
通过filebeat读取日志后传送至logstash进行处理,处理完成再保存在elasticsearch中。其中最重要的一步就是logstash的处理,我们需要根据日志的格式编写相关的匹配代码,以便logstash进行匹配处理。
在这里我使用过滤插件中的Grok插件,具体技术文档请点击以下链接: https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
在编写grok捕获规则时,可以使用以下网站进行辅助: https://grokdebug.herokuapp.com/
相关的语法可以参考以下GitHub页面: https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
Logstash Reference [7.12] » Filter plugins https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
nginx日志分析
'$remote_addr - $remote_user [$time_local] "$request" $http_host $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for" "$upstream_addr" "$upstream_status" $upstream_cache_status "$upstream_http_content_type" "$upstream_response_time" > $request_time'110.110.110.110 - - [18/Jun/2020:18:36:51 +0800] "GET /forward/61316209.html HTTP/1.1" cakepanit.com 200 158441 "https://cakepanit.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36" "120.120.120.120" "127.0.0.1:8080" "200" MISS "text/html; charset=UTF-8" "1.884" > 2.189字段分析: 用以记录客户端的ip地址: $remote_addr 110.110.110.110
用以记录短破折号,无意义-
用来记录客户端用户名称(Nginx用户认证): $remote_user -
用来记录访问时间与时区: $time_local [18/Jun/2020:18:36:51 +0800]
用来记录请求的url与http协议: $request "GET /forward/61316209.html HTTP/1.1"
用来记录请求地址: $http_host cakepanit.com
用来记录请求状态成功是200: $status 200
记录发送给客户端文件主体内容大小: $body_bytes_sent 158441
用来记录从那个页面链接访问过来的: $http_referer "https://cakepanit.com/"
记录客户端浏览器的相关信息: $http_user_agent "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.98 Safari/537.36"
记录前端代理时HTTP 客户端的真实 IP $http_x_forwarded_for "-"
记录后台upstream的地址,即真正提供服务的主机地址(可能为多个) $upstream_addr "127.0.0.1:8080"
记录upstream状态(可能为多个) $upstream_status "200"
记录是否命中缓存 $upstream_cache_status MISS
记录页面类型 $upstream_http_content_type "text/html; charset=UTF-8"
记录从Nginx向后端建立连接开始到接受完数据然后关闭连接为止的时间/s(可能为多个) $upstream_response_time "1.884"
记录从接受用户请求的第一个字节到发送完响应数据的时间/s $request_time 2.189
筛选处理
输入和输出在logstash配置中是很简单的一步,而对数据进行匹配处理则显得异常复杂。匹配当行日志是入门水平需要掌握的,而多行甚至不规则的日志则可能需要ruby的协助。
%{IPORHOST:client_ip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} \"(%{GREEDYDATA:referrer})\" \"(%{GREEDYDATA:user_agent})\" \"(%{IP:x_forword}|%{GREEDYDATA:x_forword})\" \"(%{GREEDYDATA:upstream_host})\" \"(%{GREEDYDATA:upstream_host_status})\" (%{WORD:upstream_cache_status}|-) \"%{GREEDYDATA:upstream_content_type}\" \"(%{GREEDYDATA:upstream_response_time})\" > %{NUMBER:request_time:float}输入和输出在logstash配置中是很简单的一步,而对数据进行匹配处理则显得异常复杂。匹配当行日志是入门水平需要掌握的,而多行甚至不规则的日志则可能需要ruby的协助。 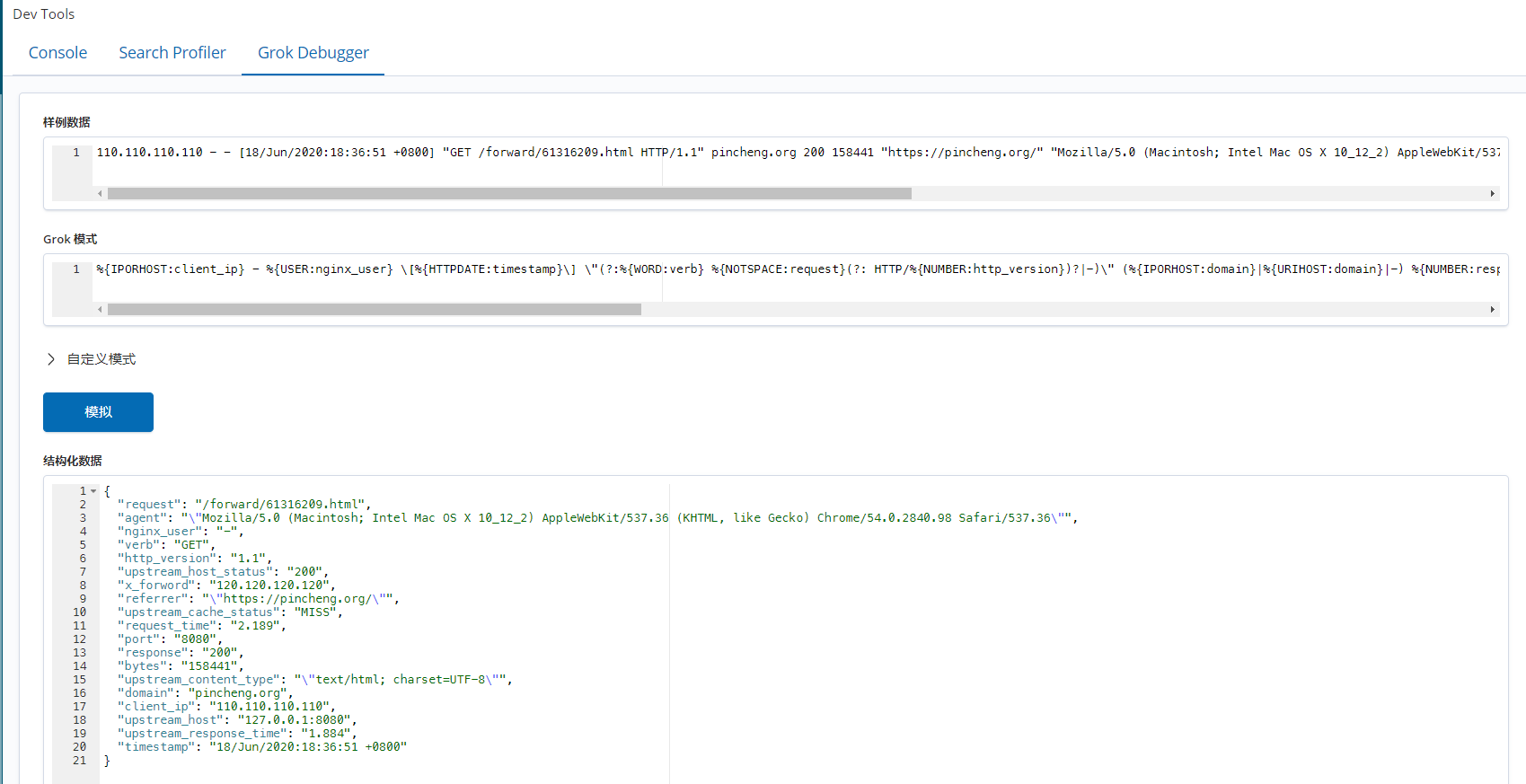
| grok-patterns | 解释 | 适用于 |
|---|---|---|
| IPORHOST (?:%{HOSTNAME}|%{IP}) | 匹配主机名或IP | 匹配客户端ip或主机名 |
| USER %{USERNAME} | 匹配用户名 | 匹配用户名 |
| HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT} | 匹配带时区的日期 | 匹配http请求头中的时间 |
| WORD \b\w+\b | 匹配一个单词 | 匹配请求类型、缓存状态码 |
| NOTSPACE \S+ | 匹配非空白就匹配(没有空格的一段) | 匹配请求URL |
| NUMBER (?:%{BASE10NUM}) | 匹配十进制数字(包括整数、小数) | 匹配http版本、状态码、发送字节数、响应时间 |
| URIHOST %{IPORHOST}(?::%{POSINT:port})? | 匹配(主机名或IP)或(带端口的域名或ip) | 匹配请求的域名 |
| QS %{QUOTEDSTRING} | 匹配用双引号包裹的数据 | 匹配来源页面、客户端UA |
logstash
安装
[root@es-node03 /application]# wget https://repo.huaweicloud.com/logstash/7.4.0/logstash-7.4.0.tar.gz
[root@es-node03 /application]# tar -xf logstash-7.4.0.tar.gz
[root@es-node03 /application]# ls
logstash-7.4.0 logstash-7.4.0.tar.gz
[root@es-node03 /application]# cd logstash-7.4.0/里面应该有一个有配置监听信息的文件:
[root@es-node03 /application/logstash-7.4.0]# cat config/logstash-sample.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}新建自己的配置文件
input {
beats {
port => 8888
codec=> plain{charset=>"UTF-8"}
}
}
filter {
mutate {
add_field => {"[@metadata][target_index]" => ""}
remove_tag => ["beats_input_codec_plain_applied"]
remove_field => ["[agent][type]","[agent][version]","[log][offset]","[log][file][path]","[input][type]","[agent][ephemeral_id]","[agent][id]","[agent][hostname]","[ecs][version]"]
}
if "k8s_access" in [tags] {
grok {
match => { "message" => "%{IPORHOST:client_ip} - %{USER:auth} \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:http_version})?|-)\" (%{IPORHOST:domain}|%{URIHOST:domain}|-) %{NUMBER:response} %{NUMBER:bytes} \"(%{GREEDYDATA:referrer})\" \"(%{GREEDYDATA:user_agent})\" \"(%{IP:x_forword}|%{GREEDYDATA:x_forword})\" \"(%{GREEDYDATA:upstream_host})\" \"(%{GREEDYDATA:upstream_host_status})\" (%{WORD:upstream_cache_status}|-) \"%{GREEDYDATA:upstream_content_type}\" \"(%{GREEDYDATA:upstream_response_time})\" > %{NUMBER:request_time:float}" }
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
mutate {
update => {"[@metadata][target_index]" => "k8s_access-%{+YYYY.MM}-%{+YYYY.ww}"}
}
}
}
output {
elasticsearch {
index => "%{[@metadata][target_index]}"
hosts => ["es-cn-0pp16xvo90009zf49.elasticsearch.aliyuncs.com:9200"]
user =>elastic
password =>Logs1234
}
}- date:将日志中的时间作为logstash处理的时间
配置文件中还有以下这句判断:if "wikibit_ngx_access" in [tags]
因为各种各样的日志都通过logstash分析,所以在filebeat添加了自定义tags以便区分不同的log:
[root@web conf.d]# cat /etc/filebeat/filebeat.yml
########################################
- input_type: log
paths:
- /var/log/nginx/access.log
tags: wikibit_ngx_access
########################################- 处理数字类型字段 管道配置文件中,匹配出的字段默认为文本类型,如果有数字类型的字段(比如响应时间)需要拿来做排序查询。只需要在匹配时在字段末尾加入
:float | :int。那么es建立mapping时会给指定类型建立成数字类型。
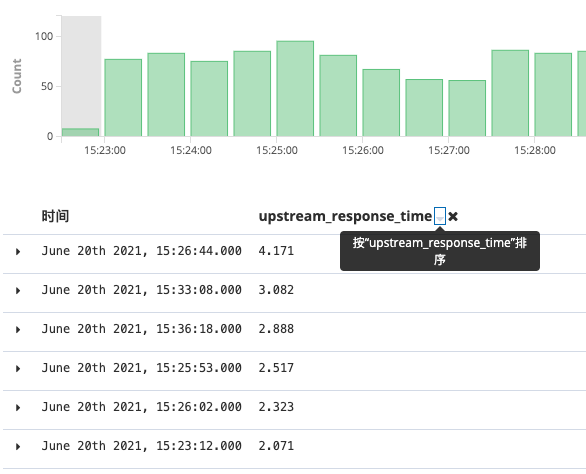
完成上面这一切后,请通过以下命令测试并重新加载logstash和:
[root@web conf.d]# /application/logstash-7.4.0/bin/logstash -f config/wikibit_ngx.conf结果
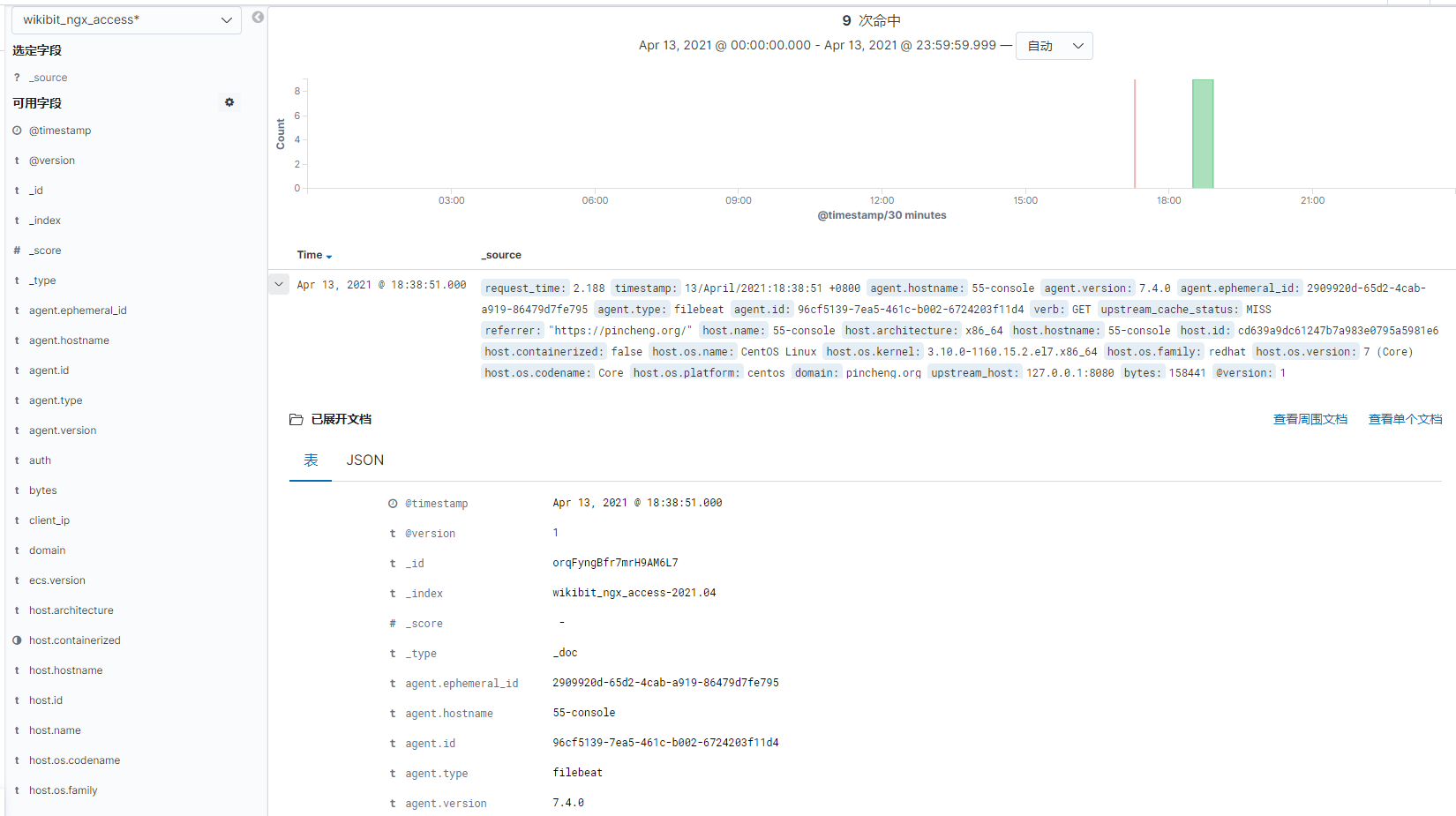
编写匹配代码是最麻烦的一步,要经过很多次的调整才能完美匹配。
特别鸣谢资深软件系统架构师:Evan

