Nginx的负载均衡算法
静态调度算法(和节点无关的调度算法)
rr轮询(默认的调度算法) 平均轮询wrr权重轮询(通过此参数进行权重调度#weight=number;) 能者多劳ip_hash(人话:同一个ip的客户分配到同一台rs上,且不支持backup参数,和weight参数。) 当一个请求到达时,先将客户端IP通过哈希算法哈希出一个值,在随后的客户端请求中,客户端IP的哈希值只要相同,就会分配至同一台服务器,该调度算法可以解决动态网页的session共享问题。(会话保持) LVS负载均衡中的-p参数、keepalive配置里的persistence_ timeout 50参数都类似这个nginx里的ip_hash参数,其功能均为解决动态网页的session共享问题。 会话保持比较流行的解决方案:- 弃用此方案,将用户会话存储在后端共享缓存的redis中。供所有前端web服务器从指定的redis缓存服务器中找到共享的会话。
- cookies技术,服务器根据客户端的请求信息生成cookie并发送给客户端。当客户端请求到第二台节点上时,服务器通过读取客户端的cookie和时间,进行判断是否存在会话。
示例:upstream test.aaa {
ip_hash; ## 调度算法
server 192.168.1.10:80;
server 192.168.1.11:80 down;
server 192.168.1.12:8009 max_fails=3 fail_timeout=20s;
server 192.168.1.13:8080;
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://test.aaa;
}
}动态调度算法
fair此算法会根据后端节点服务器的响应时间来分配请求,响应时间短的优先分配。这是更加智能的调度算法。此种算法可以依据页面大小和加载时间长短智能地进行负载均衡,也就是根据后端服务器的响应时间来分配请求,响应时间短的优先分配。Nginx本身是不支持fair调度算法的,如果需要使用这种调度算法,必须下载Nginx的相关模块upstream_fair。
示例:upstream test.aaa {
fair; ## 调度算法
server 192.168.1.10:80;
server 192.168.1.11:80 down;
server 192.168.1.12:8009 max_fails=3 fail_timeout=20s;
server 192.168.1.13:8080;
}least_conn此算法会根据后端节点的连接数来决定分配情况,哪个机器连接数少就分发。url_hash(人话:同一个URL地址,调度给同一台地址,类似于ip_hash) **作用:**web缓存服务器的负载均衡,提高缓存命中率。 **举个栗子:**有一个服务器集群A,需要对外提供文件下载,由于文件上传量巨大,没法存储到服务器磁盘中,所以用到了第三方云存储来做文件存储。服务器集群A收到客户端请求之后,需要从云存储中下载文件然后返回,为了省去不必要的网络带宽和下载耗时,在服务器集群A上做了一层临时缓存(缓存一个月)。由于是服务器集群,所以同一个资源多次请求,可能会到达不同的服务器上,导致不必要的多次下载,缓存命中率不高,以及一些资源时间的浪费。在此类场景下,为了使得缓存命中率提高,很适合使用url_hash策略,同一个url(也就是同一个资源请求)会到达同一台机器,一旦缓存住了资源,再此收到请求,就可以从缓存中读取,既减少了带宽,也减少的下载时间。 **缺点:**缓存节点不能宕机一致性HASH算法 **作用:**一致性HASH算法类似url_hash算法。 **原理:**通过将用户请求的URI或者指定字符串进行计算,然后调度到后端的服务器上,此后任何用户查找同一个URI或者指定字符串都会被调度到这一台服务器上,因此后端的每个节点缓存的内容都是不同的。 **区别:**一致性HASH算法可以解决后端某个或几个节点宕机后,缓存的数据动荡的最小 配置示例: **模块:**ngx_http_consistent_hash
wget https://github.com/replay/ngx_http_consistent_hash/archive/master.zip下载并解压unzip ngx_http_consistent_hash-master.zip
重新编译Nginx文件,并添加此模块:./configure --add-module=/ngx_http_consistent_hash-master。注意:重新编译会覆盖原有的Nginx,因此在重新编译前,有必要了解上一次编译时,安装了哪些模块:nginx -V
make && make install
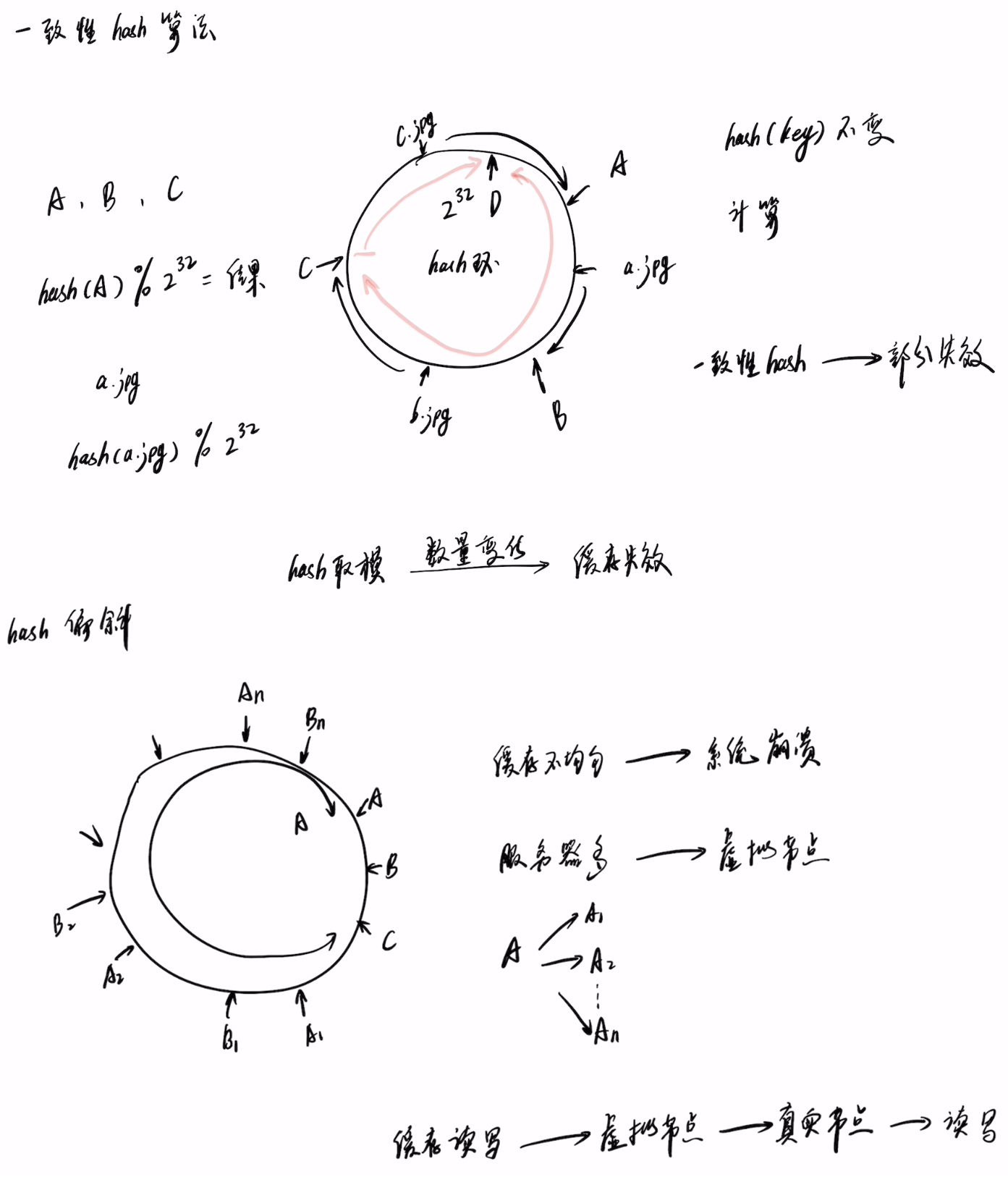
一致性hash算法
url_hash算法原理
对缓存下的键(key,假设为图片的名字)进行hash计算。hash后的值是一个整数(假设为6)
对缓存服务器的数量(假设为3台分别为s0,s1,s2),对这个值进行取模计算。公式为[ hash(文件名称)%机器数=余数(机器的编号) ] 得到的结果就是6%3=0,即余数为0 <==即文件应该被缓存在s0节点上面
余数为0,那么计算出对应的图片应该缓存在s0上 对同一个文件名称做相同的hash计算时值是不变的,那么用户在访问相同的图片时,在负载均衡器上对文件名称进行hash计算,并用缓存节点数对其取模计算。那么得到的结果(余数)就能计算出文件被缓存在了哪个缓存节点上了。并且用户对缓存资源的访问能够精确命中。
url_hash算法缺陷
通过缓存节点计算原理反推出,如果节点总数发生变化(宕机或者增加节点)那么取模计算出的结果也会变化,导致所有的缓存全部无法按正常的计算结果进行精确命中,从而无法通过负载均衡器的调度来对节点已经缓存好的文件进行访问。
结果就是由于节点数的变化导致缓存全部失效,整个前端缓存系统全部需要重新向后端请求数据,导致整个集群被大并发的流量压垮(压力不能在分布式缓存上被削弱而转移到后端服务器)。
一致性hash算法原理

为了弥补hash算法的不足,而产生了一致性hash算法。其原理就是:一个由2^32次方个点组成的圆(被称为hash环),在负载均衡器的后端有三个编号分别为A、B、C缓存节点。
利用hash算法对节点编号进行取模运算 [ hash(节点名如 A)%2^32=余数(0-2^32之间整数) ],通过计算得到的结果一定是一个0-2^32之间的整数,这个整数就代表这个A节点,那么在这个hash环上一定有一个点能表示节点A。 hash(A)%2^32="0-2^32之间的一个值"
以同样的方式进行取模计算出其他缓存服务器节点的值,并且将节点全部映射到hash环上。
在后端真实web服务器上有一张名为a.jpg的图片,且是以图片的名称作为找到图片的key。使用与计算缓存节点相同的公式对a.jpg做取模计算,同时也将他映射到hash环上。
缓存节点和图片都被映射到了hash环上后,以a.jpg为起始,顺时针碰到的第一个服务器就是图片应该被存放到的缓存服务器。(其他图片通过相同的算法和缓存方法都被存放到了自己对应的缓存服务器上)
由于被缓存对象(图片)与服务器hash后的值是固定的。那么在服务器不变的情况下,用户想要访问该图片时,只需要对url上的文件名进行类似 hash(A)%2^32="0-2^32之间的一个值" 这样的计算,就可以计算出这张图片被缓存在了hash环上的哪台缓存节点服务器上了。直接去对应的服务器上查找该图片就成了。
对比url_hash
- 一致性hash算法如何解决url_hash因单台缓存节点的宕机(数量变化)而导致整个缓存系统血崩的情况? url_hash: hash取模 数量变化 > 缓存失效 如果hash环上增加一台服务器D,那么如下图:使得原本缓存在A上的一部分缓存被改变顺时针缓存在了D上,而这种情况下只是失效了一部分缓存,大部分的缓存还是可以正常访问的,从而不至于整个缓存系统全部失效而导致在同一时间所有的压力都集中到后端真实的web服务器上而发生集群雪崩的情况。
一致性hash算法存在的问题
- hash偏斜,在实际应用中缓存节点不会理想的在hash环上均匀的分布,导致单台缓存服务节点承受大多数的缓存和访问压力(缓存不均匀,多台缓存节点资源使用不均匀,系统崩溃),这也是不希望看到的。 解决方法:
- 服务器尽量多的情况下,分布会均匀的可能性更大。
- 在缓存服务器的资源有限的情况下,可以通过现有的物理节点在hash环上映射出足够多的虚拟节点,(假装缓存服务器节点很多)。 映射出的虚拟节点越多,hash环上的服务器节点就越多,缓存被平均分布的概率就越大。
那么用户在读写缓存时,过程就变成了 虚拟节点--->真实节点--->缓存读取