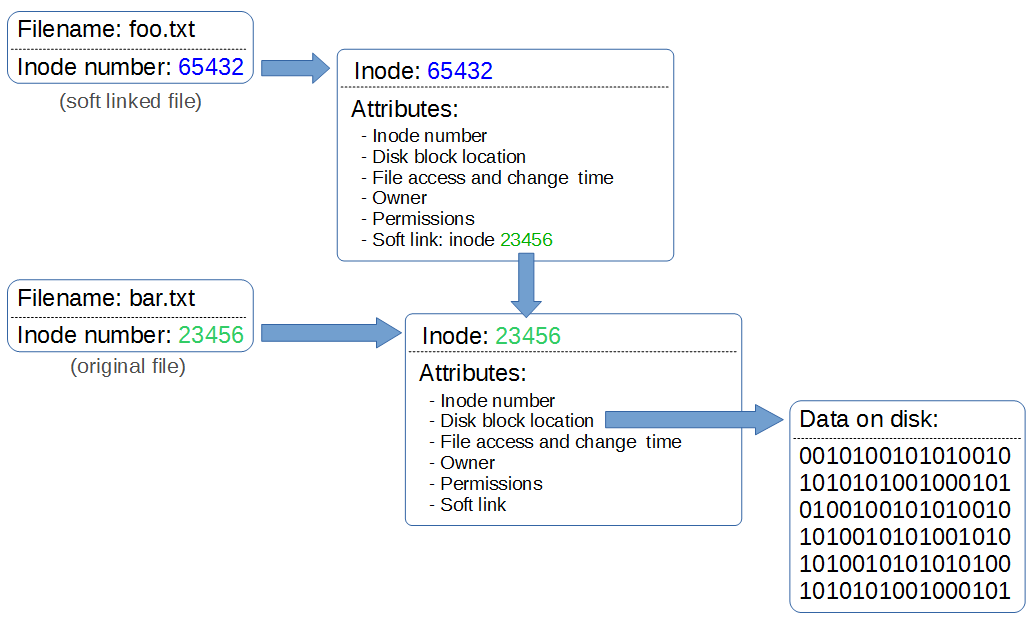 有关硬链接:
有关硬链接:
- 具有相同inode节点号的多个文件互为硬链接文件,相当于一个房间(文件)开了多个门(硬链接);
- 删除硬链接文件或者删除源文件任意之一,文件实体并未被删除;
- 只有删除了源文件和所有对应的硬链接文件,文件实体才会被删除;
- 硬链接文件是文件的另一个入口;
- 可以通过给文件设置硬链接文件来防止重要文件被误删(防删不防改,备份,防删又防改。);
- 创建硬链接命令 ln 源文件 硬链接文件;
- 硬链接文件是普通文件 -,可以用rm删除;
- 对于静态文件(没有进程正在调用),当硬链接数为0时文件就被删除。注意:如果有进程正在调用,则无法删除或者即使文件名被删除但空间不会释放。
- 目录/ 和 目录/.互为硬链接,目录/ 和 目录/子目录/.. 互为硬链接
硬链接扩展: cp 操作慢于 mv 命令 cp命令将源文件和cp出的新文件完全独立成了两个个体(即新文件改变了原本指向的inode和block)。 mv命令只是将文件名改了,并未重新指向新的inode和block。
有关软链接:
- 软链接类似windows系统的快捷方式;
- 软链接里面存放的是源文件的路径,指向源文件的文件名;
- 删除源文件,软链接依然存在,但无法访问源文件内容;
- 软链接失效时一般是白字红底闪烁;
- 创建软链接命令 ln -s 源文件 软链接文件;
- 软链接和源文件是不同的文件,文件类型也不同,inode号也不同;
- 软链接的文件类型是“l”,可以用rm删除。
软硬链接的区别:
- 原理上,硬链接和源文件的inode节点号相同,两者互为硬链接。软连接和源文件的inode节点号不同,进而指向的block也不同,软连接block中存放了源文件的路径名(文件名)。
- 实际上,硬链接和源文件是同一份文件,而软连接是独立的文件,类似于快捷方式,存储着源文件的位置信息便于指向。
- 使用限制上,不能对目录创建硬链接,不能对不同文件系统创建硬链接,不能对不存在的文件创建硬链接;可以对目录创建软连接,可以跨文件系统创建软连接,可以对不存在的文件创建软连接。
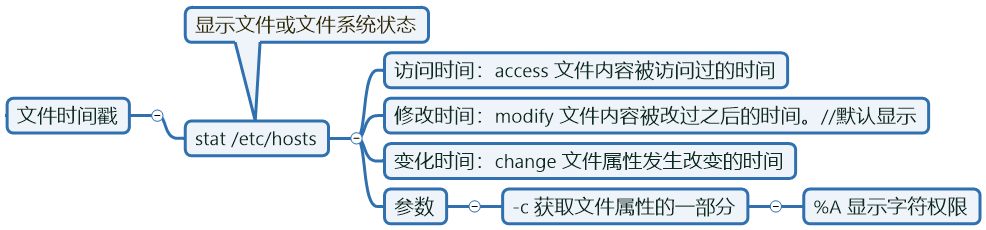
文件的时间戳
文件&目录权限
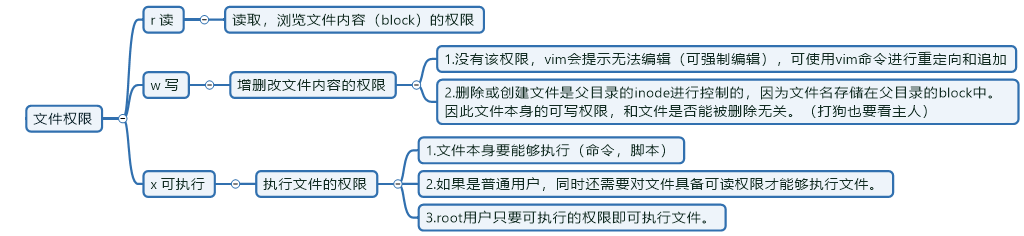

Linux基础权限 9个字符,分三组,三个字符一组:
2362 drwxr-xr-x 2 root root 6 2019-10-09 16:24 1.txtrwx r-x r-x 前3字符:用户(属主)权限位 中3字符:用户组(属组)权限位 后3字符:其他用户权限位
权限位置(UGO):rwx,读 4,写2,可执行1,- 0 可读r:表示读取、浏览文件内容(即读取文件实体block)的权限。 可写w:表示具有新增、修改、删除文件内容的权限。
- 如果没有可写w的配合,那么可以使用vim编辑文件时会提示无法编辑(但可以强制编辑),可以使用echo等命令进行重定向或追加。
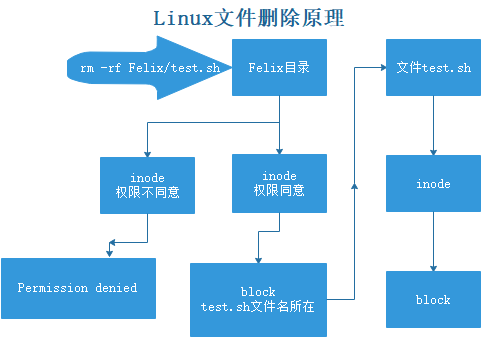
- 删除文件或创建文件的权限时受父目录(上一级目录)的权限控制的[因为文件名没有存放再Inode里),而是在上级目录的Block里存放着,若修改上级目录的Block(删除文件的本质),当然会受上级目录的Inode的权限控制],和文件本身的权限无关,因此,文件本身的可写w权限,和文件是否能被删除无关。(打狗也要看主人)
可执行x:具有执行文件的权限
- 文件本身要能够执行(命令,脚本)
- 如果是普通用户,同时还需要具备可读r的权限才能够执行文件。
- root用户只要有可执行x的权限即可执行文件
umask:控制默认权限
[root@es-node03 ~]# umask
0022文件: 创建文件默认最大的权限为666(-rw-rw-rw-),其默认创建的文件没有可执行权限x位。 默认权限-umask=实际权限 #对于文件当umask中存在奇数位的时候,在计算完毕后,奇数位加1
目录: 创建文件默认最大权限为777(rwxrwxrwx) 默认权限-umask=实际权限
特殊权限3位: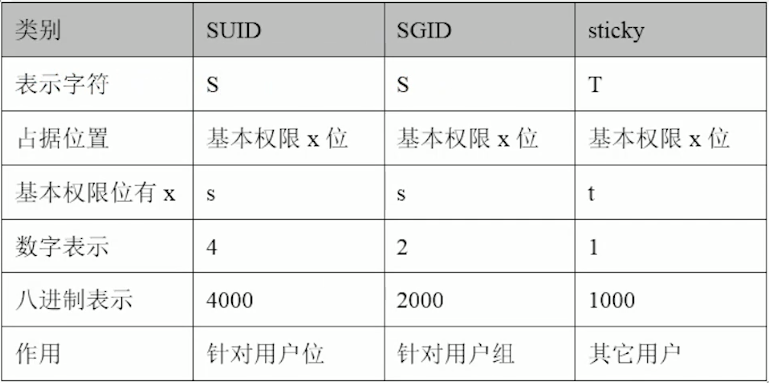
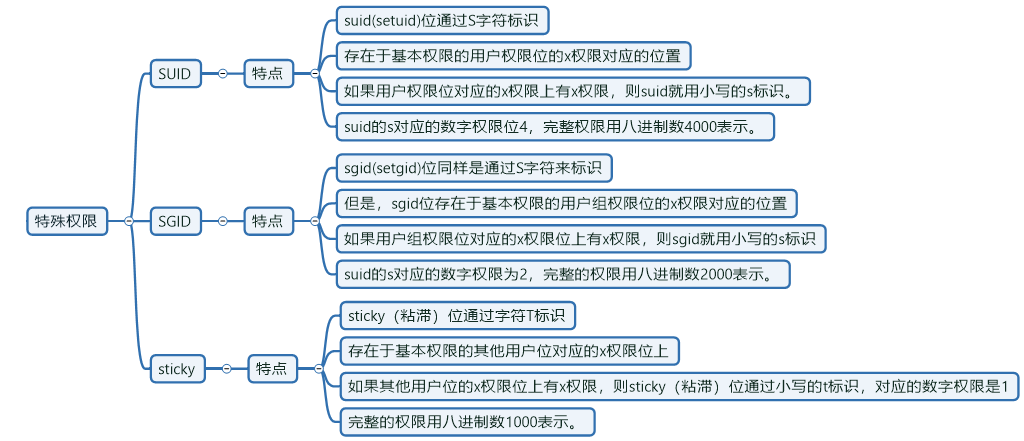
修改:放在基础权限数字的前面 [root@oldboyedu /oldboy]# chmod 7755 abc <==UGO中只要存在x权限,则特殊权限位(s,s,t)都为小写,反之则都为大写 所以结果:abc rwsr-sr-t
suid: SUID作用:suid的作用就是让普通用户可以在执行某个设置了suid位的命令或程序时,拥有和root管理员一样的身份和权限(默认情况)。 例如:passwd命令  任何人执行passwd这个命令,就会以passwd这个命令的属主(即 root)相同的权限来执行passwd。这就是suid的作用(尚方宝剑)
任何人执行passwd这个命令,就会以passwd这个命令的属主(即 root)相同的权限来执行passwd。这就是suid的作用(尚方宝剑)
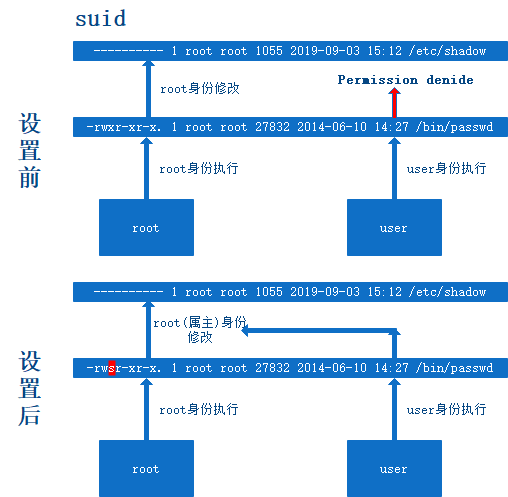
suid总结:
- suid功能时正对二进制命令或程序的,不能用在Shell等类型脚本文件上。
- 用户或属主对应的前三位权限的x位上,如果有s(S)就表示具备suid权限。
- suid的作用就是让普通用户可以在执行某个设置了suid位命令或程序时,拥有和root管理员一样的身份和权限(默认)。
- 二进制命令程序需要有可执行权限x配合才行。
- suid对应的身份和权限今在程序命令执行过程中有效。
- suid是一把双刃剑,是一个比较危险的功能,对系统安全有一定的威胁,企业里用户授权可以使用sudo等替代sgid功能。
- 在进行安全优化时,系统中默认设置了suid权限的命令要被取消掉。
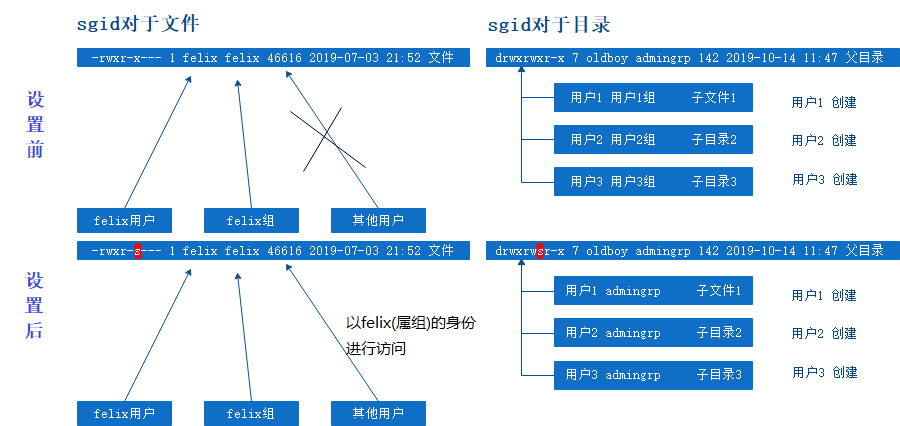
sgid: 对于二进制命令或者程序来说,sgid的功能和suid基本相同,唯一区别是suid是获得命令属主的身份和权限,而sgid则是获得命令属组的身份和权限。
sgid总结:
- 与suid不同的是,sgid既可以针对文件,亦可以针对目录。
- sgid的权限是针对用户组权限位的。
- 对于文件来说,sgid:
- sgid仅对二进制命令及程序有效。
- 二进制命令或程序,也需要有可执行权限x配合。
- 执行命令的任意用户可以获得该命令程序执行期间所属组的身份和权限。
- 对于目录来说,sgid:
- Linux里默认情况所有创建,默认用户和组都是自身。
- sgid可以让用户在此目录下创建的文件和目录具有和此目录相同的用户组设置
粘滞位: 文件夹权限全部打开,但是目录本身只能被属主或root删除。
文件属主,属组的特殊情况: 当文件或目录的用户或用户组被删除时,文件对应的属主和属组位置就会显示UID或GID。 修复方法:
useradd 用户名 -u UID
groupadd -g GID 组名生产环境应用
安全权限的临界点: 文件的安全临界点:644 目录的安全临界点:755
文件加解锁:
[root@S1 ~]# lsattr /etc/passwd
---------------- /etc/passwd
[root@S1 ~]# chattr +i /etc/passwd <==锁定文件,不给删除不给修改
[root@S1 ~]# lsattr /etc/passwd
----i----------- /etc/passwd
[root@S1 ~]# cp /etc/passwd{,.ori}
cp: overwrite ‘/etc/passwd.ori’? y
[root@S1 ~]# rm -rf /etc/passwd
rm: cannot remove ‘/etc/passwd’: Operation not permitted
[root@S1 ~]# echo ddd > /etc/passwd
-bash: /etc/passwd: Permission denied
[root@S1 ~]# touch felix.txt
[root@S1 ~]# chattr +a felix.txt <==可以追加内容,但不能删除。
[root@S1 ~]# lsattr felix.txt
-----a---------- felix.txt
[root@S1 ~]# echo 123 >> felix.txt
[root@S1 ~]# echo 123 >> felix.txt
[root@S1 ~]# echo 123 >> felix.txt
[root@S1 ~]# cat felix.txt
123
123
123
[root@S1 ~]# rm -rf felix.txt
rm: cannot remove ‘felix.txt’: Operation not permitted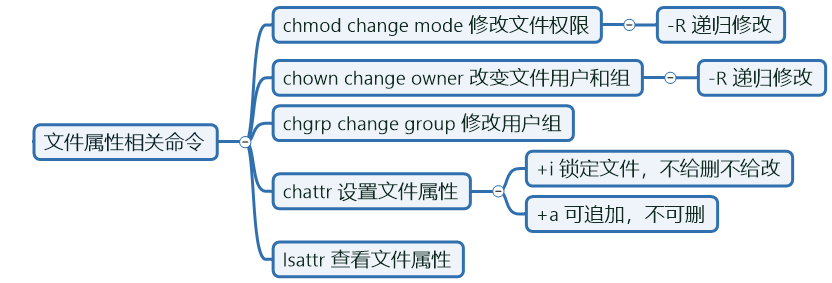
用户和用户组
用户,用户组,管理员之间的关系:
 UID
UID 
相关配置文件: /etc/passwd 存储当前系统中所有用户的信息  1.root用户编号固定为0 2.除了root用户外的其他用户,当用户被创建时,会在/home目录下为用户创建一个和用户名相同的目录作为这个用户的家目录。
1.root用户编号固定为0 2.除了root用户外的其他用户,当用户被创建时,会在/home目录下为用户创建一个和用户名相同的目录作为这个用户的家目录。
[root@lihuaning maildrop]# cat /etc/shells
/bin/sh
/bin/bash
/sbin/nologin
/usr/bin/sh
/usr/bin/bash
/usr/sbin/nologin
/bin/tcsh
/bin/csh
[root@lihuaning maildrop]# ls -l /bin/sh
lrwxrwxrwx. 1 root root 4 2019-07-12 22:48 /bin/sh -> bashbash是sh的扩展,sh是bash的软链接
/etc/shadow 存储当前系统中所有用户的密码信息,shadow配置文件的行数与passwd文件相同。 
添加用户: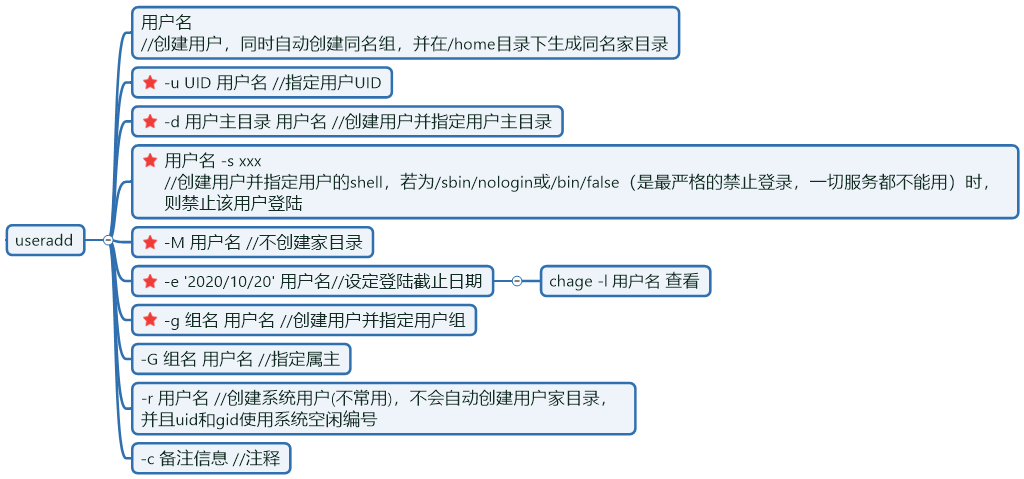
[root@lihuaning ~]# cat /etc/default/useradd <==useradd配置文件
# useradd defaults file
GROUP=100 <==依赖于/etc/login.defs 的USERGROUP_ENAB参数,如果no,则此处控制
HOME=/home <==定义默认家目录位置
INACTIVE=-1 <==用户是否启用过期停权,-1不启用
EXPIRE= <==用户终止日期,不设置代表不启用
SHELL=/bin/bash <==定义默认shell
SKEL=/etc/skel <==配置所有新用户家目录的默认环境变量文件存放路径,从该文件中复制过去,为每个用户提供用户环境变量的目录
[root@lihuaning ~]# ls -A /etc/skel/
.bash_logout .bash_profile .bashrc
CREATE_MAIL_SPOOL=yes <==创建mail文件
修改方法:
useradd -D 接参数改 或者直接编辑配置文件
示例:
在切到该用户后,提示符变为如下,是因为用户的环境变量缺失导致的。
[root@lihuaning xjh]# su xjh
bash-4.2$
解决:bash-4.2$ cp /etc/skel/.bash* .
若未生效:source .bash_logout .bashrc .bash_profile <==使环境变量生效
或者:
[root@lihuaning ~]# echo $PS1
[\u@\h \W]\$
bash-4.2$ export PS1='[\u@\h \W]\$' <==临时生效
[xjh@lihuaning root]$
logout 登出再登陆/etc/login.defs 是设置用户帐号限制的文件。该文件里的配置对root用户无效。如果/etc/shadow文件里有相同的选项,则以/etc/shadow里的设置为准,也就是说/etc/shadow的配置优先级高于/etc/login.defs
[root@felix ~]# cat /etc/login.defs
#
# Please note that the parameters in this configuration file control the
# behavior of the tools from the shadow-utils component. None of these
# tools uses the PAM mechanism, and the utilities that use PAM (such as the
# passwd command) should therefore be configured elsewhere. Refer to
# /etc/pam.d/system-auth for more information.
#
# *REQUIRED*
# Directory where mailboxes reside, _or_ name of file, relative to the
# home directory. If you _do_ define both, MAIL_DIR takes precedence.
# QMAIL_DIR is for Qmail
#
#QMAIL_DIR Maildir
MAIL_DIR /var/spool/mail <==创建用户时,要在目录/var/spool/mail中创建一个用户mail文件
#MAIL_FILE .mail
# Password aging controls:
#
# PASS_MAX_DAYS Maximum number of days a password may be used.
# PASS_MIN_DAYS Minimum number of days allowed between password changes.
# PASS_MIN_LEN Minimum acceptable password length.
# PASS_WARN_AGE Number of days warning given before a password expires.
#
PASS_MAX_DAYS 99999 <==密码最大有效期
PASS_MIN_DAYS 0 <==两次修改密码的最小间隔时间
PASS_MIN_LEN 5 <==密码最小长度,对于root无效
PASS_WARN_AGE 7 <==密码过期前多少天开始提示
#
# Min/max values for automatic uid selection in useradd
#创建用户时不指定UID的话自动UID的范围
UID_MIN 1000
UID_MAX 60000
# System accounts<==虚拟用户UID范围
SYS_UID_MIN 201
SYS_UID_MAX 999
#
# Min/max values for automatic gid selection in groupadd
#自动组ID的范围
GID_MIN 1000
GID_MAX 60000
# System accounts
SYS_GID_MIN 201
SYS_GID_MAX 999
#
# If defined, this command is run when removing a user.
# It should remove any at/cron/print jobs etc. owned by
# the user to be removed (passed as the first argument).
#
#USERDEL_CMD /usr/sbin/userdel_local <==当删除用户的时候执行的脚本,默认关闭
#
# If useradd should create home directories for users by default
# On RH systems, we do. This option is overridden with the -m flag on
# useradd command line.
#
CREATE_HOME yes <==是否创建家目录,可用-m控制
# The permission mask is initialized to this value. If not specified,
# the permission mask will be initialized to 022.
UMASK 077 <==家目录对对应的umask值
# This enables userdel to remove user groups if no members exist.
#
USERGROUPS_ENAB yes <==删除用户时,同时删除对应组。(如果组内没有其他成员)
# Use SHA512 to encrypt password.
ENCRYPT_METHOD SHA512 <==密码的加密算法SHA512
注意:
1.给开发人员等添加用户,尽量给截止时间。修改用户: 删除用户:
删除用户: 生产环境中一般先注释passwd中该用户的所属行,不立刻进行删除。
生产环境中一般先注释passwd中该用户的所属行,不立刻进行删除。
设置密码: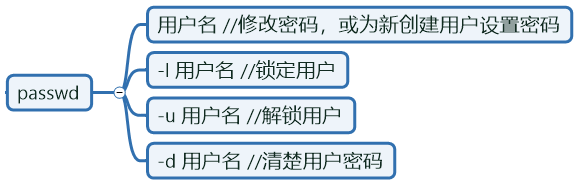
--stdin 从标准输入接受密码并设置
不交互设置密码: 方法1:
[root@oldboyedu ~]# echo 123456|passwd --stdin oldgirl
Changing password for user oldgirl.
passwd: all authentication tokens updated successfully.方法2:
[root@oldboyedu ~]# echo 123456 >pass
[root@oldboyedu ~]# cat pass
123456
[root@oldboyedu ~]# passwd --stdin oldgirl <pass
Changing password for user oldgirl.
passwd: all authentication tokens updated successfully.生产环境中密码管理思路:
- 用户密码要足够复杂,最好8位以上字母(含大小写)、数字、特殊字符的组合
- 较大的企业用户和密码可以统一管理(采用微软活动目录或 openldap开源工具)
- 动态密码:动态口令,需要时登录到动态口令系统中,即时申请获得密码,但如果若干时间内不操作服务器,密码就会失效

[root@oldboyedu ~]# tail -4 /etc/passwd|awk -F ":" '{print $1":oldboy"}' >user.log
[root@oldboyedu ~]# cat user.log
gongli1:oldboy
gongli2:oldboy
chenglong1:oldboy
zongsheng:oldboychpasswd对密码文件的要求是上述user.log
方法1:
[root@oldboyedu ~]# chpasswd<user.log方法2:
[root@oldboyedu ~]# tail -4 /etc/passwd|awk -F ":" '{print $1":oldboy"}'|chpasswd批量创建用户并设置密码:
[root@felix ~]# echo felix{01..10} | xargs -n1 | sed -rn 's#(.*)#useradd \1;echo 123456 | passwd --stdin \1#gp' | bash
# echo命令输出用户名 | xargs -n1 对输出的元素进行分组,每组一个元素 | 利用sed -n参数取消默认输出,-r参数支持ERE扩展元字符在这里指括号() 匹配所有,替换为 useradd \1取出所有已经分组的元素。此刻用户已经添加完毕;echo 123456 | passwd --stdin \1取出每位用户并从标准输入设置密码 接p打印结果。 | 将结果输出给bash
输出:
Changing password for user felix01.
passwd: all authentication tokens updated successfully.
Changing password for user felix02.
passwd: all authentication tokens updated successfully.
Changing password for user felix03.
passwd: all authentication tokens updated successfully.
Changing password for user felix04.
passwd: all authentication tokens updated successfully.
Changing password for user felix05.
passwd: all authentication tokens updated successfully.
Changing password for user felix06.
passwd: all authentication tokens updated successfully.
Changing password for user felix07.
passwd: all authentication tokens updated successfully.
Changing password for user felix08.
passwd: all authentication tokens updated successfully.
Changing password for user felix09.
passwd: all authentication tokens updated successfully.
Changing password for user felix10.
passwd: all authentication tokens updated successfully.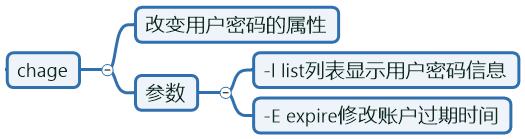
[root@felix ~]# chage -l felix01
Last password change : Oct 17, 2019 <==密码最近修改时间 2019-10-17 -d参数可控制该行
Password expires : never <==密码过期时间,从来不过期
-M参数控制该行
Password inactive : never <==密码停权时间
-l参数控制该行
Account expires : never <==账户过期时间
-E参数控制该行
Minimum number of days between password change : 0 <==修改密码最小间隔天数
-m参数控制该行
Maximum number of days between password change : 99999 <==最长时间
-M控制该行
Number of days of warning before password expires : 7 <==密码过去提前几天进行警告
-W控制该行
[root@felix ~]# chage -E "2020-10-1||$(date +%F -d'10day')" felix01 <==修改账户过期时间,或十天后停权
[root@felix ~]# chage -l felix01
Last password change : Oct 17, 2019
Password expires : never
Password inactive : never
Account expires : Oct 01, 2020 *
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7其他用户相关命令:
id #查看用户身份
whoami #查看当前用户
w #查看所以登陆用户
last #显示登陆过的用户信息列表
lastlog #汇报最近货指定用户的登录情况关于用户的骚操作:touch /etc/nologin 执行该命令会禁止除了root用户以外的其他用户登录服务器只要是创建该文件即可,应用场景比如服务器维护时需要暂时禁止普通用户登录。
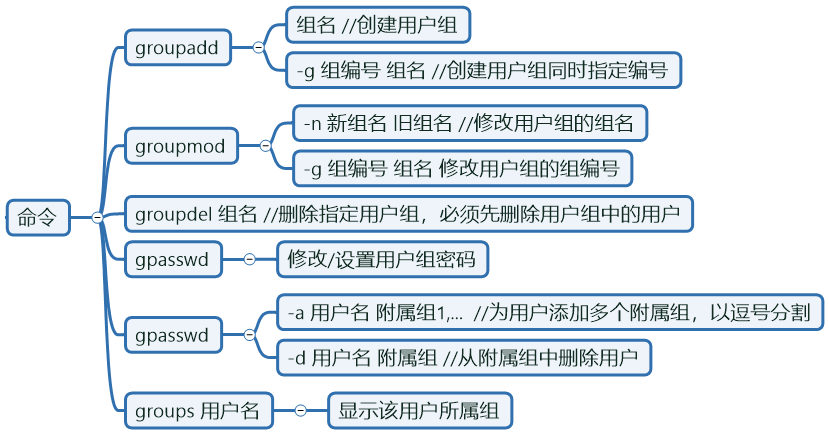
GID
 相关配置文件:
相关配置文件:/etc/group
用户身份切换su 
su 和 su -的区别 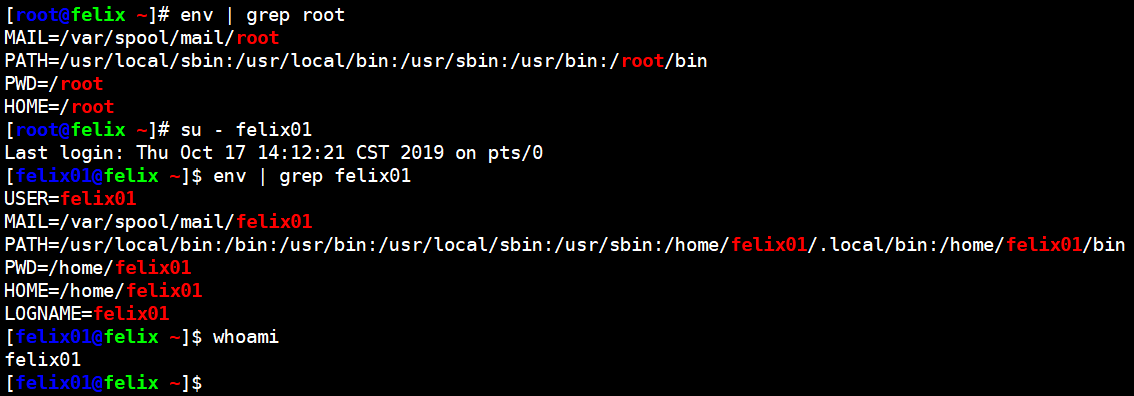 前者用户身份切换但环境变量没改变。
前者用户身份切换但环境变量没改变。
sudo命令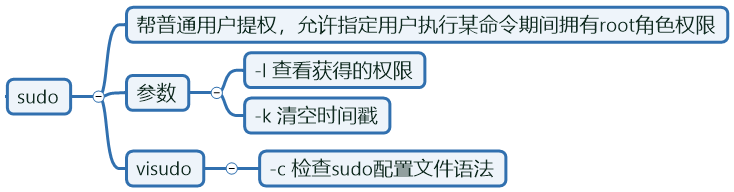
执行流程:
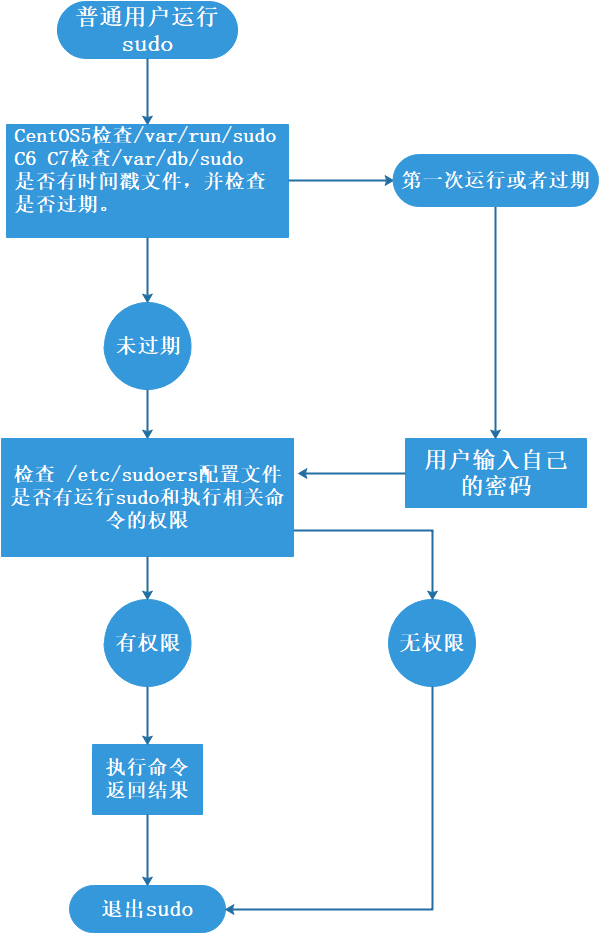 配置/ect/sudoers
配置/ect/sudoers
- visudo
- vim sudoers <==不推荐
[felix01@felix ~]$ ls /root
ls: cannot open directory /root: Permission denied
[root@felix ~]# visudo
97 ## Allow root to run any commands anywhere
98 root ALL=(ALL) ALL
99 felix01 ALL=(ALL) /bin/ls,/bin/cp
用户 主机=(角色) 命令(全路径 which),多个命令用,隔开
99 felix ALL=(ALL) ALL //相当于felix设置成管理员
99 felix ALL=(ALL) NOPASSWD: ALL //sudo去密码
[root@felix ~]# sudo su -
Last login: Thu Oct 17 15:30:38 CST 2019 from 10.93.151.253 on pts/0
[root@felix ~]#
禁止root远程连接
[root@felix ~]# ll /var/db/sudo/felix/1 <==密码过期时间戳文件,默认5分钟过期
-rw------- 1 root felix 48 2019-10-17 16:25 /var/db/sudo/felix/1
[felix@felix ~]$ sudo -k <==清除时间戳,使sudo提示输入密码
[felix@felix ~]$ sudo ls /root
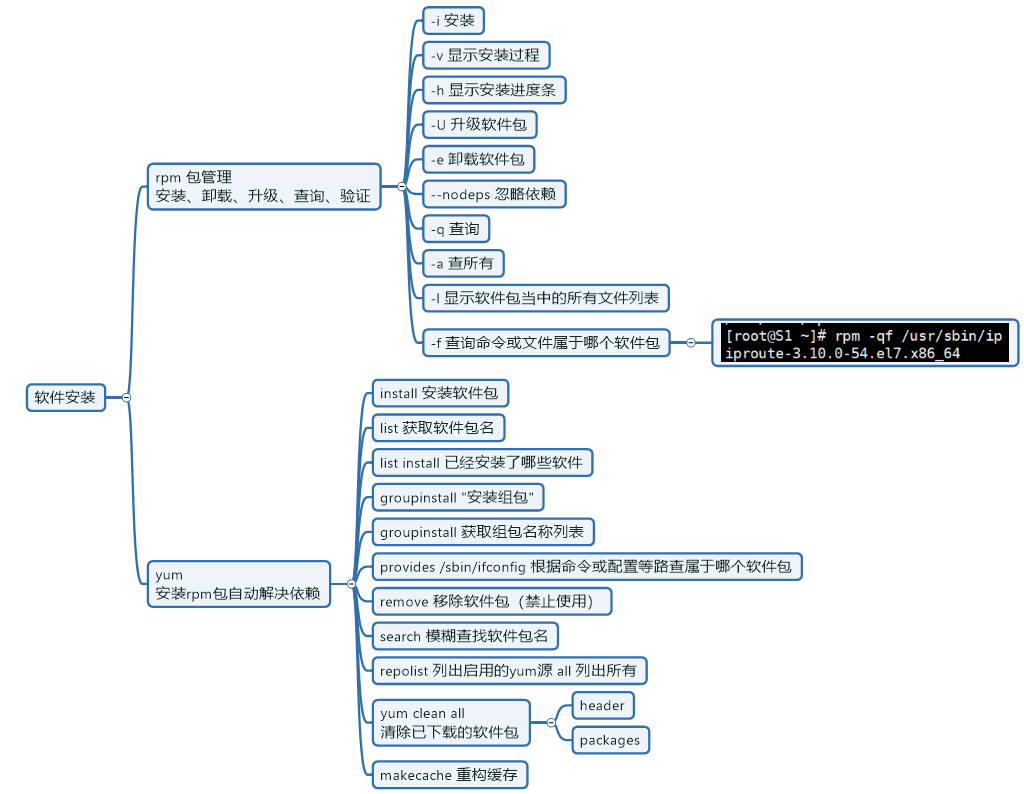
[sudo] password for felix:RPM/YUM软件安装相关
特殊字符/SHELL相关
特殊字符
基本含义:通配符简单说就是键盘上的一些特殊字符,可以实现某些特殊的功能。 **例如:**可以用*代表所有,来模糊搜索系统中的文件。 **作用:**通配符适用范围是命令行中的[普通命令]或脚本编程中。
第一组:模糊匹配 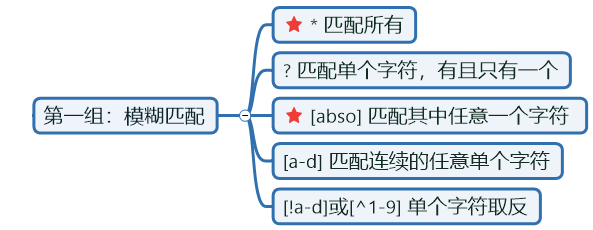
第二组:路径位置 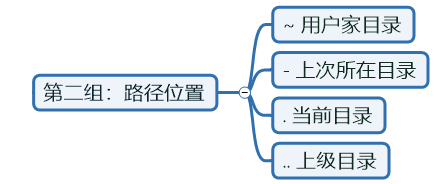
第三组:引号相关  坑:反引号解析出命令结果能被够一个命令调用,而双引号不行。
坑:反引号解析出命令结果能被够一个命令调用,而双引号不行。
[root@lihuaning ~]# tar -czf felix_$(date +%F).tar.gz felix <==打包文件时通过$()解析命令给文件加上日期
[root@lihuaning ~]# ls
felix_2019-10-09.tar.gz第四组:其他字符 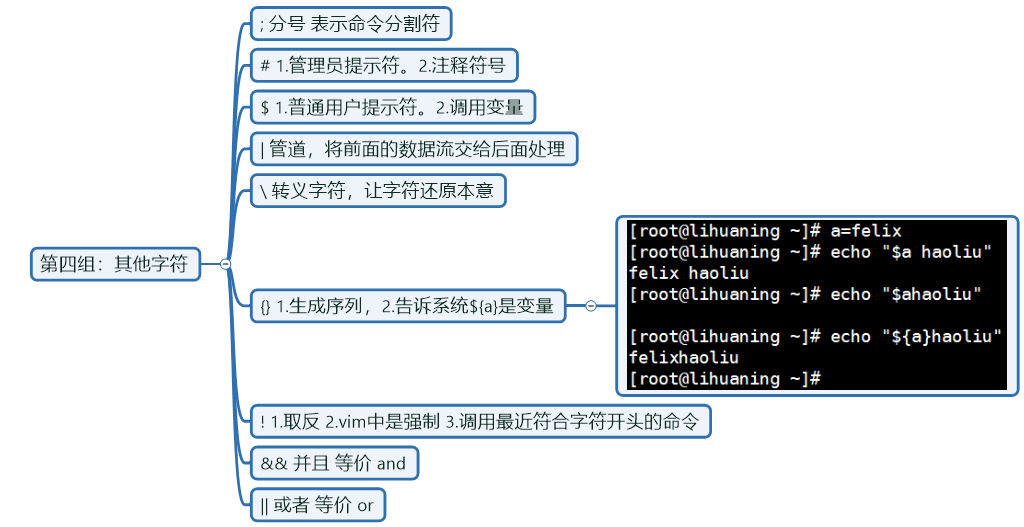
管道重定向
重定向
- 1> 标准输出重定向 箭头方向就是数据流向,把左边的数据流向到右边,会覆盖之前的数据
- 1>> 追加输出重定向,内容追加到文件尾部
- 0< 标准输入重定向 箭头方向就是数据流向,把右边的数据流向到右边,会覆盖之前的数据
- 0<< 追加输入重定向,内容追加到文件尾部(可配合EOF)
- 2> 错误输出重定向,箭头方向就是数据流向,把左边的报错输出到右边(覆盖)
- 2>> 错误追加输出重定向(追加)
- <<< 将后面的内容作为前面命令的标准输入,用于处理变量
特殊的重定向 将标准错误重定向到标准输出,即标准错误和标准输出一样重定向到文件中的三种方法
- 方法1:
echo “I am felix” 1>>felix.txt 2>>felix.txt - 方法2:
echo “I am felix” &>>felix.txt - 方法3:
echo “I am felix” >>felix 2>&12>&1的意思就是将 标准错误输出和标准输出等价进行重定向
管道 定义:管道左边的命令的执行结果,通过管道交给右边命令进行再处理。 [root@f ~]# cat anaconda-ks.cfg | grep "kexec" //没有实际意义 正确方法如下: [root@f ~]# grep "kexec" anaconda-ks.cfg //少钻管道,提高效率
示例
[root@f felix]# find ./ -name "felix*" -type f -mtime -3 -exec ls -l {} \;
[root@f felix]# find ./ -name "felix*" -type f -mtime -7 | xargs ls -l
[root@f felix]# find ./ -name "felix*" -type f | xargs rm -rfLinux正则
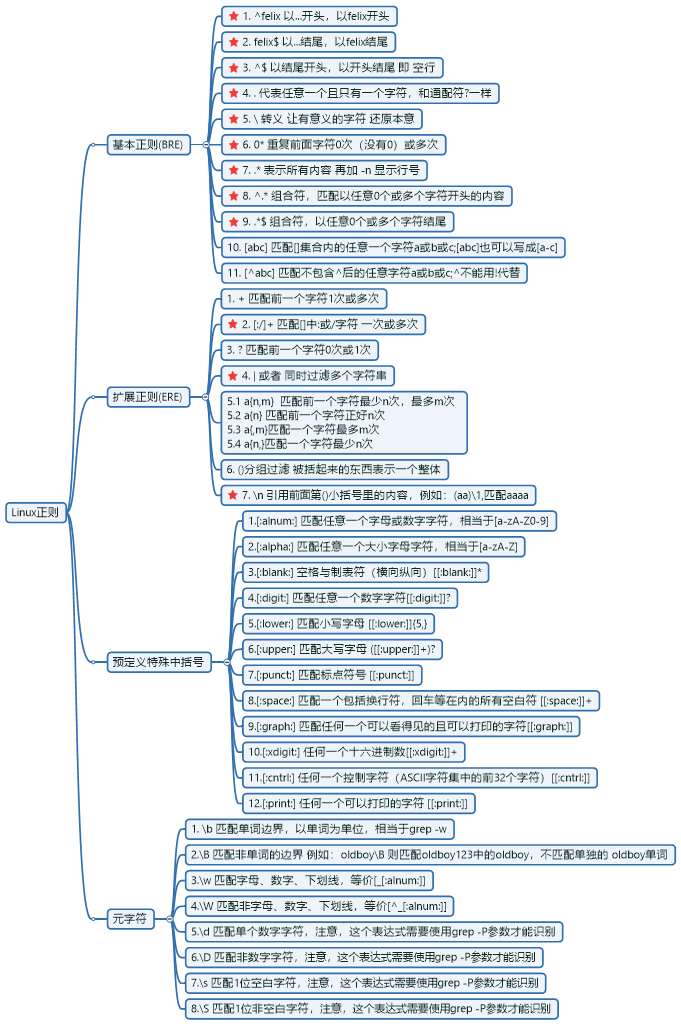 **概念:**作用和特殊字符一样,是为处理大量字符串及文本而定义的一套规则和方法,化繁为简。假设“@”代表“I am”,“!”代表“felix”,则执行。echo “@!”的结果就是输出“I am felix”。 **作用:**提高效率,快速获取到想要的内容。适用于三剑客命令 grep(egrep),sed,awk。以行为单位进行处理。
**概念:**作用和特殊字符一样,是为处理大量字符串及文本而定义的一套规则和方法,化繁为简。假设“@”代表“I am”,“!”代表“felix”,则执行。echo “@!”的结果就是输出“I am felix”。 **作用:**提高效率,快速获取到想要的内容。适用于三剑客命令 grep(egrep),sed,awk。以行为单位进行处理。
[root@lihuaning ~]# ifconfig ens3|sed -rn '2s#^.*inet (.*) net.*$#\1#gp'
10.93.169.253易混淆的事项:
- 和通配符区别
- 开发正则,一般是Perl兼容正则表达式
- Linux系统的三剑客正则表达式*
环境准备:
alias grep='grep --color=auto' <==C6需要单独设置
[root@lihuaning ~]# export LC_ALL=C <==设置后,匹配操作不会出现匹配异常情况
操作:
cat >>/etc/profile<<EOF
alias grep='grep --color=auto'
alias egrep='egrep --color=auto'
export LC_ALL=C
EOF
source /etc/profile <==使修改内容生效分类:
- BRE(基本正则表达式) grep
- ERE(扩展正则表达式) egrep
BRE
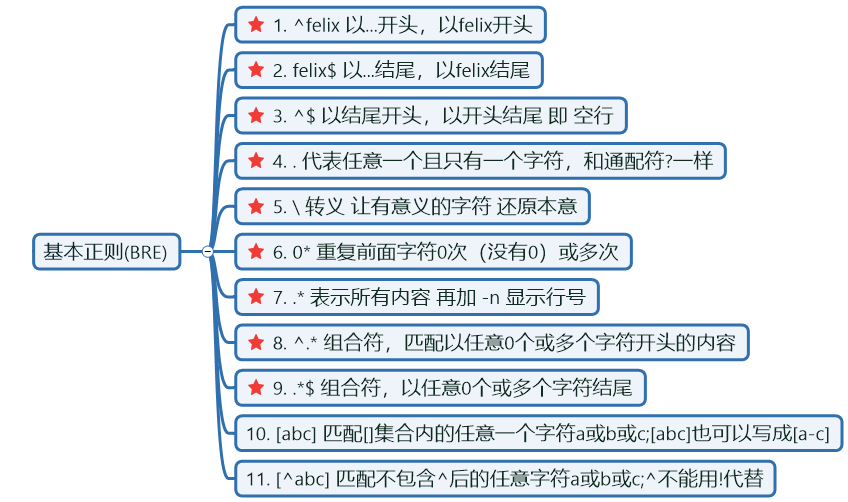 BRE实践:
BRE实践:
- ^以...开头的行
[root@lihuaning felix]# cat test.txt <==环境准别
I am oldboy teacher!
i teach linux
I like badminton ball billiard ball and chinese chess
oursiteishttp://www.oldboyedu.com
my qq num is 49000448
not49000e448.
my god ,i am not oldbey, but OLDBOY
[root@lihuaning felix]# grep "^n" test.txt <==匹配以n开头的行
not49000e448.
过滤文件类型操作
[root@lihuaning felix]# ll
total 4
drwxr-xr-x 2 root root 6 2019-10-09 16:24 1.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:24 2.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:24 3.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:24 4.txt
-rw-r--r-- 1 root root 0 2019-10-09 16:24 a.txt
-rw-r--r-- 1 root root 0 2019-10-09 16:24 b.txt
-rw-r--r-- 1 root root 0 2019-10-09 16:24 c.txt
-rw-r--r-- 1 root root 0 2019-10-09 16:24 d.txt
-rw-r--r-- 1 root root 0 2019-10-09 18:19 est.txt
-rw-r--r-- 1 root root 195 2019-10-09 22:01 test.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:23 text
[root@lihuaning felix]# ll | grep "^d" <==过滤以d开头的文件,即过滤目录
drwxr-xr-x 2 root root 6 2019-10-09 16:24 1.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:24 2.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:24 3.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:24 4.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:23 text- $以..结尾的行
[root@lihuaning felix]# grep -n "m$" test.txt <==匹配以m结尾的行
4:oursiteishttp://www.oldboyedu.com
[root@lihuaning felix]# grep -n "\!$" test.txt <==匹配以!结尾的行,\ 表示转义
1:I am oldboy teacher!
过滤目录操作
[root@lihuaning felix]# ll -F <==给目录后面加上反斜线
total 4
drwxr-xr-x 2 root root 6 2019-10-09 16:24 1.txt/
drwxr-xr-x 2 root root 6 2019-10-09 16:24 2.txt/
drwxr-xr-x 2 root root 6 2019-10-09 16:24 3.txt/
drwxr-xr-x 2 root root 6 2019-10-09 16:24 4.txt/
-rw-r--r-- 1 root root 0 2019-10-09 16:24 a.txt
-rw-r--r-- 1 root root 0 2019-10-09 16:24 b.txt
-rw-r--r-- 1 root root 0 2019-10-09 16:24 c.txt
-rw-r--r-- 1 root root 0 2019-10-09 16:24 d.txt
-rw-r--r-- 1 root root 0 2019-10-09 18:19 est.txt
-rw-r--r-- 1 root root 195 2019-10-09 22:01 test.txt
drwxr-xr-x 2 root root 6 2019-10-09 16:23 text/
[root@lihuaning felix]# ll -F | grep "/$" <==通过匹配以反斜线结尾的文件 找出目录
drwxr-xr-x 2 root root 6 2019-10-09 16:24 1.txt/
drwxr-xr-x 2 root root 6 2019-10-09 16:24 2.txt/
drwxr-xr-x 2 root root 6 2019-10-09 16:24 3.txt/
drwxr-xr-x 2 root root 6 2019-10-09 16:24 4.txt/
drwxr-xr-x 2 root root 6 2019-10-09 16:23 text/- ^$ 过滤空行
[root@lihuaning felix]# grep -n "^$" test.txt <==匹配空行
4:
7:
[root@lihuaning felix]# grep -nv "^$" test.txt <==通过-v参数取反输出,则去除了文件的空行
1:I am oldboy teacher!
2:i teach linux
3:I like badminton ball billiard ball and chinese chess
5:oursiteishttp://www.oldboyedu.com
6:my qq num is 49000448
8:not49000e448.
9:my god ,i am not oldbey, but OLDBOY- . 表示匹配任意一个字符,有且只有一个。类似于通配符中的 ?
[root@lihuaning felix]# grep "." test.txt <==匹配到了任意字符,所有字符都匹配上了
I am oldboy teacher!
i teach linux
I like badminton ball billiard ball and chinese chess
oursiteishttp://www.oldboyedu.com
my qq num is 49000448
not49000e448.
my god ,i am not oldbey, but OLDBOY- \ 表示转义
[root@lihuaning felix]# grep ".$" test.txt <==匹配以任意字符结尾的行
I am oldboy teacher!
i teach linux
I like badminton ball billiard ball and chinese chess
oursiteishttp://www.oldboyedu.com
my qq num is 49000448
not49000e448.
my god ,i am not oldbey, but OLDBOY
[root@lihuaning felix]# grep "\.$" test.txt <==转意后 匹配以点结尾的行
not49000e448.- * 表示重复前面字符 0次或多次
[root@lihuaning felix]# grep "0*" test.txt <==由于*表示匹配0次或多次,所以文件未匹配上的(即0次)也一并输出了
I am oldboy teacher!
i teach linux
I like badminton ball billiard ball and chinese chess
oursiteishttp://www.oldboyedu.com
my qq num is 49000448
not49000e448.
my god ,i am not oldbey, but OLDBOY- .*包含空行在内的所有行,加上-n参数显示所有行的行号 等价于cat -n
[root@lihuaning felix]# grep -n ".*" test.txt
1:I am oldboy teacher!
2:i teach linux
3:I like badminton ball billiard ball and chinese chess
4:
5:oursiteishttp://www.oldboyedu.com
6:my qq num is 49000448
7:
8:not49000e448.
9:my god ,i am not oldbey, but OLDBOY- ^.* 表示匹配以任意多个字符开头的行
[root@lihuaning ~]# grep "^.*boy" felix/test.txt <==匹配以任意字符开头 以boy结尾的行。相当于通配符里的 *boy
I am oldboy teacher!
oursiteishttp://www.oldboyedu.com- .*$ 表示匹配以任意多个字符结尾的行
[root@lihuaning ~]# grep "am.*$" felix/test.txt <==匹配以任意字符结尾但开头是am 的行
I am oldboy teacher!
my god ,i am not oldbey, but OLDBOY- [abc]匹配带有 或a或b或c任意一个的行
[root@lihuaning ~]# grep "[qg]" felix/test.txt <==匹配带有q 或者 g的行 ^不能用感叹号替换(会被当做字符)
my qq num is 49000448
my god ,i am not oldbey, but OLDBOY- [^abc]取反
[root@lihuaning ~]# grep "[^qg]" felix/test.txt <==取反 或q或g
I am oldboy teacher!
i teach linux
I like badminton ball billiard ball and chinese chess
oursiteishttp://www.oldboyedu.com
my qq num is 49000448
not49000e448.
my god ,i am not oldbey, but OLDBOYERE
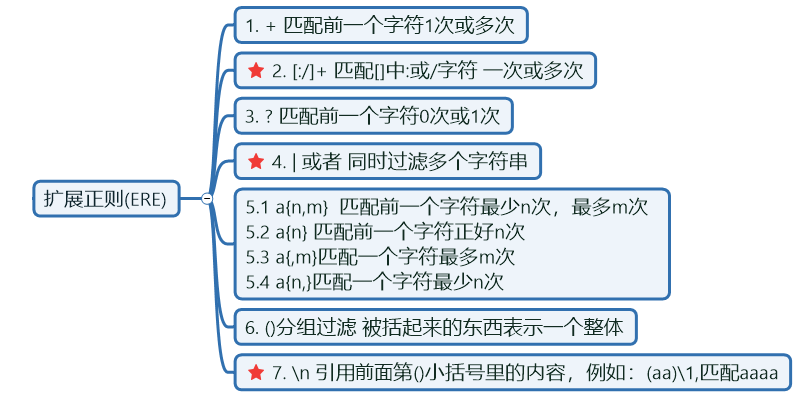
- +匹配前一个字符一次或多次。贪婪模式,尽量往后匹配。
- [字符1字符2] 匹配[]中的字符或l或x 一次或多次
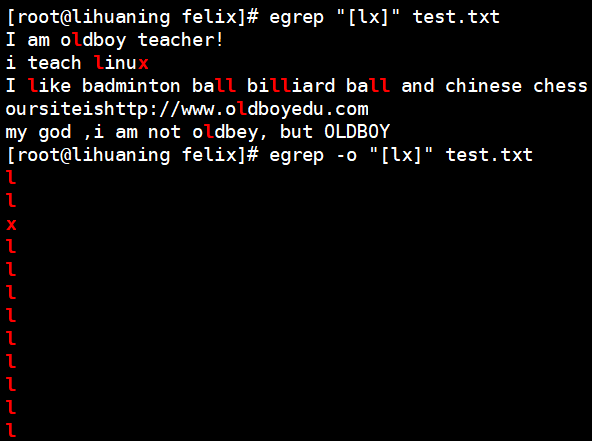
- ? 匹配前一个字符0次或1次。
?和*的区别
es? 0-1次
e
es
es* 0-n次
e
es
ess
essssss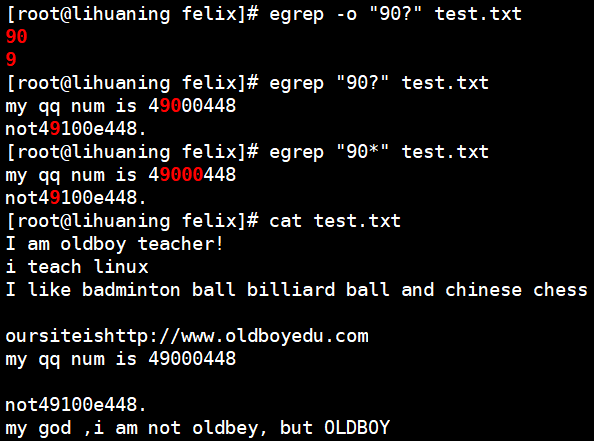
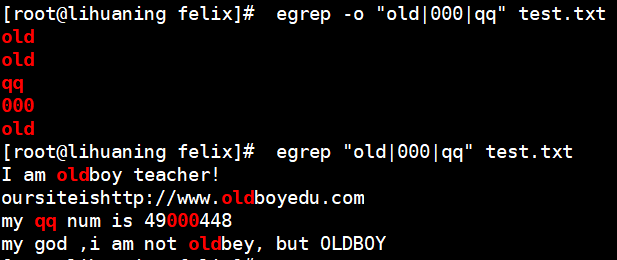
- | 或者 同时过滤多个字符串
- 元字符
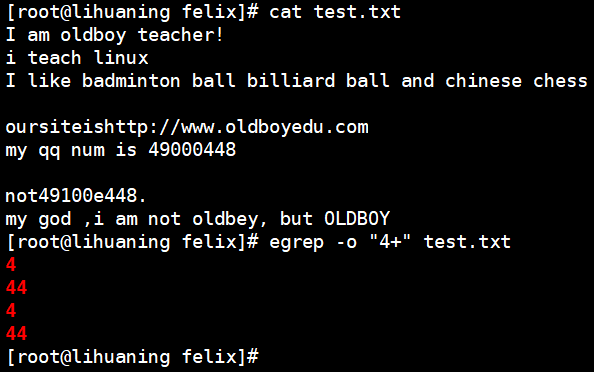
egrep -o "(0)(0)\1\2" test.txt 等价于 egrep -o "0000" test.txt

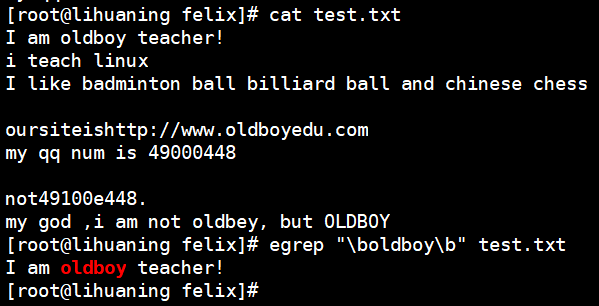
- \b 匹配单词边界 类似grep -w
- \B 非单词边界匹配,即不匹配独立单词,而匹配非独立的单词
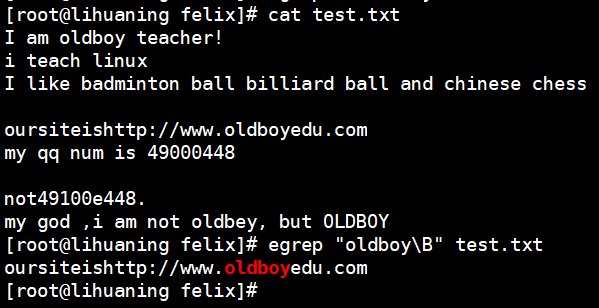
- \d 匹配单个数字,需要配合grep -P Perl语言的正则

Linux四剑客
- grep 过滤查找内容
- sed 取行,替换,删除,追加
- awk 取列
- find 查找文件
awk
sed -n '1,5p' /etc/passwd > a.txt <==用sed取出1-5行,重定向到a.txt 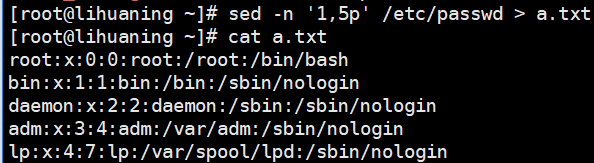
awk -F ":" '{print $1}' a.txt <==指定分隔符后,{}中接动作 print 打印 $1表示第一列 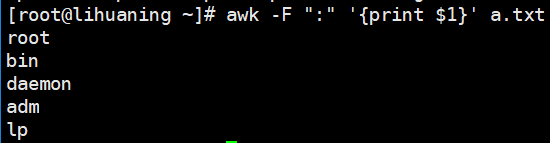 同上:逗号表示打印$1和$5,打印出的内容默认以空格分割。
同上:逗号表示打印$1和$5,打印出的内容默认以空格分割。 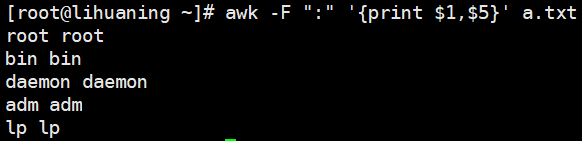 $1代表第一列,$2代表第二列,$0代表整行,$NF代表最后一列
$1代表第一列,$2代表第二列,$0代表整行,$NF代表最后一列 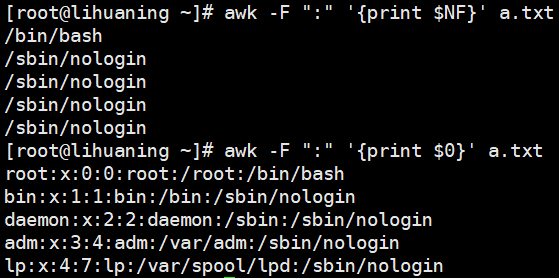
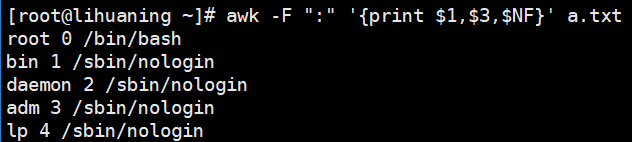
awk案例1 打印1,3,最后一列
打印倒数第2列
awk -F ":" '{print $1,$3,$(NF-1)}' a.txt<==$(NF-1)代表倒数第二列
 打印倒数第2列
打印倒数第2列 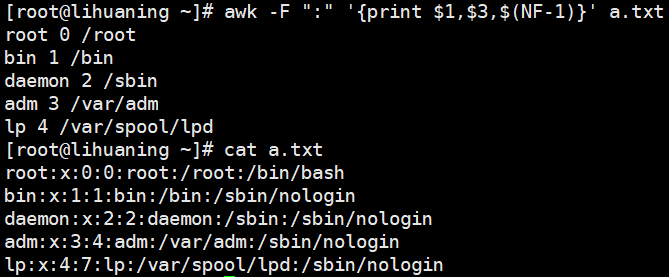
awk案例2
awk 'NR>1&&NR<4' a.txt<==NR大于1(即从2开始)and NR小于4(即到3结束)结果取出2 3行,and取交集awk 'NR==2,NR==3' a.txt<==NR等于2 NR等于3 即取出2 3行
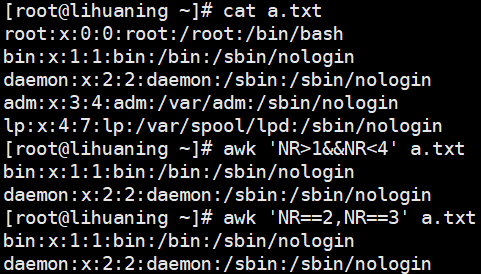
awk案例3
awk '/root/' a.txt<==过滤只含root的行
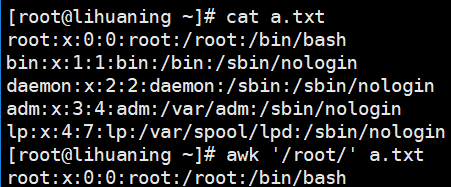
awk案例4 awk过滤非 指定字符串的行
awk '/^[^r]/' a.txt<==[]中 ^r 是指非r(取反操作),括号外的^以什么什么开头,这里指过滤出以非r开头的行
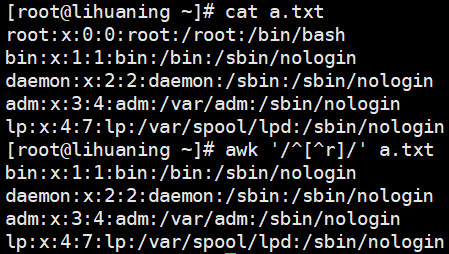
awk案例5 awk取文件的第一列,第三列,最后一列并打印行号
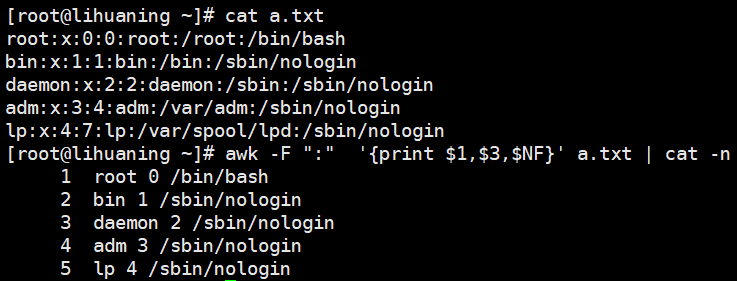
awk -F ":" '{print $1,$3,$NF}' a.txt | cat -nawk -F ":" '{print NR,$1,$3,$NF}' a.txt<==取第行号(NR),第一列($1),第二列($3),最后一列(NF)
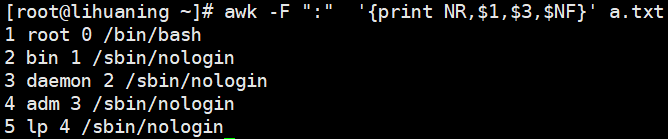
awk案例6 awk取ifconfig ens3的IP地址
ifconfig ens3 | awk -F " " 'NR==2{print $2}'<==-F指定分割符,NR定位到行号2,取出指定列$2ifconfig ens3 | awk 'NR==2{print $2}'<==同上,缺少-F(因为不指定-F即默认以空格作为分割符)
多分隔符概念:
echo --==--==--====-1.........2[[[[[[[3******4%%%%%%%5 | awk -F "[-=.[*%]+" '{print $3,$4}'<==-F参数指定分割符[]+,指的是将一堆括号内的符号看作一个分隔符,分隔符的左右两边分别是$n 和 $n+1 输出:2 3
awk案例7 过滤文件中第一列内容匹配root的字符串,把符合的行的最后一列输出
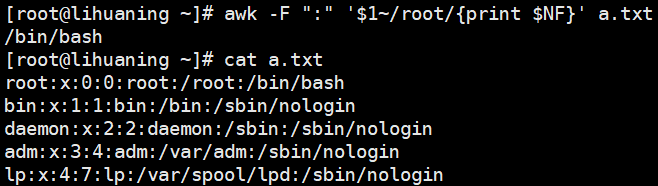
awk -F ":" '$1~/root/{print $NF}' a.txt<==第一列($1) 匹配到(~) root,就把匹配到的这一行的最后一列打印出来
awk案例8
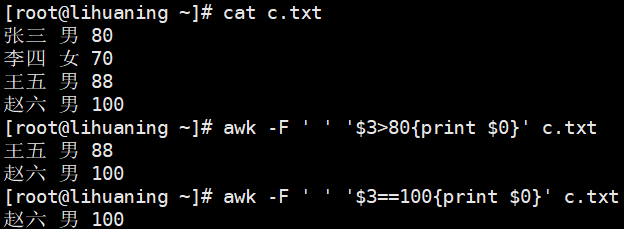
awk -F ' ' '$3>80{print $0}' c.txt<==分数大于80的awk -F ' ' '$3==100{print $0}' c.txt<==分数等于100的
awk练习
[root@lihuaning ~]# cat a.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin问题1:取test.txt文件的第2行到第3行的内容。
[root@lihuaning ~]# awk -F ":" 'NR==2,NR==3{print $0}' a.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin问题2:过滤出含有root字符串的行※。
[root@lihuaning ~]# awk -F ":" '$1~/root/{print $0}' a.txt
root:x:0:0:root:/root:/bin/bash问题3:删除含有root字符串的行※。
[root@lihuaning ~]# awk -F ":" '$1~/[^root]/{print $0}' a.txt
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin问题4:取文件的第一列、第三列和最后一列内容,并打印行号※。
[root@lihuaning ~]# awk -F ":" '{print NR,$1,$3,$NF}' a.txt
1 root 0 /bin/bash
2 bin 1 /sbin/nologin
3 daemon 2 /sbin/nologin
4 adm 3 /sbin/nologin
5 lp 4 /sbin/nologin问题5:取出Linux中执行ifconfig eth0后对应的IP地址(只能输出IP地址)。
[root@lihuaning ~]# ifconfig ens3 | awk -F " " 'NR==2{print $2}'
10.93.169.253问题6:过滤文件中第一列内容匹配root的字符串,把符合的行的最后一列输出
[root@lihuaning ~]# awk -F ":" '$1~/root/{print $NF}' a.txt
/bin/bash问题7:过滤下列test1.txt文件中第三列内容分数大于70,并且小于95的人名和性别。
[root@lihuaning ~]# cat c.txt
张三 男 80
李四 女 70
王五 男 88
赵六 男 100
[root@lihuaning ~]# awk -F " " '$3>70&&$3<95{print $1,$2}' c.txt
张三 男
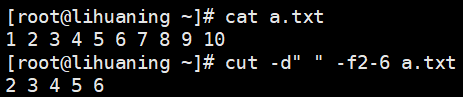
王五 男cut命令: 简单取列
cut -d" " -f2-6 a.txt<==-d指定分隔符,-f指定取第几列。也可用逗号,单个字符提取cut -c7-,1-5 felixis.txt<==取第7个字符到结尾,再取1-5五个字符

sed
复杂语法:
'$' 文件最后一行,
'!' 不进行
'N' 读入下一行并加入缓存尾;
';' 语句分隔
'/' 查找(起始)
'\n' 换行符(转意写法)
'Number' Number(字符序列)
'/' (查找结束)
'P' 输出缓存中顺序第一字符到’\n'之间的字符序列
'D' 删除缓存中顺序第一字符到’\n'之间的字符序列
sed '/abc/d;/efg/d' a.txt > a.log 删除abc或efg的行
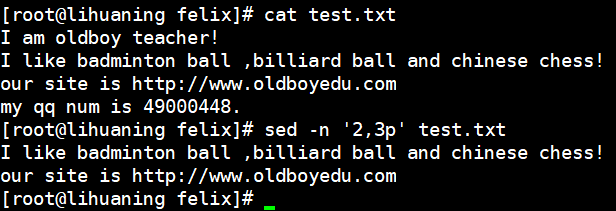
其中,"abc"也可以用正则表达式来代替sed案例1: 打印二到三行
sed -n '2,3p' test.txt<==取消默认输出
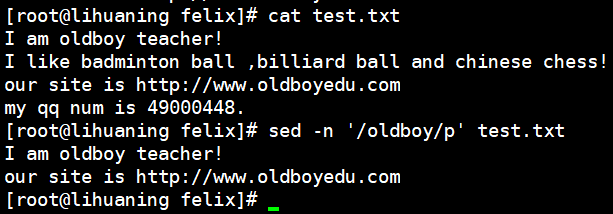
sed案例2: 过滤出含有oldboy字符串的行※
sed -n '/oldboy/p' test.txt
sed案例3: 删除含有oldboy字符串的行※
sed '/oldboy/d' test.txt<==未更改源文件sed '2d' test.txt<==删除第二行 加-i写入文件;也可 '5,8d' 删除5-8行
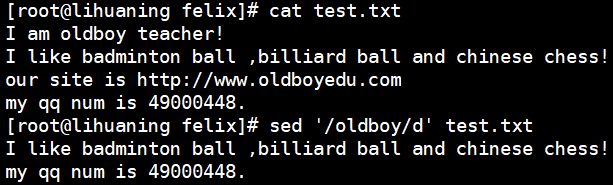 按行删除
按行删除 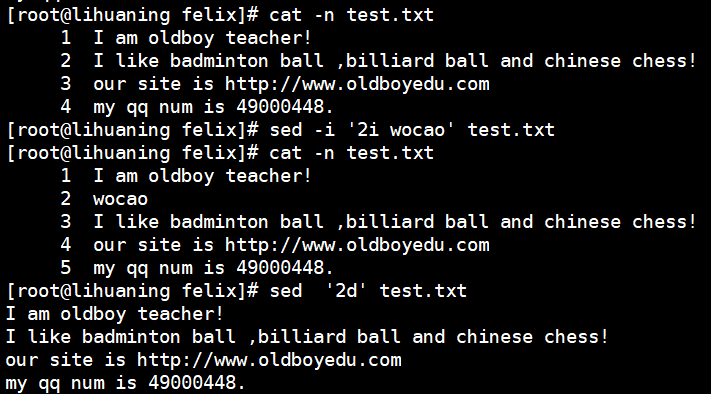
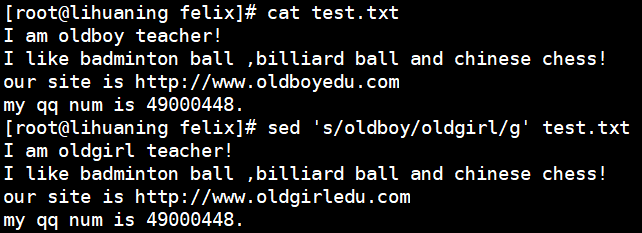
sed案例4: 将文件中的oldboy字符串全部替换为oldgirl※ vim中的替换 :%s/oldboy/oldgirl/g
sed 's/oldboy/oldgirl/g' test.txt<== -i 直接修改文件
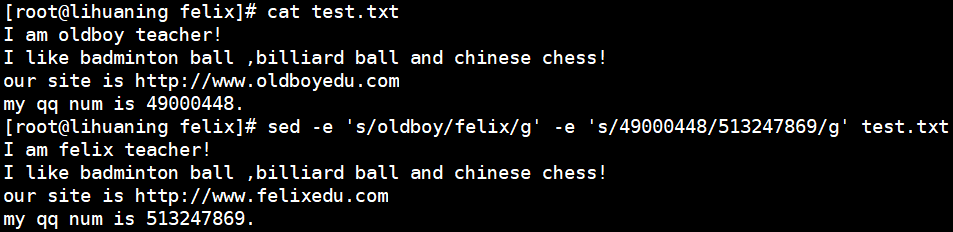
sed案例5: 一次性替换多次,替换oldboy为felix and 49000448为513247869
sed -e 's/oldboy/felix/g' -e 's/49000448/513247869/g' test.txt<==-e多次编辑,可通过-i 直接修改文件
sed案例6: 追加 a 按行追加
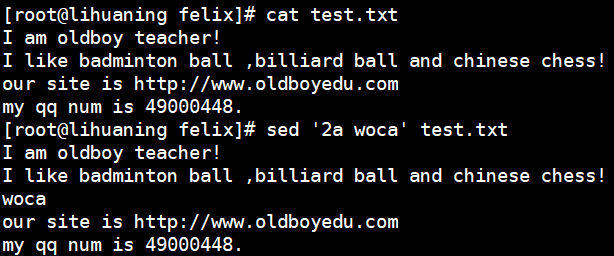
sed '2a woca' test.txt<==在第二行后面追加 wocao
sed案例7: 插入 i 在指定行插入
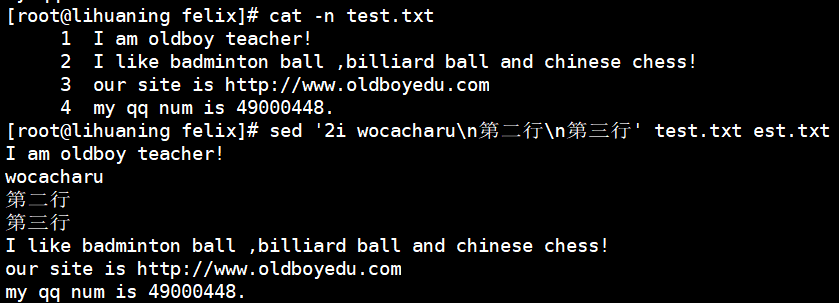
sed '2i wocacharu\n第二行\n第三行' test.txt est.txt<== 加上\n 可插入多行
sed练习 正则是贪婪匹配模式。
ifconfig取ip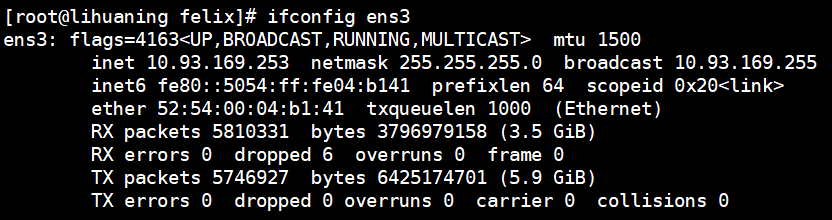
ifconfig ens3 | sed -n 2p | sed 's/^.*inet //g' | sed 's/ netm.*$//g' 输出:10.93.169.253
ifconfig ens3 <===查看ens3网卡的配置信息
sed -n 2p <===取出第2行
sed 's/^.*inet //g' <===开始匹配以任意字符开头,匹配到(inet )后结束,并且替换为空(即删除匹配到的字符)
sed 's/ netm.*$//g <===继续匹配以( netm)且任意字符结尾,并且替换为空(即删除匹配到的字符)方法论: 要取出目标,删除目标两边的,就得到了目标:先匹配上,然后再删除.
[root@lihuaning felix]# ifconfig ens3 | sed -n 2p | sed -e 's/^.*inet //g' -e 's/ netm.*$//g' <===通过-e 进行多次编辑,减少了管道的使用
[root@lihuaning felix]# ifconfig ens3 | sed -ne 's/^.*inet //g' -e 's/ netm.*$//gp' <===通过-n 取消默认输出,再在结尾通过p输出已经匹配到的东西
[root@lihuaning felix]# ifconfig ens3 | sed -nr '2s#^.*inet (.*) netmask.*$#\1#gp' <===通过\1将第一个括号里匹配到的东西通过p打印输出
10.93.169.253
ifconfig ens3 <===查看ens3网卡配置信息
sed -nr '2s#^.*inet (.*) netmask.*$#\1#gp' <== -n参数取消默认输出,-r参数支持ERE扩展元字符在这里指括号()。取出第二行,匹配出inet及其开头和netmask及其末尾,然后通过\n取出内容并替换为 (.*)所匹配到的ip,并它通过内置命令符p打印出来.截取第四行 权限部分 不含0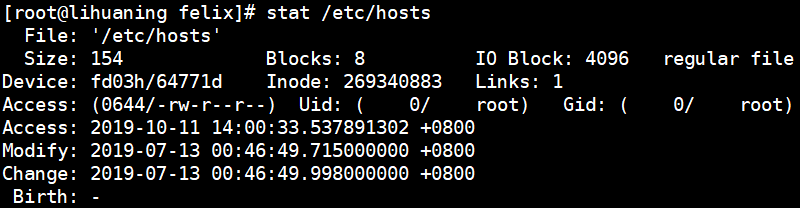
[root@lihuaning felix]# stat /etc/hosts | sed -nr '4s#^.*\(0([0-9]*)/-.*$#\1#gp'
644ip addr 取出ip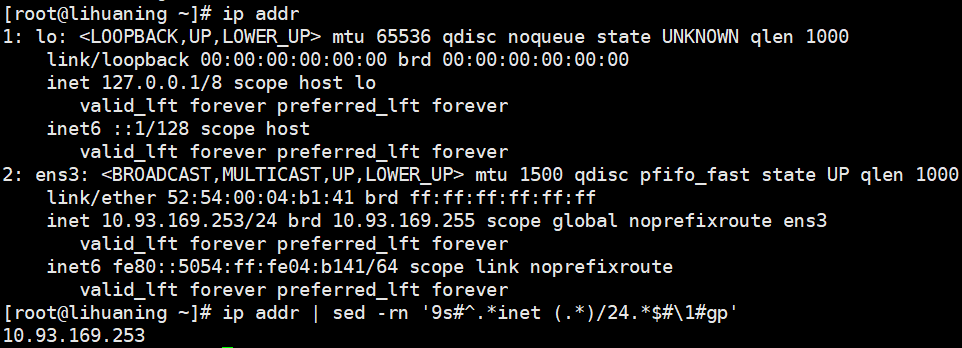
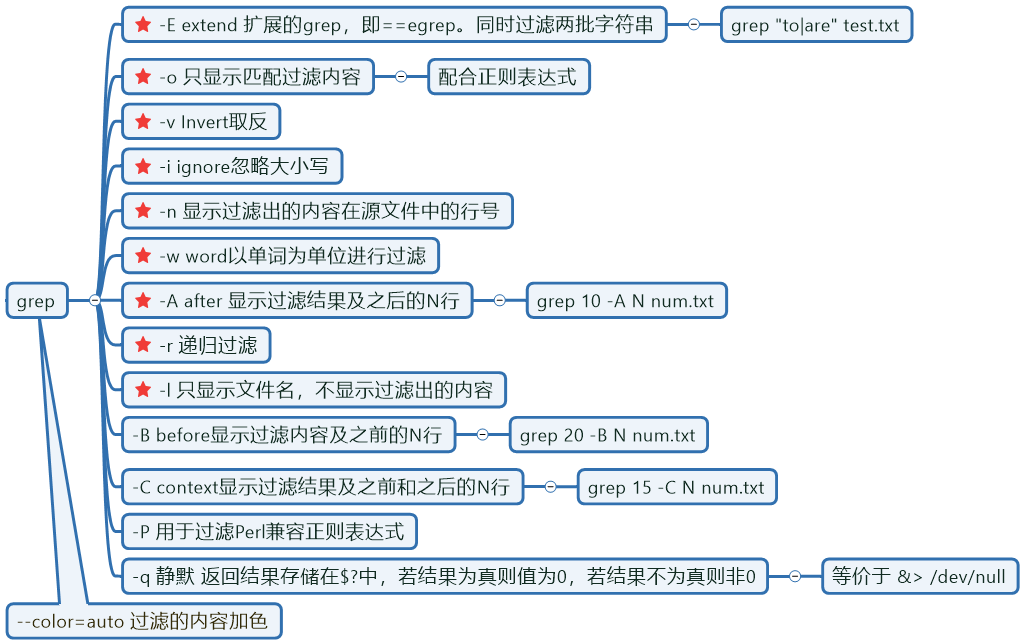
grep
find
find命令 **原理:**磁盘遍历(速度慢) **用法:*按文件名查找:路径 名字(-name) "具体的文件" 参数:
- -name 按文件名查找
- -type 按文件类型查找
- -exec 对查找的结果进行再处理
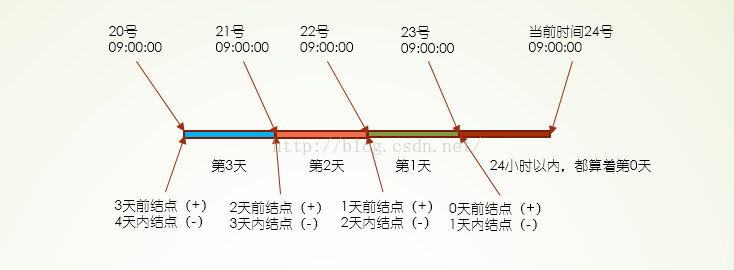
- -mtime 按修改时间查找
- -4 表示文件更改时间距现在4天以内
- +4 表示文件更改时间距现在4天以前
- 4 表示第4天
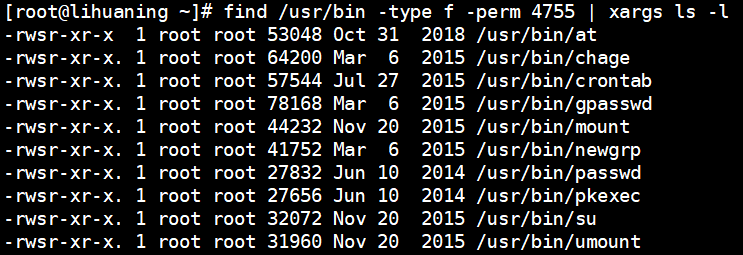
- -perm 按权限查找
- -a and 并且
- -o or 或者
- ! 取反 放在哪个参数后面,就对该参数的结果取反
示例:
find ~/felix -name "felix*" -type f -exec ls -l {} \;({} 表占位符,将-exec之前处理的结果放入其中进行再处理,”;“作为结束标识符,考虑到各系统中分号会有不同的意义,所以前面要加反斜杠对分号进行转义。)find / -type d[f] -name "felix"按文件类型查找,多参数并存取交集find / -type d -o -name "felix"//-o参数取并集(结果匹配到了:所有目录 和 文件名为felix的文件)
xargs 分组,或从标准输入执行命令
- -n数字 每个分组包含几个元素
- -d"" 指定分隔符,不指定默认是空格
- -i 把{}当作前面查找的结果
示例:find ./ -name "felix*" -type f | xargs -i cp {} /root/1/ //从标准输入执行命令
SHELL脚本
变量
shell登录方式:
- 通过系统用户登录后默认运行的Shell
- 非登录交互式运行Shell(手动敲下bash或不需要输密码或远程ssh等操作)
- 执行脚本运行非交互式Shell
正常登录时的加载顺序: 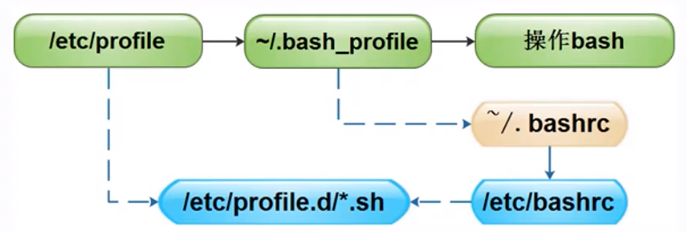
父子shell问题: 使用sh或bash或者默认执行脚本时,会开启一个子Shell运行,而使用source或者.执行脚本,则不会开子Shell,而是在同一个Shell里执行。
通过source或”.”点号加载执行过的脚本,由于是在当前Shell中执行脚本,因此在脚本结束后,脚本中的变量(包括函数)值在当前Shell中依然存在,而sh和bash执行脚本都会启动新的子Shell执行,执行完后退回到父Shell。所以,变量(包括函数)值等无法保留。
因此,在做Shell脚本开发时,如果脚本中有引用或执行其他脚本的内容或者配置文件的需求时,最好用“”点号或source先加载该脚本或配置文件,这样处理后,在加载脚本下面就可以调用source加载的脚本及配置文件中变量及函数等内容了。
变量: 环境变量:又称为全局变量
- 内置环境变量
- 自定义环境变量
查看:env命令 定义:
方法1:
[root@Felix ~]# export FELIX=1
[root@Felix ~]# echo $FELIX
1
方法2:
[root@Felix ~]# QIAOMU=2
[root@Felix ~]# export QIAOMU <==不用export导出的话,就是普通变量
[root@Felix ~]# echo $QIAOMU
2
方法3:
[root@Felix ~]# declare -x FLX=3
[root@Felix ~]# echo $FLX
3永久生效:可以放入/etc/bashrc中。
取消:unset FLX **注意:**书写crond定时任务时要注意,脚本中用到的环境变量最好在执行的Shell脚本中重新定义。
普通变量:又称为局部变量 赋值方法:
变量名=value #<==赋值时不加引号。
变量名='value' #<==赋值时加单引号。
变量名="value" #<==赋值时加双引号。
变量名=`ls` #<==赋值时加反引号。常规普通变量定义: 变量内容为连续数字或字符串时赋值,变量内容两边可以不加引号,例如a=123。
变量的内容很多,有空格且希望解析内容中的变量,就加双引号,例如a="/etc/rc.local $USER",此时输出变量会对内容中的$USER进行解析然后再输出。(ps:双引号解析变量)
希望原样输出变量的内容时就用单引号引起内容进行赋值,例如:a='$USER'。(ps:单引号所见即所得)
希望变量内容是命令的解析结果的定义及赋值:(ps:$()或` `可以解析命令) 要使用反引号将赋值的命令括起来,例如:a=`ls`,或者用$() 括起来,例如:a=$(ls)。
{金庸新}著 天子心经(ps:{}大括号用于区分变量与字符串)
特殊的awk: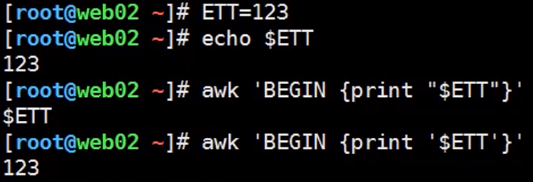
变量总结:
- 变量名 变量名组成、定义规范
- 等号 赋值符,两边不能有空格
- 变量内容 单引号(所见即所得)、双引号(解析变量)、反引号(解析命令)、不加引号(连续的数字或字符串赋值)
- 输出 用echo 或 printf 变量名加$符号,如果变量后面有内容,用{}引用变量部分。
特殊变量
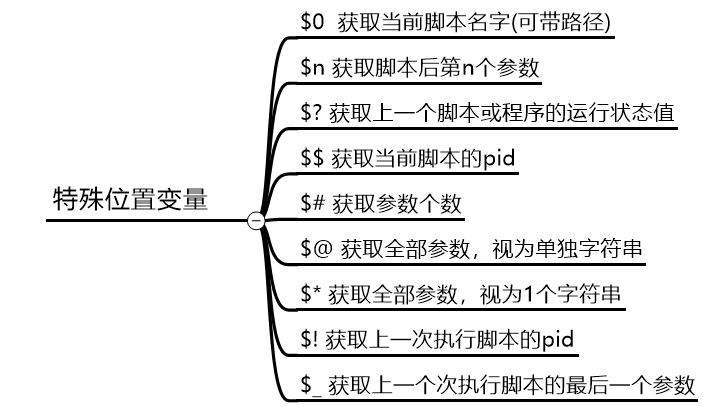 常用特殊位置变量:
常用特殊位置变量:
- $0 获取当前执行Shell脚本文件名,如果执行脚本带路径,那么就包括脚本路径
- $n 获取当前执行的shell脚本的第n个参数值,n=1..9,当n为0时表示脚本的文件名,如果n大于9,则用大括号括起来,例如${10},防止金庸新的情况出现,接的参数以空格隔开
- $# 获取当前执行的shell脚本后面接的参数的总个数
- $* 获取当前执行的shell脚本的所有参数,但是将所有参数视为一个单个字符串"$1 $2 $3"
- $@ 获取当前执行的shell脚本的所有参数,但是将所有参数是为独立字符串"$1" "$2" "$3"
[root@db02 ~]# set -- "I am" itsix felix
[root@db02 ~]# echo $1
I am
[root@db02 ~]# echo $2
itsix
[root@db02 ~]# echo $3
felix
[root@db02 ~]# echo $#
3
[root@db02 ~]# echo $*
I am itsix felix
[root@db02 ~]# echo $@
I am itsix felixshell进程特殊状态变量
- $? 获取执行上一个指令的执行状态返回值(0为成功,非零为失败),这个变量最常用
- $$ 获取当前执行的shell脚本的进程号(PID),这个变量不常用,了解即可
- $! 获取上一个在后台工作的进程的进程号(PID),这个变量不常用,了解即可
- $_ 获取在此之前执行的命令或脚本的最后一个参数,这个变量不常用,了解即可
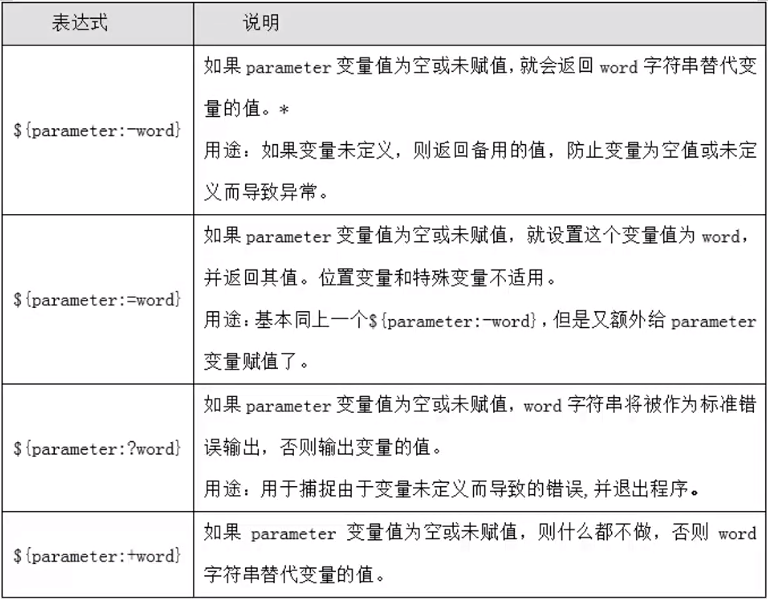
变量子串

${parameter}返回变量$parameter的内容
${#parameter} 返回变量$parameter内容的长度(按字符),也适合特殊变量*
${parameter:offset}在变量${parameter}中,从位置offset之后开始提取子串到结尾
${parameter:offset:length}在变量${parameter}中,从位置offset之后开始提取长度为length的子串[root@db02 ~]# echo ${OLDBOY}
I am oldboy
[root@db02 ~]# echo ${#OLDBOY} <==返回变量内容长度。**
11
[root@db02 ~]# echo ${OLDBOY:5:3} <==从第五个字符开始,往后取三个字符。**
old字串应用-删除
#从开头删除
${parameter#word} 从变量${parameter}【开头】开始删除最【短】匹配的word子串
${parameter##word} 从变量${parameter}【开头】开始删除最【长】匹配的word子串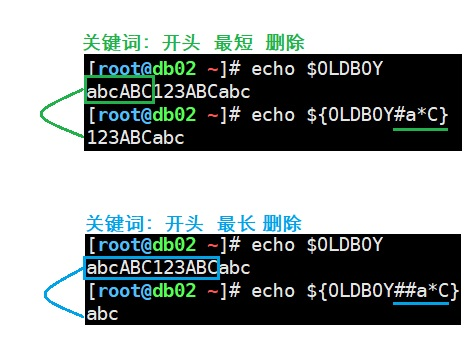
#从结尾删除
${parameter%word} 从变量${parameter}结尾开始删除最短匹配的word子串
${parameter%%word} 从变量${parameter}结尾开始删除最长匹配的word子串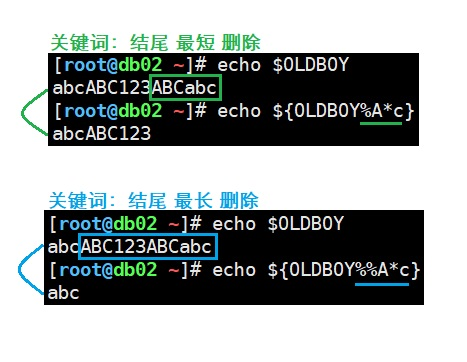 删除小结:
删除小结:
- #表示从开头删除匹配最短。
- ##表示从开头删除匹配最长。
- %表示从结尾删除匹配最短。
- %%表示从结尾删除匹配最长。
- a*c表示匹配的字符串,匹配所有,ac匹配开头为a中间任意多个字符结尾为c的。
- a*C表示匹配的字符串,匹配所有,aC匹配开头为a中间任意多个字符结尾为C的。 口诀:一个匹配删除最短,两个匹配删除最长
字串应用-替换
#类似sed替换
${parameter/pattern/string} 使用string代替第一个匹配的pattern
${parameter//pattern/string} 使用string代替所有匹配的pattern
[root@db02 ~]# OLDBOY="I am Felix. yes. Felix."
[root@db02 ~]# echo $OLDBOY
I am Felix. yes. Felix.
[root@db02 ~]# echo ${OLDBOY/Felix/bangbang}
I am bangbang. yes. Felix.
[root@db02 ~]# echo ${OLDBOY//Felix/bangbang}
I am bangbang. yes. bangbang.获取变量内容长度的方法:
echo $OLDBOY|wc -L
echo ${#OLDBOY}
expr length "$OLDBOY"
echo $OLDBOY|awk '{print length}'
echo $OLDBOY|awk '{print length($0)}'练习:句子中小于6个字符的单词打印出来
Whatever is worth doing is worth doing well.
[root@db02 ~]# sh ww.sh
is
worth
doing
is
worth
doing
well.
[root@db02 ~]# cat ww.sh
judge="Whatever is worth doing is worth doing well."
for word in $judge
do
if [ ${#word} -lt 6 ]
then
echo "$word"
fi
done特殊扩展变量

${parameter:-word}:主胎不在家,备胎启用 **解释:*如果parameter 变量值为空或未赋值,就会返回word字符串替代变量的值。 **用途:**如果变量未定义,则返回备用的值,防止变量为空值或未定义而导致异常。
[root@db02 ~]# test=feichi
[root@db02 ~]# echo $test
feichi
[root@db02 ~]# result=${test:-gun} <==test变量存在,所有内容保持不变
[root@db02 ~]# echo $result
feichi
[root@db02 ~]# unset test <==删除该变量
[root@db02 ~]# echo $test
[root@db02 ~]# result=${test:-gun} <==test变量未定义或为空,被替换成gun
[root@db02 ~]# echo $result
gun
[root@db02 ~]# echo $test${parameter:=word}:主胎不在家,备胎转正 **解释:**如果parameter变量值为空或未赋值,就设置这个变量值为word,并返回其值。位置变量和特殊变量不适用。 **用途:**基本同上一个${parameter:-word},但是又额外给parameter变量赋值了。
[root@db02 ~]# felix=feichi
[root@db02 ~]# echo $felix
feichi
[root@db02 ~]# result=${felix:=513247869} <==主胎在家,备胎未转正
[root@db02 ~]# echo $result
feichi
[root@db02 ~]# echo $felix
feichi
[root@db02 ~]# unset felix <==删除该变量
[root@db02 ~]# echo $felix
[root@db02 ~]# result=${felix:=513247869} <==主胎不在家,备胎转正
[root@db02 ~]# echo $felix
513247869
[root@db02 ~]# echo $result
513247869${parameter:?word}:主胎不在,直接报错 **解释:**如果parameter 变量值为空或未赋值,word字符串将被作为标准错误输出,否则输出变量的值。 **用途:**用于捕捉由于变量未定义而导致的错误,并退出程序。
[root@db02 ~]# felix=feichi
[root@db02 ~]# echo $felix
feichi
[root@db02 ~]# echo ${felix:?error wocao} <==主胎在,输出主胎
feichi
[root@db02 ~]# unset felix
[root@db02 ~]# echo ${felix:?error wocao} <==主胎不在,将?后的字符当error输出
bash: felix: error wocao${parameter:+word}:主胎在家,+后面的字符进行替换 来抢
[root@db02 ~]# echo $felix
[root@db02 ~]# result=${felix:+dengao} <==felix变量为空,什么都不干
[root@db02 ~]# echo $felix
[root@db02 ~]# echo $result
[root@db02 ~]# felix=feichi
[root@db02 ~]# echo $felix
feichi
[root@db02 ~]# result=${felix:+dengao} <==felix定义了内容,+后面的字符将其替换但不改变felix变量内的内容
[root@db02 ~]# echo $result
dengao
[root@db02 ~]# echo $felix
feichi运算符
运算符:+、- : 加、减* *、/、%: 乘法、除法、取余(取模)* **: 幂运算 ++、--: 增加及减少,可前置也可放在变量结尾,默认步长为1 如123,321 !、&&、||: 逻辑非(取反)、逻辑与(and)、逻辑或(or)* <、<=、>、>=:比较符号(小于、小于等于、大于、大于等于) ==、!=、=: 比较符号(相等、不相等、对于字符串“=”也可以表示相等)* <<、>>: 向左移位、向右移位 ~、|、&、^: 按位取反、按位异或、按位与、按位或 =、+=、-=、*=、/=、%=: 赋值运算符,例如a+=1相当a=a+1,a-=1相当a=a-1*
shell常见运算命令: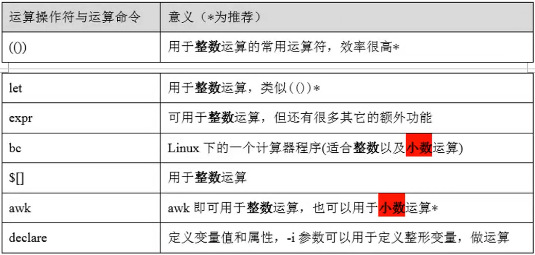 数值运算: 1)整数运算:
数值运算: 1)整数运算:
方法1:let
[root@db02 ~]# a=1
[root@db02 ~]# let a=a+1
[root@db02 ~]# echo $a
2
方法2:(())
[root@db02 ~]# a=1
[root@db02 ~]# ((a=a+1))
[root@db02 ~]# echo $a
2
方法3:expr
[root@db02 ~]# a=10
[root@db02 ~]# expr $a + 10
20
[root@db02 ~]# a=`expr $a + 10`
[root@db02 ~]# echo $a
20
方法4:$[]
[root@db02 ~]# a=11
[root@db02 ~]# echo $[a+11]
22
[root@db02 ~]# c=$[a+11]
[root@db02 ~]# echo $c
22
方法5:declare
[root@db02 ~]# a=8
[root@db02 ~]# declare -i a=a+10
[root@db02 ~]# echo $a
18
案例:
[root@db02 ~]# ((a=1+2**3-4%3))
[root@db02 ~]# echo $a
82)整数或者小数运算
方法1:bc
[root@db02 ~]# echo 10+9|bc #加
19
[root@db02 ~]# echo 10*9|bc #乘
90
[root@db02 ~]# echo 10/9|bc #除
1
[root@db02 ~]# echo "scale=4;10/9"|bc #保留4位小数
1.1111
[root@db02 ~]# echo 3^2|bc #幂运算
9
[root@db02 ~]# echo 1.1*2|bc #小数乘
2.2
方法2:awk
[root@db02 ~]# echo 1.1 2 | awk '{print $1*$2}'
2.2
[root@db02 ~]# echo 1.1 2 | awk '{print $1%$2}'
1.1
[root@db02 ~]# echo 4 2 | awk '{print $1%$2}'
03)自增或自减运算(++\--) 执行echo $((a++))和echo $((a--))命令输出整个表达式时,输出的值为a的值,表达式执行完毕后,会对a进行++、--的运算, 执行echo $((++a))和echo $((--a))命令输出整个表达式时,会先对a进行++、--的运算,然后再输出表达式的值,即为a运算后的值。
[root@db02 ~]# a=10
[root@db02 ~]# echo $((a--)) <== --在$a后,表达式先不减。表达式执行完成会对$a进行++ --运算。
10
[root@db02 ~]# echo $a
9
[root@db02 ~]# echo $((--a)) <== --在$a前,先对$a进行运算。表达式在输出值。
8
[root@db02 ~]# echo $a
8有关++,--运算的记忆方法: 变量a在运算符前,输出表达式的值为a,然后a自增或自减;变量a在运算符后,输出表达式会先自增或自减,表达式的值就是自增或自减后a的值。
4)(())的逻辑判断
[root@web01 /server/scripts]# ((8>7))
[root@web01 /server/scripts]# echo $?
0
[root@web01 /server/scripts]# ((8<7))
[root@web01 /server/scripts]# echo $?
1
[root@web01 /server/scripts]# ((8<7&&6>5))
[root@web01 /server/scripts]# echo $?
1
[root@web01 /server/scripts]# ((8<9&&6>5))
[root@web01 /server/scripts]# echo $?
0
[root@web01 /server/scripts]# ((8<7||6>5))
[root@web01 /server/scripts]# echo $?5)expr功能:
1.计算
[root@web01 /server/scripts]# expr 10 + 10
20
2.获取字符串长度
[root@db02 ~]# a="felix"
[root@db02 ~]# echo $a
felix
[root@db02 ~]# expr length $a
5
3.判断字符串是否为整数数字或字符
[root@web01 /server/scripts]# a=1
[root@web01 /server/scripts]# expr $a + 1 &>/dev/null
[root@web01 /server/scripts]# echo $?
0
[root@web01 /server/scripts]# a=oldboy
[root@web01 /server/scripts]# expr $a + 1 &>/dev/null
[root@web01 /server/scripts]# echo $?
2 <==逆向思维:expr字符串或小数与整数相加会报错,即$? 不为0. 即$?为0
就表示 两边运算符两边都是整数数,而不是字符串或浮点数
4.用来判断文件扩展名是否符合指定扩展名
[root@web01 /server/scripts]# cat judge.sh
if expr "$1" : ".*\.avi$" >/dev/null ; then
echo "好兴奋啊"
else
echo "好失望啊"
fi
[root@web01 /server/scripts]# sh judge.sh oldboy.avi
好兴奋啊
[root@web01 /server/scripts]# sh judge.sh oldboy.log
好失望啊脚本传参
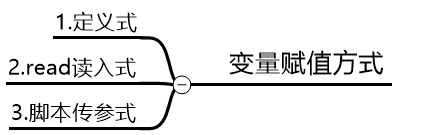 read命令: 参数:
read命令: 参数:
- -p:输出文字提示
- -t:指定超时时间
本质:交互式给变量赋值 例:
1)相当于n=100
[root@db02 ~]# read -p "请输入一个数字:" n
请输入一个数字:100
[root@db02 ~]# echo $n
100
2)相当于n=90 m=100
[root@db02 ~]# read -p "请输入两个数字:" n m
请输入两个数字:90 100
[root@db02 ~]# echo $n $m
90 100变量赋值的3种方式:
1.定义式
a=1
2.read读入式
read -p "请输入两个数字:" n m
3.脚本传参
$1=100
1.交互式传参:
[root@db02 ~]# cat 01.dingyi.sh
read -p "请输入a,b的值:" a b
echo "$a+$b=$((a+b))"
echo "$a-$b=$((a-b))"
echo "$a*$b=$((a*b))"
echo "$a/$b=$((a/b))"
echo "$a**$b=$((a**b))"
echo "$a%$b=$((a%b))"
[root@db02 ~]# sh 01.dingyi.sh
请输入a,b的值:9 10
9+10=19
9-10=-1
9*10=90
9/10=0
9**10=3486784401
9%10=9
2.传参:
[root@db02 ~]# cat 01.dingyi.sh
a=$1
b=$2
echo "$a+$b=$((a+b))"
echo "$a-$b=$((a-b))"
echo "$a*$b=$((a*b))"
echo "$a/$b=$((a/b))"
echo "$a**$b=$((a**b))"
echo "$a%$b=$((a%b))"
[root@db02 ~]# bash 01.dingyi.sh 7 6
7+6=13
7-6=1
7*6=42
7/6=1
7**6=117649
7%6=1`stty erase '^H'` read -p "input: " read交互式删除退格
条件测试
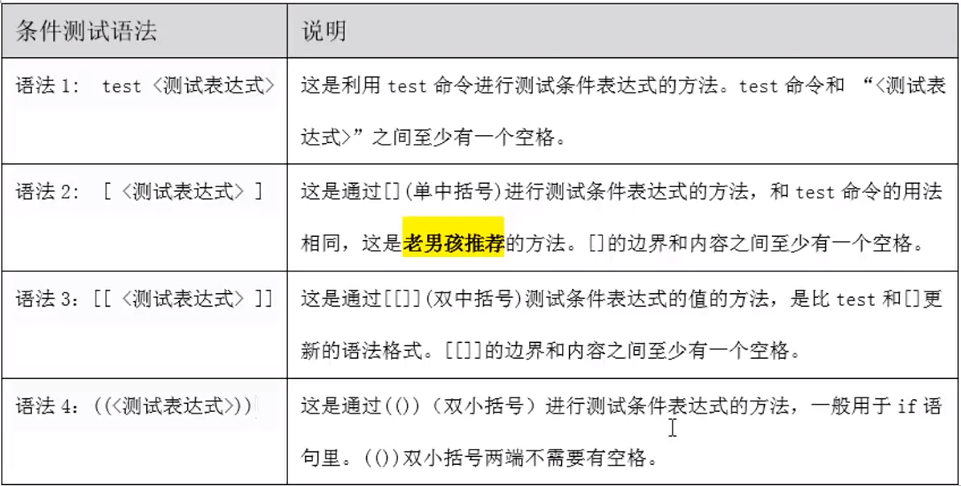 一句话定义:判断符合条件才进行处理,不符合条件不处理。 表达式1:如果条件成立,那么执行三个命令。
一句话定义:判断符合条件才进行处理,不符合条件不处理。 表达式1:如果条件成立,那么执行三个命令。
[ 条件1 ] && {
命令1
命令2
命令3
}表达式2:如果表达式不成立,那么执行三个命令。
if [ 条件1 ]
then
命令1
命令2
命令3
fi
【等价】
[ 条件1 ] || {
命令1
命令2
命令3
}表达式3:如果条件成立,那么执行命令1命令2,否则执行命令3。
[ -L oldboy ] && echo 1 || echo 0
【等价】
[ 条件1 ] && {
命令1
命令2
} || {
命令3
}分析:
[ -x /sbin/ip ] || exit 1
可执行 不成立 退出例子:(判断文件是否存在)test
[root@db02 ~]# ls
01.dingyi.sh anaconda-ks.cfg ww.sh
[root@db02 ~]# test -f a.txt && echo felix > a.txt || echo 没有
没有
[root@db02 ~]# touch a.txt
如果 存在 那么 执行 否则 执行
[root@db02 ~]# test -f a.txt && echo felix > a.txt || echo 没有
[root@db02 ~]# cat a.txt
felix例子:(判断文件是否有执行权限)test
如果 可执行 那么 执行 否则 打印
[root@db02 ~]# test -x ww.sh && ./ww.sh || echo "没有执行权限"
没有执行权限
[root@db02 ~]# ll ww.sh
-rw-r--r-- 1 root root 133 12月 17 17:53 ww.sh
[root@db02 ~]# chmod +x ww.sh
[root@db02 ~]# ll ww.sh
-rwxr-xr-x 1 root root 133 12月 17 17:53 ww.sh
[root@db02 ~]# test -x ww.sh && ./ww.sh || echo "没有执行权限"
is
worth
doing
is
worth
doing
well.例子:(判断文件是否有执行权限)[ ]
[root@db02 ~]# [ -x ww.sh ]&& ./ww.sh || echo "没有执行权限"
is
worth
doing
is
worth
doing
well.例子:(判断文件是否有执行权限)[[]]
[root@db02 ~]# [[ -x ww.sh ]]&& ./ww.sh || echo "没有执行权限"
is
worth
doing
is
worth
doing
well.文件测试表达式
一句话定义:对问文件的属性进行判断,然后根据结果进行处理。 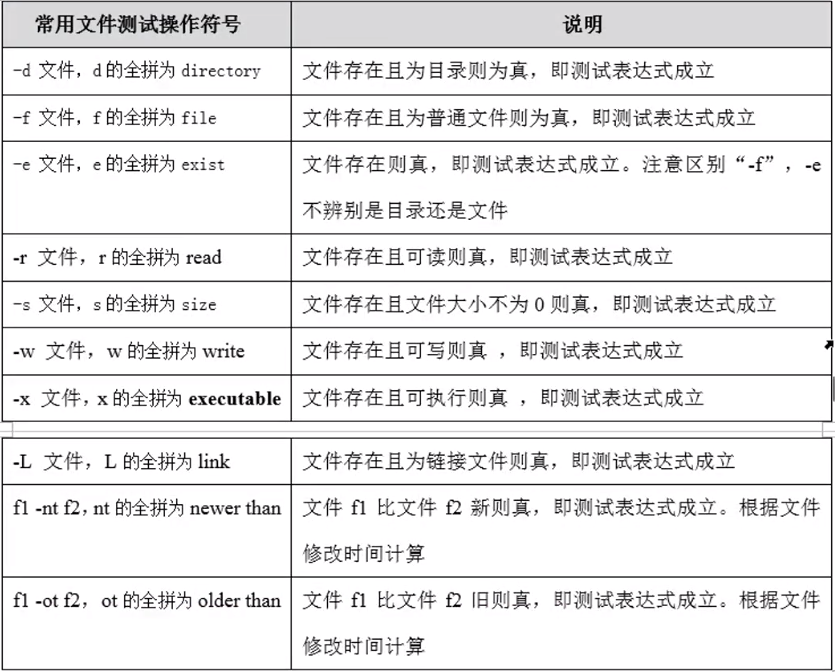
[root@db02 ~]# touch felix.txt
[root@db02 ~]# [ -f felix.txt ] && echo 1 || echo 0
1 如果.. 那么.. 否则..
[root@db02 ~]# rm -rf felix.txt
[root@db02 ~]# [ -f felix.txt ] && echo 1 || echo 0 <==文件不存在,则echo 0(-f 测试普通文件)
0
[root@db02 ~]# mkdir felix
[root@db02 ~]# [ -f felix ] && echo 1 || echo 0 <==felix为目录,不是普通文件所以输出echo 0
0
[root@db02 ~]# [ -d felix ] && echo 1 || echo 0 <==目录存在,则echo 0(-d 测试目录)
1
[root@db02 ~]# [ -e felix ] && echo 1 || echo 0 <==文件或目录存在,则echo 1(-e 测试文件或目录)
1
[root@db02 ~]# [ -r felix.txt ] && echo 1 || echo 0 <==文件或目录可读,不存在则echo 0(-r 测试文件是否可读)
0
[root@db02 ~]# touch felix.txt
[root@db02 ~]# [ -r felix.txt ] && echo 1 || echo 0 <==文件或目录可读,则echo 1
1
[root@db02 ~]# [ -s felix.txt ] && echo 1 || echo 0 <==文件或目录大小不为0,空文件则输出0(-s 测试文件是否为空)
0
[root@db02 ~]# echo 1 > felix.txt
[root@db02 ~]# [ -s felix.txt ] && echo 1 || echo 0
1
[root@db02 ~]# [ -w felix.txt ] && echo 1 || echo 0 <==文件是否可写,可写则echo 1(-w 测试文件是否可写)
1
[root@db02 ~]# [ -x felix.txt ] && echo 1 || echo 0 <==文件是否可执行,不可执行则echo 0(-x 测试文件是否可执行)
0
[root@db02 ~]# [ -L felix.txt ] && echo 1 || echo 0
0字符串测试表达式
一句话定义:长度,是否为空,是否相等,是否不等。 
注意:
- 字符串判断要将字符串用 双引号" "
- 等号两端必须要有空格
- "="和"!=" 用于比较两个字符串是否相同
-n no zero不为零
[root@db02 ~]# echo "$flx"
[root@db02 ~]# [ -n "$flx" ] && echo 1 || echo 0 <==为零为假
0
[root@db02 ~]# flx=felix
[root@db02 ~]# [ -n "$flx" ] && echo 1 || echo 0 <==不为零为真
1-z zero为零
[root@db02 ~]# flx=felix
[root@db02 ~]# [ -z "$flx" ] && echo 1 || echo 0 <==不为零为假
0
[root@db02 ~]# unset flx
[root@db02 ~]# [ -z "$flx" ] && echo 1 || echo 0 <==为零为真
1字符串测试相等
[root@db02 ~]# echo "$flx"
felix
[root@db02 ~]# nsu="12345"
[root@db02 ~]# echo $nsu
12345
[root@db02 ~]# [ "$flx" = "$nsu" ] && echo 1 || echo 0 <==变量内容不相等为假
0
[root@db02 ~]# [ "$flx" = "felix" ] && echo 1 || echo 0 <==内容相等为真
1
[root@db02 ~]# [ "${#flx}" = "${#nsu}" ] && echo 1 || echo 0 <==字符串长度相等为真
1传参和条件测试练习
对传入的参数或者read读入的变量内容判断,如果不符合计算条件,提示用户,并退出。
read -p "请输入两个数,以空格分割:" a b
[ -z $a ] || [ -z $b ] && {
echo "[error]:请输入两个数值"
exit 1
}
for n in $a $b
do
expr $n + 1 &> /dev/null
[ $? -eq 0 ] && {
echo "$n [Data ok!]";
}||{
echo "[ERROR Data are not Numbers!]"
exit 1
}
done
echo "$a+$b=$((a+b))"
echo "$a-$b=$((a-b))"
echo "$a*$b=$((a*b))"
echo "$a/$b=$((a/b))"
echo "$a%$b=$((a%b))"
echo "$a**$b=$((a**b))"
通过脚本传参的方式完成上面的例子
#/bin/bash
#1.判断是否为两个参数
[ $# -ne 2 ]&&{
echo "$0 num1 num2 ✔"
exit 1
}
#2.判断参数是否为数字
expr $1 + $2 + 100 &>/dev/null
[ $? -eq 0 ]&&{
echo "[data ok]:$1 $2"
}||{
echo "请输入两个正确的整数!"
exit 2
}
#3.开始计算
a=$1
b=$2
echo $a+$b=$((a+b))
echo $a-$b=$((a-b))
echo $a^$b=$((a**b))
[ $b -eq 0 ]&&{
echo "[error] 除数为0,取余和除法不能计算。×"
}||{
echo $a/$b=$((a/b))
echo $a%$b=$((a%b))
}二元整数比较
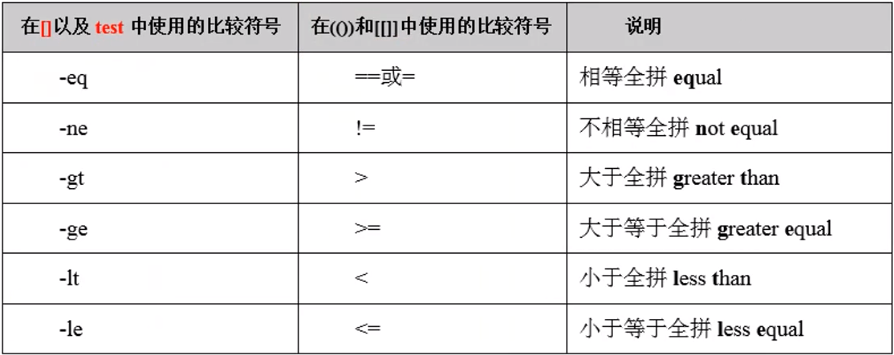
整数比较:
[root@db02 ~]# [ 1 -eq 1 ] && echo 1 || echo 0 <==等于
1
[root@db02 ~]# [ 1 -ne 1 ] && echo 1 || echo 0 <==不等于
0
[root@db02 ~]# [ 1 -ge 1 ] && echo 1 || echo 0 <==大于等于
1
[root@db02 ~]# [ 1 -gt 1 ] && echo 1 || echo 0 <==大于
0
[root@db02 ~]# [ 1 -lt 1 ] && echo 1 || echo 0 <==小于
0
[root@db02 ~]# [ 1 -le 1 ] && echo 1 || echo 0 <==小于等于
1逻辑操作符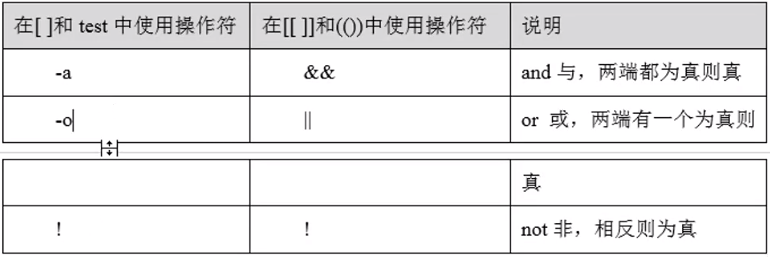
在一个表达式中,放入多个条件。
[root@db02 ~]# [ -f /etc/hosts -a 1 -eq 1 ] && echo 1 || echo 0
1
[root@db02 ~]# [ -f /etc/hosts -a 1 -eq 2 ] && echo 1 || echo 0
0
[root@db02 ~]# [ -f /etc/hosts -o 1 -eq 2 ] && echo 1 || echo 0
1
[root@db02 ~]# [ -f /etc/hosts -o 1 -eq 2 ] && echo 1 || echo 0
1
[root@db02 ~]# [ -f /etc/hosts -a ! 1 -eq 2 ] && echo 1 || echo 0 <==对指定条件进行取反
1
连接两个括号的操作符:
[root@db02 ~]# [ -f /etc/hosts ] && [ 1 -eq 2 ] && echo 1 || echo 0
0
[root@db02 ~]# [ -f /etc/hosts ] || [ 1 -eq 2 ] && echo 1 || echo 0
1
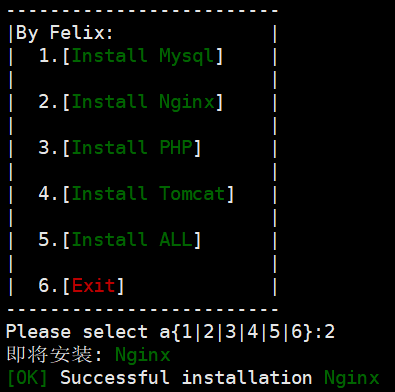
菜单练习
#/bin/bash
Inl="即将安装:"
One="\033[40;32m MySQL\033[0m"
Two="\033[40;32m Nginx \033[0m"
Three="\033[40;32m PHP \033[0m"
Four="\033[40;32m Tomcat \033[0m"
Five="\033[40;32m ALL \033[0m"
Err="\033[40;31m[Error]\033[0m Please check the.."
Ok="\033[40;32m[OK] \033[0mSuccessful installation"
/bin/clear
read -p "Please select a{1|2|3|4|5|6}:" n
expr $n + 1 &>/dev/null
[[ -z $n || $? -ne 0 || ! $n =~ [1-6] ]] && {
/bin/clear
/bin/bash $0
exit 0
}
[ $n -eq 6 ] && {
echo -e "\033[40;31mQuit!\033[0m"
exit 0
}||{
[ $n -eq 5 ] && {
echo -e "${Inl}${Five}"
sleep 5
echo -e "${Ok}${Five}"
exit 0
}||
[ $n -eq 4 ] && {
echo -e "${Inl}${Four}"
sleep 5
echo -e "${Ok}${Four}"
exit 0
}||
[ $n -eq 3 ] && {
echo -e "${Inl}${Three}"
sleep 5
echo -e "${Ok}${Three}"
exit 0
}||
[ $n -eq 2 ] && {
echo -e "${Inl}${Two}"
sleep 5
echo -e "${Ok}${Two}"
exit 0
}||
[ $n -eq 1 ] && {
echo -e "${Inl}${One}"
sleep 5
echo -e "${Ok}${One}"
exit 0
}
}
if判断
单分支:(如果......那么)
if <条件表达式>
then
指令
fi
if <条件表达式>; then
指令
fi双分支:(如果......那么......否则)
if <条件表达式>
then
指令
else
指令
fi多分枝:(如果.......那么......或者那么......或者那么......否则)
if <条件表达式>;then
指令1
elif <条件表达式>;then
指令2
elif <条件表达式>;then
指令3
else
指令4
fi- 传参计算:
#/bin/bash
#1.判断是否为两个参数
if [ $# -ne 2 ]
then
echo "$0 num1 num2 ✔"
exit 1
fi- 判断参数是否为数字
expr $1 + $2 + 100 &>/dev/null
if [ $? -eq 0 ]
then
echo "[data ok]:$1 $2"
else
echo "请输入两个正确的整数!"
exit 2
fi- 开始计算
a=$1
b=$2
echo $a+$b=$((a+b))
echo $a-$b=$((a-b))
echo $a^$b=$((a**b))
if [ $b -eq 0 ]
then
echo "[error] 除数为0,取余和除法不能计算。×"
else
echo $a/$b=$((a/b))
echo $a%$b=$((a%b))
fi- 内存告警
[root@KFSAMBA ~]# tail -1 /etc/mail.rc
set from=513247869@qq.com smtp=smtp.qq.com smtp-auth-user=513247869 smtp-auth-password=qfztqqoggfblbgec
#/bin/bash
free_mem=$(free -m | awk -F" " 'NR==2{print $7}')
flx=`echo "scale=2;$free_mem/1024" |bc`
date=`date +"%F %H:%M:%S"`
if [ $free_mem -lt 8000 ];then
echo "[$date] 废了,没内存了: ${flx}G" |tee -a /var/log/mem.log #追加并输出
/usr/bin/tail -1 /var/log/mem.log | /usr/bin/mail -s "$(date) 内存警告" 513247869@qq.com
else
echo "[$date] 内存还够: ${flx}G" |tee -a /var/log/mem.log
fi服务监控
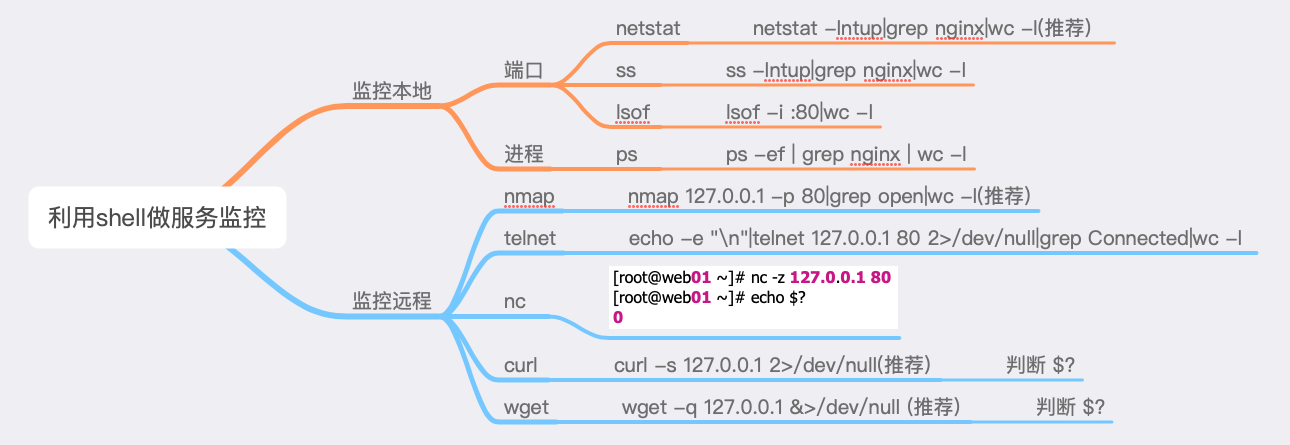 nc的控制参数不少,常用的几个参数如下所列:
nc的控制参数不少,常用的几个参数如下所列:
- -l 用于指定nc将处于侦听模式。指定该参数,则意味着nc被当作server,侦听并接受连接,而非向其它地址发起连接。
- -p
[port]暂未用到(老版本的nc可能需要在端口号前加-p参数,下面测试环境是centos6.6,nc版本是nc-1.84,未用到-p参数) - -s 指定发送数据的源IP地址,适用于多网卡机
- -u 指定nc使用UDP协议,默认为TCP
- -v 输出交互或出错信息,新手调试时尤为有用
- -w 超时秒数,后面跟数字
- -z 表示zero,表示扫描时不发送任何数据
Nginx监控
#/bin/bash
#nginx=$(/application/nginx/sbin/nginx)
date=`date +"%F %H:%M:%S"`
nginxcmd="/application/nginx/sbin/nginx"
#监控服务
if [ $# -eq 0 ];then
/usr/bin/netstat -lntup | grep 80 &> /dev/null
if [ $? -ne 0 ]
then
echo "[$date] 不行了,nginx崩了" |tee -a /var/log/nginx_state.log
/usr/bin/tail -1 /var/log/nginx_state.log | /usr/bin/mail -s "$(date) nginx告警" 513247869@qq.com
exit 1
else
echo "[$date]nginx 状态正常!"
exit 0
fi
fi
#启动脚本
[[ $# -ne 1 ]] && {
echo "$0 {start|stop|restart|reload}"
exit 1
}
if [ "$1" = "start" ];then
$nginxcmd -c /application/nginx/conf/nginx.conf &> /dev/null
/bin/bash $0
exit 0
elif [ "$1" = "restart" -o "$1" = "reload" ];then
$nginxcmd -c /application/nginx/conf/nginx.conf &> /dev/null
$nginxcmd -s reload &> /dev/null
exit 0
elif [ "$1" = "stop" ];then
$nginxcmd -s stop &> /dev/null
exit 0
else
echo "[ERROR] $0 {start|stop|restart|reload}"
exit 2
fi函数传参
语法1:
function 函数名() {
}语法2:
function 函数名 {
}语法3:
函数名 () {
}函数的执行过程:
- 执行Shell函数时,函数名前的function和函数后的小括号都不要带。
- 函数的定义必须在要执行前面定义或加载好(先定义,再执行)。
- Shell执行系统中各种程序的顺序为:系统别名→函数→系统命令→可执行文件。
- 函数执行时,会和调用它的脚本共用变量,也可以为函数设定局部变量以及特殊位置参数。
- 在shell函数里面,return命令功能与exit类似,作用是退出函数,而exit是退出脚本文件。
- return 语句会返回一个退出值(即返回值)给调用函数的当前程序,而exit会返回一个退出值(即返回值)给执行程序的当前Shell。
- 如果函数存放在独立的文件中,被脚本加载使用时,需要使用source或者.来加载。
- 在函数内一般使用local定义局部变量,这些变量离开函数后即消失。
函数传参:
- Shell的位置参数($1、$2…、$#、$*、$?以及$@)都可以作为函数的参数使用。
- 此时父脚本的参数临时地被函数参数所掩盖或隐藏。
- $0比较特殊,它仍然是父脚本的名称。
- 当函数执行完成时,原来的命令行脚本的参数即恢复。
- 函数的参数变量是在函数体里面定义的。
[root@KFSAMBA ~]# sh function.sh
I am felix
[root@KFSAMBA ~]# cat function.sh
#/bin/bash
felix(){
echo "I am felix"
}
felix第一步:
[root@KFSAMBA ~]# sh function.sh
I am 第一个参数
[root@KFSAMBA ~]# cat function.sh
#/bin/bash
felix(){
echo "I am $1"
}
felix 第一个参数 <==这个参数传递给了函数felix,felix函数中再通过$1进行带入第二步:
[root@KFSAMBA ~]# sh function.sh 第一
I am 第一
[root@KFSAMBA ~]# cat function.sh
#/bin/bash
felix(){
echo "I am $1" <==2.这里的$1是指函数的第一个参数。此脚本中函数的第一个参数就是脚本的第一个参数
}
felix $1 <==1.这里的$1是指脚本的第一个参数,将用户传入脚本的第一个参数传给函数
函数内定义私有变量:
函数(){
local s=1
}检查url是否正常
- 检查url是否正常
[root@KFSAMBA ~]# sh check_url.sh baidi.com
URL is no
[root@KFSAMBA ~]# cat check_url.sh
#!/bin/bash
wegt -q $1 &>/dev/null <==-q 不显示输出
retval=$?
if [ $retval -eq 0 ] <==判断返回值
then
echo "URL is ok"
else
echo "URL is no"
fi- 调用函数实现
#!/bin/bash
check_url(){
wget -q -o /dev/null --spider --tries=1 -T 5 $1 <==3.check函数接收main函数的参数,得出结果
#T#超时时间
#spider#爬虫,模拟访问不下载
#tries #wegt次数
#-T #超时时间
retval=$?
if [ $retval -eq 0 ]
then
echo "URL is ok"
else
echo "URL is no"
fi
}
main(){
check_url $1 <==2.main函数的参数传递给check函数
}
main $* <==1.传递脚本参数给main函数- 传参的方式调用函数
#!/bin/bash
usage(){
if [[ ! $1 =~ http://.*$ ]]
then
echo "Usage:$0 http://www.xxx.com"
exit 1
fi
}
check_url(){
wget -q $1 &>/dev/null
retval=$?
if [ $retval -eq 0 ]
then
echo "URL is ok"
else
echo "URL is no"
fi
}
main(){
usage $1
check_url $1
}
main $*系统自带函数
action函数
# Run some action. Log its output.
action() {
local STRING rc
STRING=$1
echo -n "$STRING "
shift
"$@" && success $"$STRING" || failure $"$STRING"
rc=$?
echo
return $rc
}调用action
#!/bin/bash
[ -f /etc/init.d/functions ] && . /etc/init.d/functions <==函数库文件存在就加载
usage(){
if [[ ! $1 =~ http://.*$ ]]
then
echo "Usage:$0 http://www.xxx.com"
exit 1
fi
}
check_url(){
wget -q -o /dev/null --spider --tries=1 -T 5 $1
#spider#爬虫,模拟访问不下载
#tries #wegt次数
#-T #超时时间
retval=$?
if [ $retval -eq 0 ]
then
action "URL is ok" /bin/true <==调用action函数
else
action "URL is no" /bin/false
fi
}
main(){
usage $1
check_url $1
}
main $*测试
case
case结构条件句的语法格式为
case "变量" in
值1)
指令1...
;;
值2)
指令2...
;;
*)
指令3...
esac
相当于if多分支语句。
if [ "变量" ="值1" ]
then
指令1...
elif [ "变量" ="值2" ]
then
指令2...
else
指令3...
fi菜单实现
#!/bin/bash
###################################################
# File Name: 3.sh
# Created Time: Thu 26 Dec 2019 01:55:17 PM CST
# Version: V1.0
# Author: Felix
# Organization: 360JR OPS
###################################################
#vars
Inl="即将安装:"
One="\033[40;32m MySQL\033[0m"
Two="\033[40;32m Nginx \033[0m"
Three="\033[40;32m PHP \033[0m"
Four="\033[40;32m Tomcat \033[0m"
Five='\033[40;32m ALL \033[0m'
Err="\033[40;31m[Error]\033[0m Please check the.."
Ok="\033[40;32m[OK] \033[0mSuccessful installation"
[ -f /etc/init.d/functions ] && . /etc/init.d/functions
#menus
list(){
/bin/clear
echo -e "-------------------------
By Felix:
1.[\033[40;34m Install\033[0m$One ].a
2.[\033[40;34m Install\033[0m$Two ].b
3.[\033[40;34m Install\033[0m$Three ].c
4.[\033[40;34m Install\033[0m$Four].d
5.[\033[40;34m Install\033[0m$Five ].e
6.[\033[40;34m Exit\033[0m ].f
-------------------------"
echo "Please select a{1|a,2|b,3|c,4|d,5|e,6|f}:"
read n
gather=$n
}
ftc(){
/bin/clear
/bin/bash $0
exit 1
}
#Input value judgment
isdigit(){
expr $gather + 1 &>/dev/null
x=$?
if [[ "$gather" =~ ^[a-f]$ ]];then #<==如果匹配到a-f就什么都不干
:
elif [[ -z $gather || $x -ne 0 || ! $gather =~ ^[1-6]$ ]];then #<==如果传入值不为数字就重新执行脚本
ftc
fi
}
#Installation status diagram
choose(){
echo -e "${Inl} $*"
sleep 5
}
win(){
echo -e "${Ok} $*"
exit 0
}
#Choose to determine
checkbox(){
case "$gather" in
6|f)
echo -e "\033[40;31mQuit!\033[0m"
exit 0
;;
5|e)
choose ${Five}
win ${Five}
;;
4|d)
choose ${Four}
win ${Four}
;;
3|c)
choose ${Three}
win ${Three}
;;
2|b)
choose ${Two}
win ${Two}
;;
1|a)
choose ${One}
win ${One}
;;
*)
:
esac
}
#Call all
main(){
list
isdigit
checkbox
}
main
返回值传递
#!/bin/bash
# chkconfig: 2345 21 81
# description: startup rsync scripts
PID=/var/run/rsyncd.pid
start(){
if [ -f $PID -a -s $PID ]
then
:
else
rsync --daemon
fi
return $? <==把函数执行结果通过return传出
}
stop(){
if [ -f $PID -a -s $PID ]
then
kill `cat $PID`
fi
return $?
}
case "$1" in
start)
start
retval=$?
;;
stop)
stop
retval=$?
;;
restart)
stop
sleep 2
start
retval=$?
;;
*)
echo "Usage;$0 {start|stop|restart}"
esac
exit $retvalC6启动脚本
service管理的服务需要将其脚本文件放在/etc/init.d目录中,通过chkconfig管理。 rsync启动脚本解析
#!/bin/bash
# chkconfig: 2345 21 81
# description: rsync service start and stop scripts
# Author: Felix
# Organization:
#加载自带函数库
[ -f /etc/rc.d/init.d/functions ] && source /etc/rc.d/init.d/functions
#程序锁文件,用来判断程序是否启动
lockdir='/var/lock/subsys'
lock_file_path="$lockdir/rsync"
#pid文件
rsyncd_pid_file_path="/var/run/rsyncd.pid"
#成功提示函数
log_success_msg(){
#action为特殊的提示函数,$@为所有参数。
action "SUCCESS! $@" /bin/true
}
#失败提示函数
log_failure_msg(){
action "ERROR! $@" /bin/false
}
#启动函数
start(){
rsync --daemon &>/dev/null
retval=$?
if [ $retval -eq 0 ] #<==获取状态码,为0表示启动成功
then
log_success_msg "Rsyncd is started."
if test -w "$lockdir" #判断锁目录是否可写。
then
touch "$lock_file_path" #创建锁文件,表示程序已经正常启动。
return $retval
else
log_failure_msg "Rsync lockfile denied" #目录不可写,创建锁文件失败,调用失败函数提示。
return 1
fi
else
echo "Rsyncd startup fail." #返回值不为0,表示启动失败。
return 1
fi
}
#停止函数
stop(){
if test -s "$rsyncd_pid_file_path" #判断文件是否不为空。
then
#读取pidfile
rsyncd_pid=`cat "$rsyncd_pid_file_path"` #不为空则获取pid
if (kill -0 $rsyncd_pid 2>/dev/null) #通过进程号,判断对应的进程是否存在。
then
kill $rsyncd_pid #进程存在就杀死进程
retval=$?
if [ $retval -eq 0 ]
then
log_success_msg "Rsync Stop" #调用停止成功函数。
if test -f "$lock_file_path"
then
rm "$lock_file_path" #删除锁文件。
fi
return $retval
else
log_failure_msg "Rsyncd Stop."
return $retval
fi
else
log_failure_msg "rsync server_pid's process is not running!"
rm "$rsyncd_pid_file_path" #进程号对应的进程未启动,就删除pid文件。并提示
fi
else
log_failure_msg "Rsync server PID file is null or not exist!" #进程号不存,提示
return 1
fi
}
case "$1" in
start)
start
retval=$?
;;
stop)
stop
retval=$?
;;
restart)
stop
sleep 2
start
retval=$?
;;
*)
echo $"Usage:$0 {start|stop|restart}"
exit 1
esac
exit $retvalNginx启动脚本解析
#!/bin/bash
# chkconfig: 2345 21 81
# description: nginx service start and stop scripts
# Author: Felix
# Organization:
###################################################
# File Name: 2.sh
# Created Time: 2019年12月30日 星期一 13时52分38秒
# Version: V1.0
# Author: Felix
# Organization: 360JR OPS
###################################################
#加载自带函数库
[ -f /etc/rc.d/init.d/functions ] && source /etc/rc.d/init.d/functions
#程序锁文件,用来判断程序是否启动
lockdir='/var/lock/subsys'
lock_file_path="$lockdir/nginx"
installation_site="/application/nginx"
sbin="$installation_site/sbin/nginx"
conf="$installation_site/conf/nginx.conf"
#pid文件
nginx_pid_file_path="$installation_site/logs/nginx.pid"
#成功提示函数
log_success_msg(){
#action为特殊的提示函数,$@为所有参数。
action "SUCCESS! $@" /bin/true
}
#失败提示函数
log_failure_msg(){
action "ERROR! $@" /bin/false
}
start(){
if [ -f $lock_file_path ]
then
exit 0
fi
$sbin -c $conf &> /dev/null
gather=$?
if [ $gather -eq 0 ];then
log_success_msg "Nginx is started."
[ -w $lockdir ] && {
touch $lock_file_path
return $gather
}||{
log_failure_msg "Nginx lockfile denied"
return 1
}
else
log_failure_msg "Nginx startd failed"
return $gather
fi
}
stop(){
if [ -s $nginx_pid_file_path ]
then
nginx_pid=$(cat "$nginx_pid_file_path")
if (kill -0 $nginx_pid &>/dev/null)
then
$sbin -s stop
gather=$?
[ $gather -eq 0 ]&&{
log_success_msg "Nginx Stop"
if [ -f "$lock_file_path" ]
then
rm "$lock_file_path"
fi
return $gather
}||{
log_failure_msg "Nginx Stop"
return $gather
}
else
log_failure_msg "Nginx service has not been started"
rm "$nginx_pid_file_path"
fi
else
log_failure_msg "Nginx service PID file is null or not exist!"
return 1
fi
}
reload(){
$sbin -t &> /dev/null
if [ $? -eq 0 ]
then
kill -HUP $(cat "$nginx_pid_file_path")
log_success_msg "Nginx Reload"
fi
return $?
}
case "$1" in
start)
start
retval=$?
;;
stop)
stop
retval=$?
;;
restart)
stop
sleep 2
start
retval=$?
;;
reload)
reload
retval=$?
;;
*)
echo $"Usage:$0 {start|stop|restart|reload}"
exit 1
esac
exit $retvalC7启动脚本
手动编写脚本,一般会在源码包安装时使用。 systemd有系统和用户区分;系统(/user/lib/systemd/system/)、用户(/etc/lib/systemd/user/).一般系统管理员手工创建的单元文件建议存放在/etc/systemd/system/目录下面;每一个服务以.service结尾,一般会分为3部分:[Unit]、[Service]和[Install]
vim /usr/lib/systemd/system/服务名.service
脚本的内容格式
[Unit]:服务的说明模块
Description:描述服务
Documentation=man:sshd(8) man:sshd_config(5) :文档列表说明
After:服务依赖类别说明
Wants=sshd-keygen.service:可选的依赖服务
[Service]服务运行参数的设置
Type=forking是后台运行的形式
PIDFile为存放PID的文件路径
EnvironmentFile=/etc/sysconfig/sshd环境变量等的配置文件
ExecStart为服务的具体运行命令
ExecReload为重启命令
ExecStop为停止命令
PrivateTmp=True表示给服务分配独立的临时空间
注意:启动、重启、停止命令全部要求使用绝对路径
[Install]服务安装的相关设置,可设置为多用户
WantedBy=multi-user.target这里为设置多用户级别。可为空格分隔的列表, 表示在使用 systemctl enable 启用此单元时, 将会在对应的目录设置对应文件的软连接/etc/systemd/system/multi-user.target.wants/目录下新建一个/usr/lib/systemd/system/nginx.service 文件的链接。想对应,可以用 disable 把它从 wants 目录给删除附录:
- Type=simple(默认值):systemd认为该服务将立即启动。服务进程不会fork。如果该服务要启动其他服务,不要使用此类型启动,除非该服务是socket激活型。
- Type=forking:systemd认为当该服务进程fork,且父进程退出后服务启动成功。对于常规的守护进程(daemon),除非你确定此启动方式无法满足需求,使用此类型启动即可。使用此启动类型应同时指定 PIDFile=,以便systemd能够跟踪服务的主进程。
- Type=oneshot:这一选项适用于只执行一项任务、随后立即退出的服务。可能需要同时设置 RemainAfterExit=yes 使得 systemd 在服务进程退出之后仍然认为服务处于激活状态。
- Type=notify:与 Type=simple 相同,但约定服务会在就绪后向 systemd 发送一个信号。这一通知的实现由 libsystemd-daemon.so 提供。
- Type=dbus:若以此方式启动,当指定的 BusName 出现在DBus系统总线上时,systemd认为服务就绪。
编写php-fpm的启动脚本
- 创建php-fpm.service 脚本文件
vim /usr/lib/systemd/system/nginx.service - 编写脚本内容
[Unit]
Description=php
After=network.target remote-fs.target nss-lookup.target
[Service]
Type=forking
ExecStart=/usr/local/php/sbin/php-fpm
[Install]
WantedBy=multi-user.targetPPTP安装脚本
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# Check if user is root
[ $(id -u) != "0" ] && { echo -e "\033[31mError: You must be root to run this script\033[0m"; exit 1; }
clear
#文件不存在则执行安装
[ ! -e '/usr/bin/curl' ] && yum -y install curl
#获取公网IP
VPN_IP=`curl ipv4.icanhazip.com`
#网关
VPN_LOCAL="192.168.0.150"
#地址池
VPN_REMOTE="192.168.0.151-200"
#输入内容不为空则跳出循环
while :; do echo
read -p "Please input UserName: " VPN_USER
[ -n "$VPN_USER" ] && break
done
#输入内容不为空则跳出循环
while :; do echo
read -p "Please input PassWord: " VPN_PASS
[ -n "$VPN_PASS" ] && break
done
clear
#判断是文件是否存在&&过滤出的字符串长度是否为0。如果不为0就是C7系统
#if [ -f /etc/redhat-release -a -n "`grep ' 7\.' /etc/redhat-release`" ];then
#判断是文件是否存在&&过滤出的字符串长度是否为0。如果不为0就是C6系统
[ -f /etc/redhat-release -a -n "`grep ' 6\.' /etc/redhat-release`" ];then
C7(){
#CentOS_REL=7 安装epel源
if [ ! -e /etc/yum.repos.d/epel.repo ];then
cat > /etc/yum.repos.d/epel.repo << 'EOF'
[epel]
name=Extra Packages for Enterprise Linux 7 - $basearch
#baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch
failovermethod=priority
enabled=1
gpgcheck=0
EOF
fi
#安装依赖包,和iptables
for Package in wget make openssl gcc-c++ ppp pptpd iptables iptables-services
do
yum -y install $Package
done
[ $? -ne 0 ] && exit 1
#开启防火墙转发功能
echo 'net.ipv4.ip_forward = 1' >> /etc/sysctl.conf
}
C6(){
#CentOS_REL=6
for Package in wget make openssl gcc-c++ iptables ppp
do
yum -y install $Package
done
[ $? -eq 0 ] && {
sed -i 's@net.ipv4.ip_forward.*@net.ipv4.ip_forward = 1@g' /etc/sysctl.conf
rpm -Uvh http://poptop.sourceforge.net/yum/stable/rhel6/pptp-release-current.noarch.rpm
yum -y install pptpd
}
return $?
}
es(){
echo -e "\033[31mDoes not support this OS, Please contact the author! \033[0m"
exit 1
}
conf(){
if [ $? -eq 0 ]
echo "1" > /proc/sys/net/ipv4/ip_forward
sysctl -p /etc/sysctl.conf
#pptpd.conf配置
# Local IP address of your VPN server
[ -z "`grep '^localip' /etc/pptpd.conf`" ] && echo "localip $VPN_LOCAL" >> /etc/pptpd.conf
#Scope for your home network
[ -z "`grep '^remoteip' /etc/pptpd.conf`" ] && echo "remoteip $VPN_REMOTE" >> /etc/pptpd.conf
[ -z "`grep '^stimeout' /etc/pptpd.conf`" ] && echo "stimeout 172800" >> /etc/pptpd.conf
#dns配置
if [ -z "`grep '^ms-dns' /etc/ppp/options.pptpd`" ];then
cat >> /etc/ppp/options.pptpd << EOF
ms-dns 223.5.5.5 # Aliyun DNS Primary
ms-dns 114.114.114.114 # 114 DNS Primary
ms-dns 8.8.8.8 # Google DNS Primary
ms-dns 209.244.0.3 # Level3 Primary
ms-dns 208.67.222.222 # OpenDNS Primary
EOF
fi
#账号密码配置
echo "$VPN_USER pptpd $VPN_PASS *" >> /etc/ppp/chap-secrets
}
FiWa(){
ETH=`route | grep default | awk '{print $NF}'`
iptables -F
iptables -X
iptables -Z
#允许22端口
iptables -A INPUT -p tcp -m tcp --dport 22 -j ACCEPT
#允许本地环回口
iptables -A INPUT -i lo -j ACCEPT
#允许pptp端口,针对已经或即将启动的新链接
[ -z "`grep '1723 -j ACCEPT' /etc/sysconfig/iptables`" ] && iptables -I INPUT 1 -p tcp -m state --state NEW -m tcp --dport 1723 -j ACCEPT
#允许47端口
[ -z "`grep 'gre -j ACCEPT' /etc/sysconfig/iptables`" ] && iptables -I INPUT 2 -p gre -j ACCEPT
#只放行关系连接和回应报文,防止攻击
iptables -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
iptables -t nat -A POSTROUTING -o $ETH -j MASQUERADE
iptables -I FORWARD -p tcp --syn -i ppp+ -j TCPMSS --set-mss 1356
service iptables save
sed -i 's@^-A INPUT -j REJECT --reject-with icmp-host-prohibited@#-A INPUT -j REJECT --reject-with icmp-host-prohibited@' /etc/sysconfig/iptables
sed -i 's@^-A FORWARD -j REJECT --reject-with icmp-host-prohibited@#-A FORWARD -j REJECT --reject-with icmp-host-prohibited@' /etc/sysconfig/iptables
service iptables restart
chkconfig iptables on
}
service pptpd restart
chkconfig pptpd on
clear
echo -e "You can now connect to your VPN via your external IP \033[32m${VPN_IP}\033[0m"
echo -e "Username: \033[32m${VPN_USER}\033[0m"
echo -e "Password: \033[32m${VPN_PASS}\033[0m"while
while <条件表达式>
do
命令集
done
while <条件表达式>;do
命令集
done计算器无限循环
#/bin/bash
#1.判断是否为两个参数
while true;do
#如果用户未输入,就一直进行循环。否则跳出循环 进行下面的判断
while true
do
read -p "Please enter two Numbers:" x y
if [ -z $x -o -z $y ]
then
echo "$0 num1 num2 ✔"
else
break
fi
done
#if [ $# -ne 2 ]
# then
# echo "$0 num1 num2 ✔"
# exit 1
#fi
#2.判断参数是否为数字
expr $x + $y + 100 &>/dev/null
if [ $? -eq 0 ]
then
echo "[data ok]:$x $y"
else
echo "请输入两个正确的整数!"
exit 2
fi
#3.开始计算
a=$x
b=$y
echo $a+$b=$((a+b))
echo $a-$b=$((a-b))
echo $a^$b=$((a**b))
if [ $b -eq 0 ]
then
echo "[error] 除数为0,取余和除法不能计算。×"
else
echo $a/$b=$((a/b))
echo $a%$b=$((a%b))
fi
done检查URL是否正常
#/bin/bash
[ -f /etc/init.d/functions ] && . /etc/init.d/functions
usage(){
if [[ ! $1 =~ http://.*$ ]]
then
echo "Usage:$0 http://www.xxx.com"
exit 1
fi
}
check_url(){
wget -q -o /dev/null --spider --tries=1 -T 5 $1
retval=$?
if [ $retval -eq 0 ]
then
action "URL is ok" /bin/true
else
action "URL is no" /bin/false
fi
}
main(){
while true;do
usage $1
check_url $1
sleep 2
done
}
main $*计算从1++到100
1 #!/bin/bash
2 ###################################################
3 # File Name: 1+100.sh
4 # Created Time: Thu 09 Jan 2020 03:23:14 PM CST
5 # Version: V1.0
6 # Author: Felix
7 # Organization: 360JR OPS
8 ###################################################
9 sum=0
10 i=1
11 while [ $i -lt 101 ]
12 do
13 ((sum=$sum+$i)) <==let的话不要加$
14 ((i++))
15 done
16 echo $sum读入文件里的年龄并计算
[root@KFSAMBA ~]# cat age.txt
feichi 20
feichi01 22
feichi02 23
feichi03 24
feichi04 25
[root@KFSAMBA ~]# cat age.sh
#!/bin/bash
###################################################
# File Name: age.sh
# Created Time: Fri 10 Jan 2020 01:02:34 PM CST
# Version: V1.0
# Author: Felix
# Organization: 360JR OPS
###################################################
age=0
while read line <==一行一行读入
do
i=`echo $line | awk -F" " '{print $NF}'` <==通过awk取年龄
((age=$age+$i)) <==计算赋值
done<./age.txt
echo $age生成随机数
使用openssl生成随机密码
openssl rand -base64 20几乎所有Linux发行版都包含openssl。我们可以利用它的随机功能来生成可以用作密码的随机字母字符串,其中后面的数字10和20是指定密码的长度。使用urandom生成随机密码
strings /dev/urandom |tr -dc A-Za-z0-9 | head -c20; echo
- tr -dc 保留哪些字符
$RANDOM: 作用:可以随机生成0~32767之间的整数数字

echo $RANDOM|md5sum|cut -c 1-10|tr "[A-Z0-9]" "[a-z]"
随机数 md5计算 截取1-10 替换数字为字符UUID随机数
cat /proc/sys/kernel/random/uuid使用md5sum生成随机密码
date |md5sum以上是用Linux命令生成随机密码,除此之外还可以使用第三方工具进行生成,如mkpasswd、randpw、pwgen、spw,gpg、xkcdpass等,有兴趣的可以了解一下!mkpasswd命令 mkpasswd命令 是make password的简写。可以随机生成字符串。 安装:
yum install -y expect语法: mkpasswd [选项] [参数] 选项:
- -l:指定长度
- -d:数字的个数
- -c:小写字母个数
- -C:大写字母个数
- -s:特殊字符个数
随机文件生成
[ ! -d felix ] && mkdir -p felix
cd felix/
read -p "How many do I need to create: " x
c=`seq $x`
for n in $c
do
prefix=`date +%N|md5sum| echo $RANDOM|md5sum|cut -c 1-6|tr '[0-9]' '[a-z]'`
touch ${prefix}_felix.html
echo $n
done脚本执行技巧 后台执行脚本 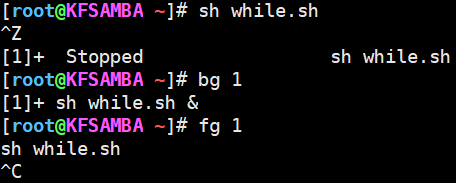 杀死后台脚本
杀死后台脚本 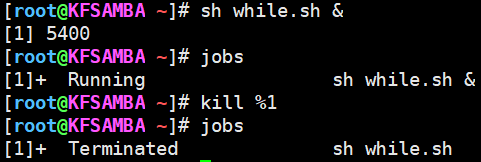
简单的文本处理
随机文件+批量改名
批量创建随机文件
[ ! -d felix ] && mkdir -p felix
cd felix/
read -p "How many do I need to create: " x
c=`seq $x`
for n in $c
do
prefix=`date +%N|md5sum|cut -c 1-6|tr '[0-9]' '[a-z]'`
touch ${prefix}_felix.html
echo $n
done
批量修改文件
方法1:for循环
files=`ls felix/`
cd felix
for file in $files
do
mv $file ${file//felix.html/feieileks.HTML}
done
方法2:rename命令
rename from to towards
例:飞驰.html 改成马飞飞.html
rename 飞驰.html 马飞飞.html *飞驰.html
源文件名 目标文件名 针对哪些文件进行修改
方法3:拼接法
[root@KFSAMBA ~/felix]# ls | awk -F '_' '{print "mv",$0,$1"_felix.html"}' | bash
bcechf_felix.html cfbbbc_felix.html djeaad_felix.html fchafb_felix.html hcgagf_felix.htmlddos防御
思路:查ESTABLISHED并对其进行排序去重,看ESTABLISHED状态下是否有IP大于指定次数。如果大于指定次数就利用防火墙进行屏蔽。
#!/bin/bash
###################################################
# File Name: ctrl_ddos.sh
# Created Time: Tue 14 Jan 2020 02:36:15 PM CST
# Version: V1.0
# Author: Felix
# Organization: 360JR OPS
###################################################
[ -f /etc/init.d/functions ] && . /etc/init.d/functions
log=/tmp/ip.log
pan(){
if [ $1 -eq 0 ]
then
action "$2" /bin/true
else
action "$2" /bin/false
fi
}
defense(){
netstat -na | awk -F'[ :]+' '$NF~/ESTABLISHED/{print $(NF-2)}'|sort|uniq -c|sort -nr|head -10 > $log && echo --operation: $i--
while read line
do
ip=`echo $line|awk '{print $(NF)}'`
zahl=`echo $line|awk '{print $(NF-1)}'`
fw=`iptables -nL|grep -w $ip |wc -l`
if [ $zahl -gt 10 ] && [ $fw -eq 0 ]
then
pan 1 "Source IP: $ip"
iptables -I INPUT -s $ip -j DROP
else
pan 0 "Source IP: $ip"
fi
done<$log
((i++))
}
main(){
while true
do
sleep 5
defense
done
}
while :;do
read -p"是否启动DDOS主动防御 [Y/n] " n
[ -n ${n:=y} ] && break
done
gather=`echo $n|tr [A-Z] [a-z]`
if [ "${gather}" = "y" ]
then
pan 0 "已开启"
main
else
pan 1 "$gather 未识别"
exit 1
fi单词长度判断
#判断句子中的单词是否大于三个字母
log="To be or not to be that is a question"
echo $log
for l in $log
do
if [ ${#l} -le 3 ]
then
echo "这是不大于3个字母的单词"
echo $l
else
echo "这是大于3个字母的单词"
echo $l
fi
done华为华三交换机配置备份
#!/bin/bash
###################################################
# File Name: back_swcfg.sh
# Created Time: Thu Jan 16 12:27:00 2020
# Version: V2.0
# Author: Felix
# Organization: 360JR OPS
###################################################
[ -f /etc/init.d/functions ] && . /etc/init.d/functions
[ $UID -ne 0 ] && echo "Please use the root account!" && exit 1
pan(){
if [ $1 -eq 0 ]
then
action "$2" /bin/true
else
action "$2" /bin/false
fi
}
sw=(`seq 1 16` `seq 31 47` 61 `seq 63 76`)
date=`date +%F`
net="10.93.130."
logfile="/cfgdata/backup_cfg.log"
cfgname="startup.cfg"
mkdir -p /cfgdata/$date
echo -e 'SAMBA:\\\10.93.131.251\SWCFG USER:zjadmin PASS:591740 \nAutomatic backup every Friday morning at 1:30 a.m\n' > $logfile
echo "The SWCFG backup situation:" >> $logfile
for i in ${sw[@]}
do
sshpass -p admin=h3c scp admin@${net}${i}:flash:/$cfgname /cfgdata/$date/${net}${i}_$cfgname
cfg_file="/cfgdata/$date/${net}${i}_$cfgname"
if [ -f $cfg_file ]
then
pan 0 "$cfg_file BACKUP"
echo "$cfg_file BACKUP [OK]" >> $logfile
else
pan 1 "$cfg_file BACKUP"
echo "$cfg_file BACKUP [BAD!]" >> $logfile
fi
done
find /cfgdata/ -type d -mtime +30 | xargs rm -rf
mail -s "$(date +%S_%T) ZJSW Configuration file backup report!" liwenjie@360jinrong.net < $logfile
mail -s "$(date +%S_%T) ZJSW Configuration file backup report!" yaofeichi-jk@360jinrong.net < $logfile循环状态控制

随机MD5破解 f4cb084dc0 <==破解这个
f4cb084dc0 <==破解这个
原理:$RANDOM可以随机生成0~32767
利用seq进行生成seq 0 32767
利用md5进行加密运算并前1-10位和源字符串进行比对
echo "计算中..."
for x in `seq 0 32767`
do
pass=`echo $x|md5sum|cut -c 1-10` <==此处有小问题
if [ "$pass" == "f4cb084dc0" ]
then
echo "Calculate the number to be $x!"
break
fi
done正解:
echo "计算中..."
for x in `seq 0 32767`
do
pass=`echo $x|md5sum`
if [[ $pass =~ ^.*f4cb084dc0.*$ ]] #正则匹配
then
echo "Calculate the number to be $x!"
break
fi
done数组
#数组改编判断单词长度
array=(1 2 3 4 5)
log=(To be or not to be that is a questio)
i=0
while [ $i -lt ${#log[@]} ]
do
if [ ${#log[i]} -le 3 ]
then
echo "此单词 ${log[i]},小于等于3"
else
echo "此单词 ${log[i]},大于3"
fi
((i++))
done
length=(To be or not to be that is a questio)
echo "${length[*]}"
for((i=0;i<${#length[*]};i++))
do
if [ ${#length[i]} -ge 3 ]
then
echo "${length[i]}"
fi
done
#检查url
#!/bin/bash
[ -f /etc/init.d/functions ] && . /etc/init.d/functions
url_arr=(
https://www.baidu.com/
https://www.qq.com/
https://www.jd.com/
)
pan(){
if [ $1 -eq 0 ]
then
action "$2" /bin/true
else
action "$2" /bin/false
fi
}
check_url(){
wget -q -o /dev/null --spider --tries=1 -T 5 $1
retval=$?
if [ $retval -eq 0 ]
then
pan 0 "$1"
else
pan 1 "$1"
fi
}
loop(){
for url in $@
do
check_url $url
sleep 2
done
}
main(){
while :;do
loop ${url_arr[*]}
done
}
main定时任务
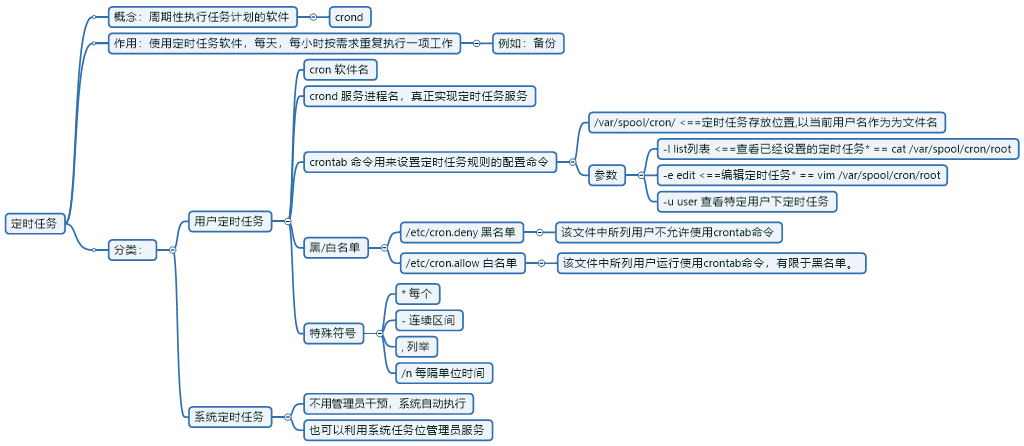 用户的定时任务
用户的定时任务
cron定时任务的软件名crond服务进程名crontab命令是用来设置定时任务规则的配置命令
语法:
[root@lihuaning ~]# cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# ---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * (command to be executed)共6列:
- 分钟(0-59)
- 小时(0-23)
- 日(1-31)
- 月(1-12)
- 周(0-6)
- 要执行的命令或程序 特殊字符:
- * <==每,每个
- 00 23 * * * cmd <==每天的23:00执行cmd
- - <==连续的区间
- 00 8-23 * * * cmd <==每天的8:00 9:00 ...23:00 执行cmd
- 列举 1,2,5,8
- 00 1,2,5,8 * * * cmd <==每天的1:00,2:00,5:00,8:00执行cmd
- /n n任意数字 每隔n单位时间
- 00 */10 * * * cmd <==每隔10小时执行cmd
方法论:大象放冰箱分三步 a.命令行执行成功 b.配置定时任务 crontab -e c.检查
练习:
- 让服务器每5分钟和互联网时间做一次同步
- 每天晚上0带你把站点目录/var/www/html下的内容打包备份到/data目录下,并生成不同的备份名称
解答:
[root@lihuaning ~]# crontab -l
*/5 * * * * /usr/sbin/ntpdate ntp1.aliyun.com &>/dev/null == >/dev/null 2>&1 <==防止生成的小文件占用inode
00 00 */1 * * /usr/bin/tar -czf /root/www_$(date +%F).tar.gz /root/felix &>/dev/null
报错日志:cat /var/log/cron
Oct 15 23:08:01 lihuaning CROND[2483]: (root) CMD (/usr/bin/tar -czf /root/www_$(date +)
原因:定时任务对于%的要求,需要\转义正确答案:
*/1 * * * * /usr/bin/tar -czf /root/www_$(date +\%F\%T).tar.gz /root/felix &> /dev/null优秀答案:
1.命令行执行
cd /root
/usr/bin/tar -czf /root/www_$(date +\%F\%T).tar.gz ./felix
2.尽量用脚本文件实现
[root@lihuaning ~]# mkdir /server/scripts -p <==建立专门存放脚本的目录
[root@lihuaning ~]# cd /server/scripts/
[root@lihuaning scripts]# vim bak.sh <==编写备份脚本
cd /root
/usr/bin/tar -czf /root/www_$(date +%F_%T).tar.gz ./felix
[root@lihuaning scripts]# /bin/sh /server/scripts/bak.sh <==/bin/bash 作用是不需要额外再给脚本加上执行权限
编写定时任务
*/1 * * * * /bin/sh /server/scripts/bak.sh &> /dev/null系统定时任务计划
- 不用管理员干预,系统自动执行。
- 也可以利用系统任务位管理员服务。
[root@lihuaning ~]# ll /var/log/messages* <==系统的日志
-rw------- 1 root root 88198 2019-10-15 20:52 /var/log/messages
-rw------- 1 root root 785720 2019-09-22 03:41 /var/log/messages-20190922
-rw------- 1 root root 1762523 2019-09-29 03:42 /var/log/messages-20190929
-rw------- 1 root root 240134 2019-10-07 03:17 /var/log/messages-20191007
-rw------- 1 root root 153081 2019-10-13 03:25 /var/log/messages-20191013
[root@lihuaning ~]# ll /var/log/secure* <==系统安全日志
-rw------- 1 root root 2728 2019-10-15 20:52 /var/log/secure
-rw------- 1 root root 3869 2019-09-21 17:10 /var/log/secure-20190922
-rw------- 1 root root 2940 2019-09-29 03:05 /var/log/secure-20190929
-rw------- 1 root root 2580 2019-10-07 00:01 /var/log/secure-20191007
-rw------- 1 root root 4750 2019-10-12 18:05 /var/log/secure-20191013
[root@lihuaning ~]# ll /etc/cron.daily/logrotate /etc/logrotate.conf
-rwx------. 1 root root 180 2013-07-31 19:46 /etc/cron.daily/logrotate
-rw-r--r--. 1 root root 662 2013-07-31 19:46 /etc/logrotate.conf
按天切割日志,就可以用logrottate常见错误
- No space left on device **原因:**磁盘满的报错,往往是inode被占满了。(df -i) **诱因:**因为定时任务结尾没添加:&> /dev/null,导致定时任务执行的时候把输出部分给系统(root)发邮件。系统邮件服务postfix默认不开,这些给系统发的邮件就会堆在临时目录(大量小文件堆积)
C5 /var/spool/clientmqueue/
C6 C7 /var/spool/postfix/maildrop/- 定时任务手动可以执行,但是放定时任务中不执行。 export变量生产案例 现象:登陆后怎么操作命令都对,但是命令就是放到定时任务不行。 原因:定时任务在执行脚本的时候,多数情况没办法加载环境变量,特别是(/etc/profile)中所定义的变量。 **本质原因:**bash的登陆方式
- 手工登录,加载所有环境变量(/.bash_profile,~/.bash_rc,/etc/profile,/etc/bashrc)。
- 定时任务执行脚本属于非登陆状态(/etc/bashrc)。
由于大部分运维都会把变量放到此文件/etc/profile,把这个文件里的变量定义在执行的脚本中进行 重新定义即可。而在crond执行Shell时只能识别位数不多的系统环境变量,普通环境变量一般是无法识别的,如果在编写的脚本中需要使用环境变量,最好使用exprot重新声明一下该变量,以确保脚本正确执行。
编写例子
命令实例1:*/1 * * * * /bin/sh /scripts/data.sh
在本例中除了数字与命令脚本外,还使用到了符号"*",*号的意思“每一”。
第一列的意思为分钟,特殊符号“/”表示每隔的意思,即表示每隔一分钟执行/bin/sh /scripts/data.sh程序。
命令实例2:30 3,12 * * * /bin/sh /scripts/oldboy.sh
在本例中,第一列为30,表示30分钟;第二列为 3,12,这代表3点及 12点,此定时任务的意思是每天凌晨3点和中午12点的半点时刻(或描述为每天凌晨3:30和中午12:30)执行/scripts/oldboy.sh脚本。
命令实例3:30 */6 * * * /bin/sh /scripts/oldboy.sh
在本例中,第一列为30,表示30分钟;第二列*/6代表每6个小时,也相当于 6、12、18、24 的作用。此定时任务的意思是每隔6个小时的半点时刻执行/scripts/oldboy.sh脚本任务。
命令实例4:30 8-18/2 * * * /bin/sh /scripts/oldboy.sh
在本例中,其中的第一列为30,表示30分钟;第二列8-18/2代表在早晨8点到下午18点之间每隔2小时,也相当于把8、10、12、14、16、18单独列出。
那么,此定时任务的意思就是早晨8点到下午18点之间,每隔2小时的半点时刻执行/scripts/oldboy.sh脚本任务。
命令实例5:30 21 * * * /application/apache/bin/apachectl graceful
本例表示每晚的21:30重启apache。
命令实例6:45 4 1,10,22 * * /application/apache/bin/apachectl graceful
本例表示每月1、10、22日的凌晨4 : 45分重启apache。
命令实例7:10 1 * * 6,0 /application/apache/bin/apachectl graceful
本例表示每周六、周日的凌晨1 : 10分重启apache。
命令实例8:0,30 18-23 * * * /application/apache/bin/apachectl graceful
本例表示在每天18 : 00至23 : 00之间每隔30分钟重启apache。
命令实例9:00 */1 * * * /application/apache/bin/apachectl graceful
本例表示每隔一小时整点重启apache
命令实例10:* 23,00-07/1 * * * /application/apache/bin/apachectl graceful
本例并不表示晚上23点和早上0-7点之间每隔一小时重启Apache。
要说明的是,以上结果是不规范的,也是不对的。大家想想为什么?
以上定时任务的第一列为*,表示每分都执行任务即晚上23点和早上0-7点之间每隔一小时的每分都重启Apache,很可怕吧。
命令实例11:00 11 * 4 1-3 /application/apache/bin/apachectl graceful
本例表示4月的每周一到周三的上午11点整重启Apache。
命令实例12:30 09 * * 0 去做兼职
本例表示每周日上午9:30去做兼职。
命令实例13:00 10 * * * 去国政中心上班
本例表示每上午10:00去国政中心上班。磁盘和存储
存储介绍
SCSI比喻成驴,SATA比喻为马,SAS比喻为骡子,骡子既不爱得病,力气又大。因此SAS比SATA、SCSI的综合情况要更优秀。
SAS是新一代的SCSI技术,和现在流行的Serial ATA(SATA)磁盘相同,都是采用串行技术以获得更高的传输速度 SAS优势:
- SAS技术降低了磁盘阵列的成本
- 串行接口让传输性能提高
- 扩展性更好
- 安装简单,可以热插拔
- 兼容性好,兼容SATA
对比:
- 企业生产场景普及程度:SAS>SSD>SATA
- 单位容量对比性能和价格:SSD>SAS>SATA(一块SSD和一块SATA)
- 单位价格购买磁盘容量:SATA>SAS>SSD
光纤通道 作用:光纤通道磁盘是为了提高磁盘存储系统的速度和灵活性才开发的,它的出现大大提高了多磁盘系统的通信速度。光纤通道是为在像服务器这样的多磁盘系统环境而设计,能满足高端工作站、服务器、海量存储子网络、外设间通过集线器、交换机和点对点连接进行双向、串行数据通讯等系统对高数据传输率的要求。 特性:热拔插性、高速带宽、远程连接、连接设备数量大等。
SSD硬盘: 固态磁盘(Solid State Drive、IDE FLASH DISK)是由控制单元和存储单元(FLASH芯片)组成的。简单说:就是用固态电子存储芯片阵列而制成的磁盘。
分类:
- 基于闪存(FLASH 芯片)的固态磁盘,类似于U盘
- 基于DROM的固态磁盘
接口类型:
- SATA接口:SATA SATA2 SATA3.0
- PATA(IDE接口):IDE44PIN IDE40PIN
- PCI-E接口:mSATA PCIE(IDE) PCIE(SATA)ZIF:ZIF接口等
磁盘选型
企业级SAS硬盘(默认) 常见的SAS硬盘是15000转/分,没有特殊需求默认买SAS硬盘。满足容量的基础上,尽量保持4块磁盘以上。
企业级SATA硬盘 7200-10000转/分,常见容量为1T、2T、4T、6T,优点是经济实惠,容量大,从具体需求和性价比考虑。在工作中多用SATA盘做线下备份(即不提供服务的数据存储或者并发业务访问不是很大的业务应用),比如站点程序及数据库、图片的线下备份等 适用场景:没钱、数据量少、数据不给用户提供服务、用于备份
小结:
- 线上业务,用SAS磁盘
- 线下业务,用SATA磁盘,磁带库
- 线上高并发,小容量业务,SSD磁盘
- 成本思想:根据数据的访问热度,智能分析分层存储。SATA+SSD
- SSD固态盘 特点:容量小,价格贵,速度快。一般用于数据量小并且有超大规模高并发的业务(这不是唯一的办法,还可以通过磁盘加内存缓存的技术方式解决这个大规模并发问题。)
百度、腾讯、360核心业务都会采用SSD磁盘,应用层也必须会在项目架构层面做各种缓存。 大公司如淘宝,某些业务可能会根据数据的热度来综合使用分层存储,以达到性价比最佳的情况。
服务器默认的RAID板卡,一般只支持:0和1 如果是独立RAID板卡,一般支持:0、1、5、10等常见级别
RAID
什么是Raid? Raid是廉价冗余磁盘阵列( Redundant Array of Inexpensive Disk)的简称,有时也简称磁盘阵列( Disk Array)Raid是一种把多块独立的物理磁盘按不同的技术方式组合起来形成一个磁盘组,在逻辑上(做完RAID,装系统后)看起来就是一块大的磁盘,可以提供比单个物理磁盘更大的存储容量或更高的存储性能,同时又能提供不同级别数据冗余备份的一种技术。
Raid级别介绍 把多个物理磁盘通过不同的技术方式组成磁盘阵列,这个不同的技术方式就被称为 RAID级别
- Raid级别一般有:Raid0、Raid1、Raid2、Raid3、Raid4、Raid5,Raid6、Raid7、Raid0+1(即Raid10)、Raid53等
- 生产环境常用Raid级别:Raid0,Raid1,Raid5,Raid10。
冗余:冗余,指重复配置系统的一些部件,当系统发生故障时,冗余配置的部件介入并承担故障部件的工作,由此减少系统的故障时间 Redundant,自动备援,即当某一设备发生损坏时它可以自动作为后备式设备替代该设备。
RAID分类:
软RAID技术(退出历史舞台) 在Linuⅸ下在安装系统过程中或者安装系统后通过自带的软件就能实现软RAID功能使用软RAID可省去购买昂贵的硬件RAID控制器和附件就能极大地增强磁盘的IO性能和可靠性。由于是用软件去实现的RAID功能,所以它配置灵活、管理方便。同时使用软件RAID,还可以实现将几个物理磁盘合并成一个更大的虚拟设备,从而达到性能改进和数据冗余的目的。
硬RAID技术 基于硬件的RAID解决方案比基于软件RAID技术在使用性能和服务性能上会更胜筹,具体表现在检测和修复多位错误的能力、错误磁盘自动检测和阵列重建等方面。从安全性上考虑,基于硬件的RAID解决方案也是更安全的,因此,在实际的生产场景工作中,基于硬件的RAD解决方案应该是我们的首选。互联网公司常用的生产DELL服务器,默认的就会支持RAID0,1,如果RAID5,10就需要买RAID卡。
LVM全称(Logic Volume Management(Manager))逻辑卷管理,它的最大用途是可以【灵活的管理磁盘的容量】,让磁盘分区可以随意放大或缩小,便于更好的应用磁盘的剩余空间,如果过于强调性能与备份,那么还是应该使用RAID功能,而不是LVM。
LVM是软件实现的,性能一般降低5%-10%。买服务器插满磁盘做好RAID,分区规划好,永远都不需要LVM。 RAID和LVM区别:
- LVM:灵活的管路磁盘容量,有一定的冗余和性能,很弱。
- RAID:更侧重性能和数据安全。
磁盘阵列可以把多个磁盘驱动器通过不同的连接方式连接在一起协同工作,大大提高读取速度,同时把磁盘系统的可靠性提高到接近无错的境界,使其可靠性极高。 用RAID最直接的好处是:
- 提升数据安全性。
- 提升数据读写性能。
- 提供更大的单一逻辑磁盘数据容量存储。
DELLR740使用6块盘实践RAID制作结论
- Raid0支持1块盘到多块盘,容量是所有盘之和。(可靠性最低,坏一块全部坏)
- Raid1只支持2块盘,容量损失一块盘。(镜像)
- Raid5最少三块盘,不管硬盘数量多少,只损失一块盘容量。(奇偶校验)
- Raid6最少4块盘,5块盘也可以,损失2块盘,不管硬盘多少,只损失两块盘容量。
- Raid10最少4块盘,必须偶数硬盘,不管硬盘多少,都损失一半容量,不支持虚拟磁盘。(镜像过后做条带)
RAID0
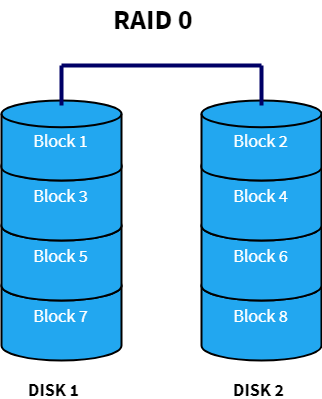 生产应用场景:
生产应用场景:
- 负载均衡集群下面的多个相同RS节点服务器。
- 分布式文件存储下面的主节点或CHUNK SERVER。
- MySQL主从复制的多个Slave服务器。
- 对性能要求很高,对冗余要求很低的相关业务。 以4块做RAID0为例:
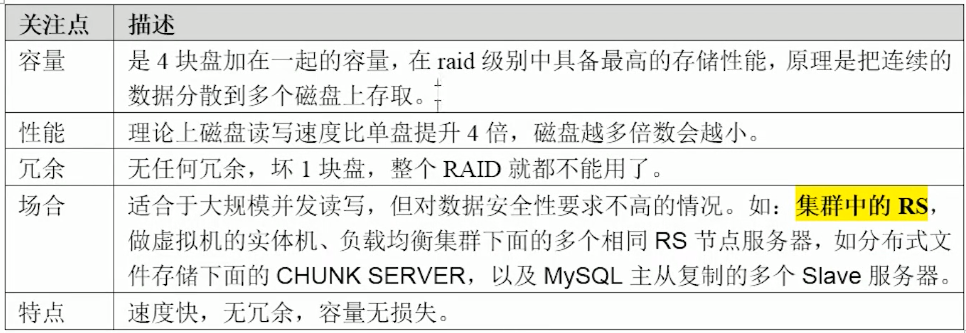
RAID1
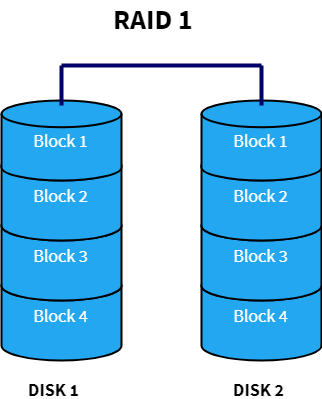
- RAID1又称为Mirror或Mirroring(镜像),它的宗旨是最大限度的保证用户数据的可用性和可修复性。RAID1的操作方式是把用户写入一个磁盘的数据百分之百地自动复制到另外一个磁盘上,从而实现存储双份的数据。
- 要制作RAID1,要求至少是两块磁盘(仅支持2块盘?),整个RAID大小等于两个磁盘中最小的那块磁盘的容量(当然,最好使用同样大小的磁盘),数据有50%的冗余,在存储时同时写入两块磁盘,实现了数据完整备份;但相对降低了写入性能,但是读取数据时可以并发,相当于两块Raid0的读取效率(有待实践验证)。

RAID5
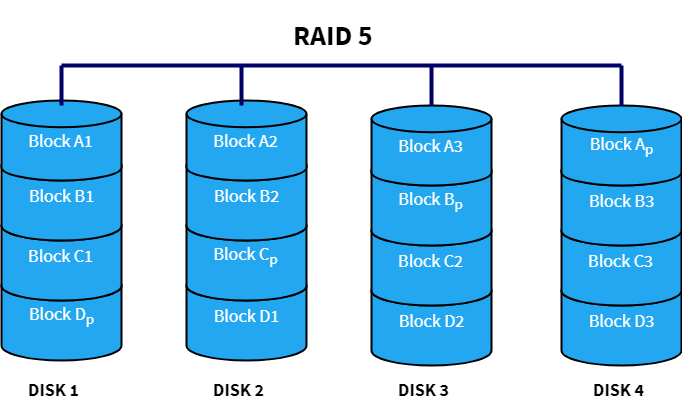
- RAID5是一种存储性能、数据安全和存储成本兼顾(中庸)的存储解决方案。
- RAID5需要三块或以上的物理磁盘,可以提供热备盘实现故障的恢复;采用奇偶校验,可靠性强,且只有同时损坏两块硬盘时数据才会完全损坏,只损坏一块硬盘时,系统会根据存储的奇偶校验位重建数据,临时提供服务;此时如果有热备盘,系统还会自动在热备盘上重建故障磁盘上的数据;
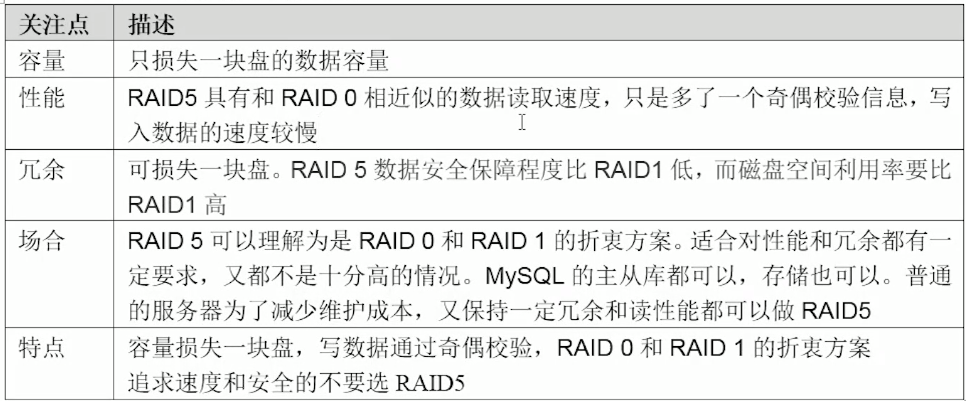
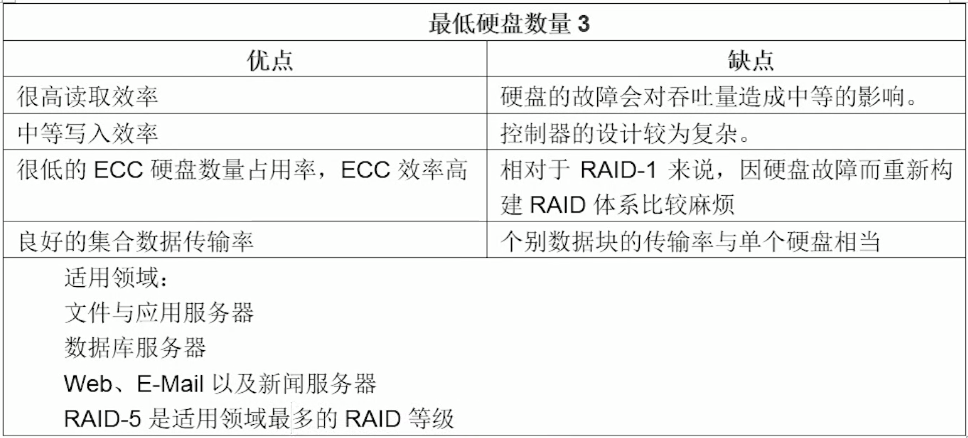
RAID10
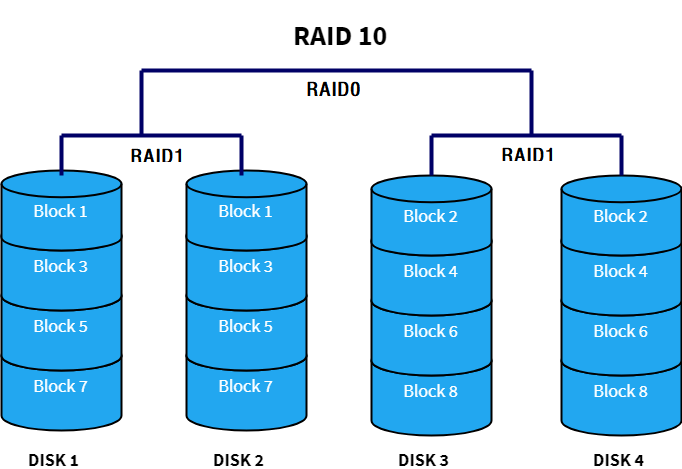 RAID10是先将四块硬盘在纵向上分别两两做镜像,镜像后再在横向上做条带。
RAID10是先将四块硬盘在纵向上分别两两做镜像,镜像后再在横向上做条带。 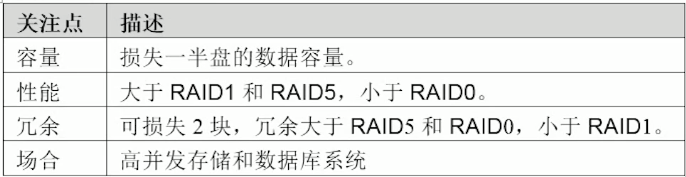 RAID10极端情况下,支持一边坏1块。
RAID10极端情况下,支持一边坏1块。
RAID01
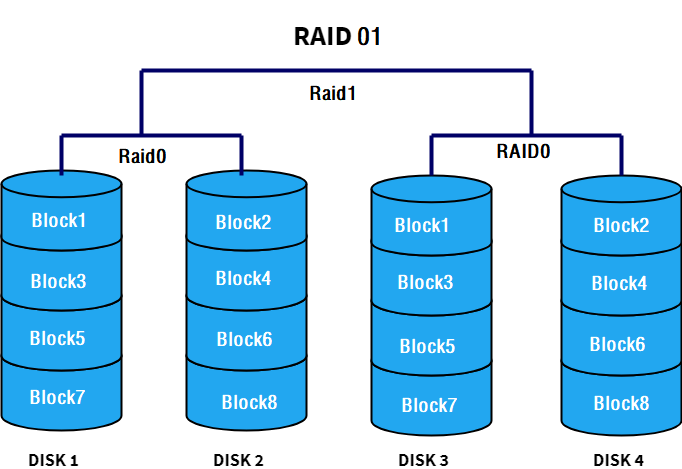 RAID01是先将四块硬盘中横向上分别两两做条带,条带后再在纵向上做镜像。 RAID01极端情况下,支持单边坏2块。
RAID01是先将四块硬盘中横向上分别两两做条带,条带后再在纵向上做镜像。 RAID01极端情况下,支持单边坏2块。
总结:RAID10和RAID01在读和写的性能上没有太大差距,从发生故障的概率上看RAID01远大于RAID10
分区
生产场景分区方案: 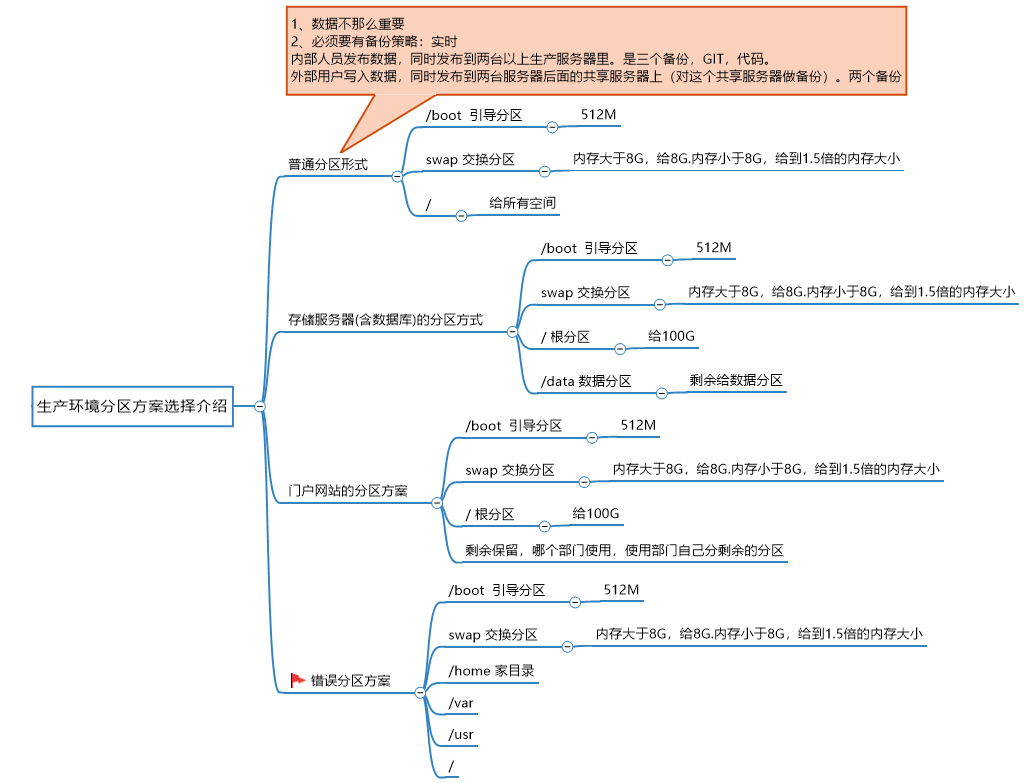
磁盘命名规则:
- IDE: /dev/hda /dev/hdb
- SCSI:/dev/sda /dev/sdb
- NVME:/dev/nvme0n1 nvme1n1 (内核版本3.3开始支持) 分区:
- sda1 sda2 sda3
- nvme0n1p1 nvme0n1p2 nvme0n1p3
磁盘分区的类型:
主分区(primary)
- 系统中必须要存在的分区,系统盘选择主分区安装。
- 数字编号1-4(sda1-sda4)。
- 主分区最多四个,最少一个。
扩展分区(extend)
- 相当于一个独立的小磁盘。
- 拥有独立的分区表。
- 不能独立存在,即不能存放数据。
- 必须在扩展分区上建立逻辑分区能存放数据。
- 占用主分区的编号(主分区+扩展分区)最多4个。
- 扩展分区可以没有,最多一个。
逻辑分区(logic)
- 数字编号从5开始。
- 逻辑分区存放于扩展分区之上。
- 存放任意普通数据。
磁盘分区的工作原理: 磁盘存储逻辑结构图 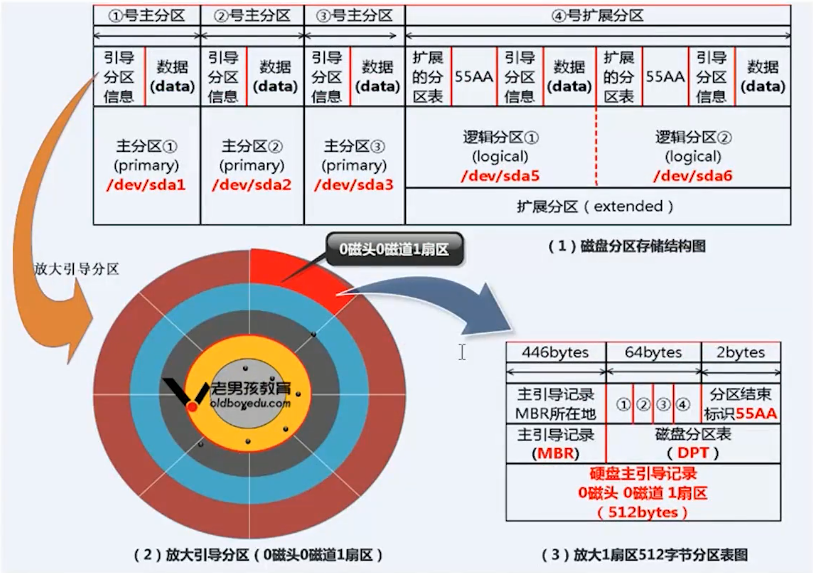
- 磁盘是按柱面分区的
- 磁盘分区登记的地点,磁盘分区表
- 磁盘分区表存放分区是结果信息的(起始柱面-结束柱面)C6精细到了扇区。
- 磁盘分区表存放位置,0磁道(最外围),0磁头(第一个盘面),1扇区。(512字节)。
- 占用1扇区前512字节的最后64字节(分区表),前446字节存放系统引导信息。后两个字节存放分区结束标志(55AA)
- 磁盘分区表容量有限为64字节,一个分区固定占16字节。所以64/16=4个分区(主分区+扩展分区)
磁盘分区的实践: 磁盘分区的本质,就是修改64字节的分区表。(如果是扩展分区,则修改扩展分区独立的分区表)
fdisk
fdisk命令,修改MBR分区表: 既能修改小于2T也能修改大于2T的磁盘.
- fdisk-Partition table manipulator for Linux linux下最常用的分区工具,一般是装完系统后进行分区。装系统之前的分区,多数都是系统ISO里面的工具分,或者raid里分小磁盘。
- fdisk只能root权限用户使用。
- fdisk适合于对装系统后的剩余空间进行分区,例如:安装系统时没有全部分区,或者安装系统后添加新磁盘。
- fdisk 支持mbr分区表(2TB以内),大于2TB的磁盘需要先转换硬盘格式为gpt格式
g参数进行转换。
分区实战:3P+1E(3L) 1 2 3 5 6 7 每个150M
[root@S1 ~]# ll /dev/sd*
brw-rw----. 1 root disk 8, 0 Oct 20 23:59 /dev/sda
brw-rw----. 1 root disk 8, 1 Oct 20 23:59 /dev/sda1
brw-rw----. 1 root disk 8, 2 Oct 20 23:59 /dev/sda2
brw-rw----. 1 root disk 8, 3 Oct 20 23:59 /dev/sda3
brw-rw----. 1 root disk 8, 16 Oct 20 23:59 /dev/sdb
[root@S1 ~]# fdisk -l <==查看分区信息
Disk /dev/sda: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x000ed3d3
Device Boot Start End Blocks Id System
/dev/sda1 * 2048 1050623 524288 83 Linux
/dev/sda2 1050624 5244927 2097152 82 Linux swap / Solaris
/dev/sda3 5244928 41943039 18349056 83 Linux
Disk /dev/sdb: 1073 MB, 1073741824 bytes, 2097152 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
[root@S1 ~]# fdisk /dev/sdb <==对sdb进行分区
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0x8ecef2f8.
Command (m for help): m
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition <==删除一个分区
g create a new empty GPT partition table <==转换硬盘格式为gpt
G create an IRIX (SGI) partition table
l list known partition types <==查看已知的分区类型
m print this menu <==查看分区的帮助信息
n add a new partition <==添加一个新分区
o create a new empty DOS partition table
p print the partition table <==查看分区结果信息
q quit without saving changes <==退出不保存
s create a new empty Sun disklabel
t change a partition's system id<==调整分区类型
u change display/entry units
v verify the partition table
w write table to disk and exit <==保存并退出
x extra functionality (experts only)
Command (m for help): p
Disk /dev/sdb: 1073 MB, 1073741824 bytes, 2097152 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x5faeac4d
Device Boot Start End Blocks Id System
=======================开始创建主分区==========================
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p):
Using default response p
Partition number (1-4, default 1):
First sector (2048-2097151, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151): +150M
Partition 1 of type Linux and of size 150 MiB is set
Command (m for help): n
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): p
Partition number (2-4, default 2):
First sector (309248-2097151, default 309248):
Using default value 309248
Last sector, +sectors or +size{K,M,G} (309248-2097151, default 2097151): +150M
Partition 2 of type Linux and of size 150 MiB is set
Command (m for help): n
Partition type:
p primary (2 primary, 0 extended, 2 free)
e extended
Select (default p): p
Partition number (3,4, default 3):
First sector (616448-2097151, default 616448):
Using default value 616448
Last sector, +sectors or +size{K,M,G} (616448-2097151, default 2097151): +150M
Partition 3 of type Linux and of size 150 MiB is set
=======================开始创建扩展分区==========================
Command (m for help): n
Partition type:
p primary (3 primary, 0 extended, 1 free)
e extended
Select (default e):
Using default response e
Selected partition 4
First sector (923648-2097151, default 923648):
Using default value 923648
Last sector, +sectors or +size{K,M,G} (923648-2097151, default 2097151): <==给剩余全部空间
Using default value 2097151
Partition 4 of type Extended and of size 573 MiB is set
Command (m for help): p
Disk /dev/sdb: 1073 MB, 1073741824 bytes, 2097152 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x5faeac4d
Device Boot Start End Blocks Id System
/dev/sdb1 2048 309247 153600 83 Linux
/dev/sdb2 309248 616447 153600 83 Linux
/dev/sdb3 616448 923647 153600 83 Linux
/dev/sdb4 923648 2097151 586752 5 Extended
=======================开始创建逻辑分区==========================
Command (m for help): n
All primary partitions are in use
Adding logical partition 5
First sector (925696-2097151, default 925696):
Using default value 925696
Last sector, +sectors or +size{K,M,G} (925696-2097151, default 2097151): +150M
Partition 5 of type Linux and of size 150 MiB is set
Command (m for help): n
All primary partitions are in use
Adding logical partition 6
First sector (1234944-2097151, default 1234944):
Using default value 1234944
Last sector, +sectors or +size{K,M,G} (1234944-2097151, default 2097151): +150M
Partition 6 of type Linux and of size 150 MiB is set
Command (m for help): n
All primary partitions are in use
Adding logical partition 7
First sector (1544192-2097151, default 1544192):
Using default value 1544192
Last sector, +sectors or +size{K,M,G} (1544192-2097151, default 2097151):
Using default value 2097151
Partition 7 of type Linux and of size 270 MiB is set
=======================查看结果3P 1E(3L)==========================
Command (m for help): p
Disk /dev/sdb: 1073 MB, 1073741824 bytes, 2097152 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x5faeac4d
Device Boot Start End Blocks Id System
/dev/sdb1 2048 309247 153600 83 Linux
/dev/sdb2 309248 616447 153600 83 Linux
/dev/sdb3 616448 923647 153600 83 Linux
/dev/sdb4 923648 2097151 586752 5 Extended
/dev/sdb5 925696 1232895 153600 83 Linux
/dev/sdb6 1234944 1542143 153600 83 Linux
/dev/sdb7 1544192 2097151 276480 83 Linux
Command (m for help):parted
parted命令,gpt分区格式: 既能修改小于2T也能修改大于2T的磁盘.
 改硬盘格式:
改硬盘格式:parted -s /dev/sdb mklabel gpt/msdos 二选一,大于两T用gpt反之选msdos即mbr 增加分区:parted -s /dev/sdb mkpart primary 581 100%==-1 删除分区:parted -s /dev/sdb rm [分区号] 查看分区:parted -s /dev/sdb p
mkpart PART-TYPE START END PART-TYPE(分区类型)
- primary 主分区
- logical 逻辑分区
- extended 扩展分区
START 设定磁盘分区起始点;可以为0,numberMiB/GiB/TiB;
- 0 设定当前分区的起始点为磁盘的第一个扇区;
- 1G 设定当前分区的起始点为磁盘的1G处开始;
END 设定磁盘分区结束点;
- -1 设定当前分区的结束点为磁盘的最后一个扇区;
- 10G 设定当前分区的结束点为磁盘的10G处;
需求:4块2T盘,RAID5大小6T(RAID5损失了1块盘的容量) 现有一个做了RAID5的硬盘,要求三个分区 硬盘分区总大小: 6.2T /data0 4.8T /data1 1T 400G (无需格式化,作DRBD+Hearbeat+MySQL高可用集群)
[root@S1 ~]# parted /dev/sdb
GNU Parted 3.1
Using /dev/sdb
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) p
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: msdos <==此时文件系统为msdos
Disk Flags:
Number Start End Size Type File system Flags
(parted) mklabel gpt <==修改磁盘为GPT格式[MBR格式为 msdos ]
等价于:parted -s /dev/sdb mklabel gpt <==非交互式磁盘为GPT格式,-s取消提示
Warning: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost. Do you want to
continue?
Yes/No? Y
(parted) p
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt <==修改结果
Disk Flags:
Number Start End Size File system Name Flags
(parted) mkpart primary 0 124 <==新建分区定义起始大小(M)为单位
等价于:parted -s /dev/sdb mkpart primary 0 124
Warning: The resulting partition is not properly aligned for best performance.
Ignore/Cancel? I
(parted) p <==显示分区信息
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 17.4kB 124MB 124MB primary
(parted) mkpart primary 581 -1 <==分配所有剩余空间给第2个分区
等价于:parted -s /dev/sdb mkpart primary 581 100%
(parted) p
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdb: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 17.4kB 580MB 580MB primary
2 581MB 1073MB 492MB primary
(parted) rm 2 <==删除分区2文件系统
文件系统:
- 什么是文件系统?
- 是计算机存储和组织数据的方法或机制。落地是一个软件。
- 为什么需要文件系统?
- 磁盘、物理介质、磁粒子物理元素。硬件需要软件驱动使用,磁盘需要文件系统驱动。
- 文件系统通过磁盘实现管理规划、存取数据。
- 文件系统都有哪些常见种类?
- Windows: NTFS、fat32、msdos
- Linux: ext2、ext3(C5)、ext4(C6)、xfs(C7)
文件系统创建和挂载
mkfs 格式化(的本质创建文件系统)
- -t //指定文件系统
- -b //指定Block大小
- -I //指定Inode大小
[root@S1 ~]# mkfs -t ext4 /dev/sdb1 <==格式化ext4文件系统,本质就是生成一定数量的Inode和Block。等价于mkfs.exts /dev/sdb1
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
25688 inodes, 102400 blocks
5120 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=33685504
13 block groups
8192 blocks per group, 8192 fragments per group
1976 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Allocating group tables: done
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
-----------------------------------------------------------------------------------
[root@S1 ~]# mkfs -t ext4 -b 4096 -I 512 /dev/sdb1 <==指定Inode和Block大小
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
25600 inodes, 25600 blocks
1280 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=27262976
1 block group
32768 blocks per group, 32768 fragments per group
25600 inodes per group
Allocating group tables: done
Writing inode tables: done
Creating journal (1024 blocks): done
Writing superblocks and filesystem accounting information: done
[root@S1 ~]# dumpe2fs /dev/sdb1 | egrep -i "size" <==检查结果
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Block size: 4096
Fragment size: 4096
Group descriptor size: 64
Flex block group size: 16
Inode size: 512
Required extra isize: 28
Desired extra isize: 28
Journal size: 4096k
-----------------------------------------------------------------------------------mount
- -t 指定文件类型
- -o 挂载的选项[rw,remount]
- -a 挂载所有磁盘
[root@S1 ~]# mount -t ext4 /dev/sdb1 /mnt/ <==挂载文件系统
[root@S1 ~]# df -h
[root@S1 ~]# cat /proc/mounts <==查看挂载状态
[root@S1 ~]# umount -lf /mnt/ <==强制卸载
[root@S1 ~]# mount /dev/sdb2 /mnt/ <==没有格式化,没法挂载。
mount: /dev/sdb2 is write-protected, mounting read-only
mount: unknown filesystem type '(null)'
xfs格式化sdb2
[root@S1 ~]# mkfs.xfs /dev/sdb2
meta-data=/dev/sdb2 isize=256 agcount=4, agsize=59072 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=236288, imaxpct=25
= sunit=0 swidth=0 blks
naming=version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=853, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@S1 ~]# mount /dev/sdb2 /mnt/开机自动挂载
方法一:
[root@S1 ~]# blkid <==查看设备属性 UUID fstype
/dev/sda1: UUID="4b292773-2b2d-4f7d-807c-ba025a45dc58" TYPE="xfs"
/dev/sda2: UUID="3fc4e794-5e50-437e-87e1-1e692621df3c" TYPE="swap"
/dev/sda3: UUID="4664ec93-5655-4d88-80cd-aec984aaf857" TYPE="xfs"
/dev/sdb1: UUID="360280b7-4a46-4e11-843d-d97e62cfe3bc" TYPE="ext4"
/dev/sdb2: UUID="814731d0-a1ca-48fc-9522-8cf3eae33c8a" TYPE="xfs"
#
# /etc/fstab
# Created by anaconda on Wed Oct 9 11:54:43 2019
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
UUID=4664ec93-5655-4d88-80cd-aec984aaf857 / xfs defaults 0 0
UUID=4b292773-2b2d-4f7d-807c-ba025a45dc58 /boot xfs defaults 0 0
UUID=3fc4e794-5e50-437e-87e1-1e692621df3c swap swap defaults 0 0
设备 挂载点 文件系统类型 默认挂载选项 是否备份 是否开机磁盘检查
defaults
Use default options: rw, suid, dev, exec, auto, nouser, and async.
UUID=814731d0-a1ca-48fc-9522-8cf3eae33c8a /mnt xfs defaults 0 0 <==开机挂载
mount -a <==实现fstab中的配置文件立刻生效
方法二:
/usr/bin/mount -t xfs /dev/sdb2 /mnt <==为临时挂载,可将其放入/etc/rc.local,也可实现自动挂载。文件系统修复
查看ext文件系统的内部细节:
[root@S1 ~]# dumpe2fs /dev/sdb1
Inode count: 25688
Block count: 102400 <==inode block数量
Block size: 1024 <==Block大小 1k
Inode size: 128 <==Inode大小
[root@S1 ~]# fsck #检查并修复Linux⽂件系统
fsck fsck.btrfs fsck.cramfs fsck.ext2 fsck.ext3 fsck.ext4 fsck.minix fsck.xfs注意:
- 正常的磁盘不能操作
- 操作时要卸载
参数:
- -a非互交模式,自动修复
- -c检查是否存在有损坏的区块。
- -C fsck.ext3命令会把全部的执行过程,都交由其逆向叙述,便于监控程序
- -d详细显示命令执行过程
- -f强制进行检查
- -F检查文件系统之前,先清理该保存设备块区内的数据
- -l把文件中所列出的损坏区块,加入标记
- -L清除所有损坏标志,重新标记
- -n非交互模式,把欲检查的文件系统设成只读
- -P 设置fsck.ext2命令所能处理的inode大小为多少
- -r交互模式
- -R忽略目录
- -s顺序检查
- -S效果和指定“-s”参数类似
- -t 显示fsck.ext2命令的时序信息。
- -v显示详细的处理过程
- -y关闭互动模式
选择参数:
- -b指定分区的第一个磁区的起始地址/Super Block
- -B 设置该分区每个区块的大小
- -I设置欲检查的文件系统,其inode缓冲区的区块数目
- -V显示版本信息
[root@S1 ~]# xfs_repair /dev/sdb2 检查和修复xfs文件系统
救援模式
当系统磁盘挂载项写入fstab中,此时机器重启了。但是盘被拔出来或者磁盘的文件系统损坏无法挂载时,系统会开不开机。这个时候就要进入救援模式吧fstab中的挂载项注释掉。
- grub菜单按e键,找到如下位置。
 2. 修改为:
2. 修改为:
 3. Ctrl+x执行:
3. Ctrl+x执行:
 执行
执行chroot sysroot获取root权限。 vi 编辑fstab exec /sbin/init 重启OK
同样适用单用户模式找回root密码 如果开启了selinux 还需要执行 touch /.autorelabel <==selinux在重启后更新label(既selinux安全上下文 其中包含:SELinux用户、SELinux角色、类型、安全级别)