
N卡GPU型号一览
| 产品系列 | M-Class | P-Series | P-Series | V-Series | T-Series | V-Series | A-Series | A-Series | A-Series |
|---|---|---|---|---|---|---|---|---|---|
| 产品家族 | M40 | Tesla P100 | Tesla P4 | Tesla V100 | Tesla T4 | Tesla V100 | NVIDIA A100 | NVIDIA A10 | NVIDIA A100 |
前置操作
- 确定好待交付机器的规格和GPU型号,下面已T4卡为例。
- 跟业务确定好Driver Version和CUDA Version 然后去NVIDIA官网下载对应的驱动脚本
- 比如业务要求:
- Driver Version: 470.82.xx
- CUDA Version: 11.4
进入NVIDIA官网:https://www.nvidia.com/Download/Find.aspx
Driver 和 CUDA对应关系 https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
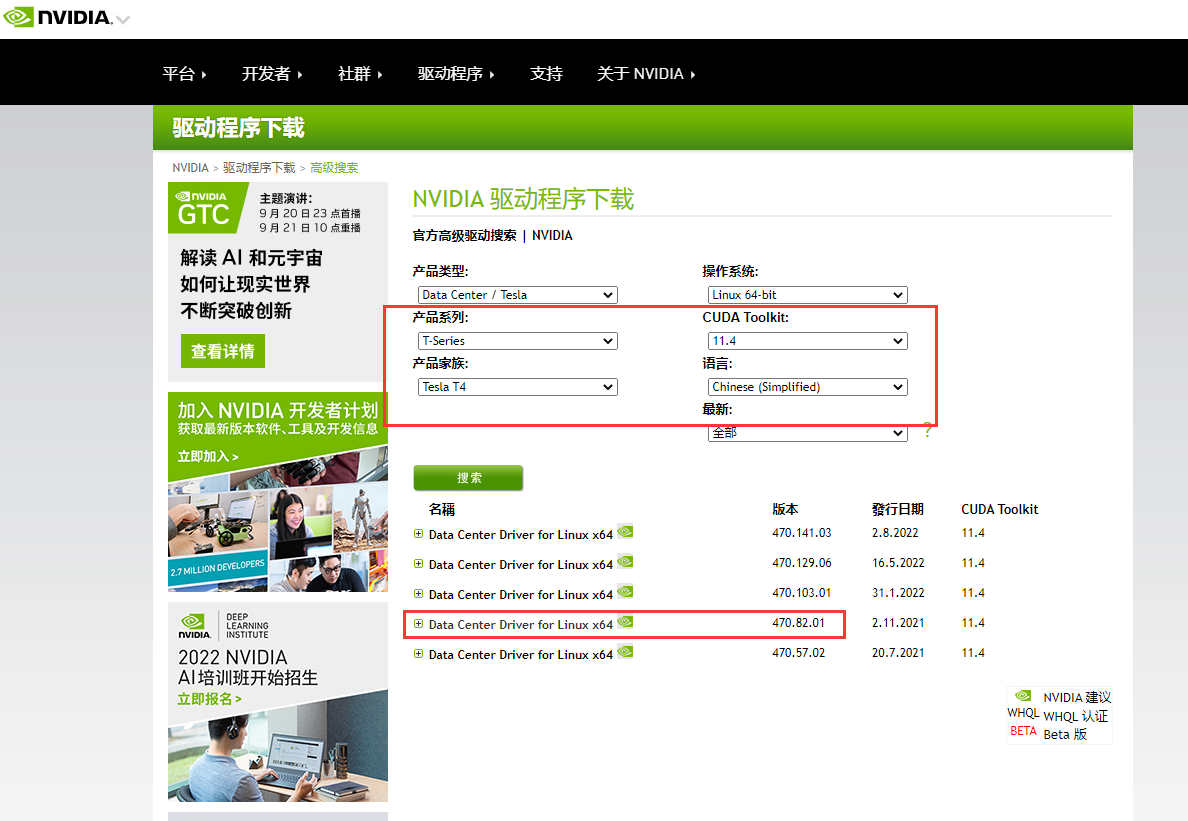
点进去拿到:https://cn.download.nvidia.com/tesla/470.82.01/NVIDIA-Linux-x86_64-470.82.01.run
安装过程
Debian系统:
1. 升级内核:
apt install linux-image-amd64 linux-headers-amd64 -y && reboot
2. 然后再执行
wget https://cn.download.nvidia.com/tesla/470.82.01/NVIDIA-Linux-x86_64-470.82.01.run && chmod +x NVIDIA-Linux-x86_64-470.82.01.run && sh NVIDIA-Linux-x86_64-470.82.01.run && nvidia-smi第一步重启完后这里面有和当前内核版本一致的内核的开发包文件(安装驱动会重新编译内核 必要) 
CentOS系统:
请执行以下命令,查询实例中是否安装kernel-devel和kernel-headers包
rpm -qa | grep $(uname -r)
回显类似如下信息,即包含了kernel-devel和kernel-headers包的版本信息,表示已安装。
kernel-3.10.0-1062.18.1.el7.x86_64
kernel-devel-3.10.0-1062.18.1.el7.x86_64
kernel-headers-3.10.0-1062.18.1.el7.x86_64
然后再执行
wget https://cn.download.nvidia.com/tesla/470.82.01/NVIDIA-Linux-x86_64-470.82.01.run && chmod +x NVIDIA-Linux-x86_64-470.82.01.run && sh NVIDIA-Linux-x86_64-470.82.01.run && nvidia-smikernel-devel和kernel版本不一致会导致在安装driver rpm过程中driver编译出错。因此,请您确认回显信息中kernel-*的版本号后,再下载对应版本的kernel-devel。在示例回显信息中,kernel的版本号为3.10.0-1062.18.1.el7.x86_64。
回显: 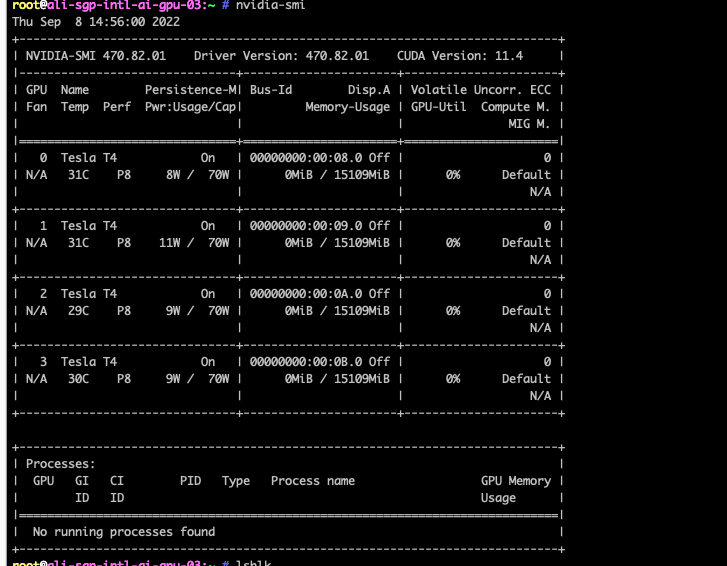
N卡的持久模式
解决低负载下掉卡、卡休眠
原因分析
每当一个或多个客户端打开设备文件时,GPU 状态就会保持加载在驱动程序中。一旦所有客户端都关闭了设备文件,除非启用了持久化模式,否则 GPU 状态将被卸载。为避免每次初始化所造成的延迟而影响到效能,可开启 GPU 持久化模式。
NVIDIA DRIVER PERSISTENCE 文档 Driver Persistence:
Under Linux systems where X runs by default on the target GPU the kernel mode driver will generally be initalized and kept alive from machine startup to shutdown, courtesy of the X process. On headless systems or situations where no long-lived X-like client maintains a handle to the target GPU, the kernel mode driver will initilize and deinitialize the target GPU each time a target GPU application starts and stops. In HPC environments this situation is quite common. Since it is often desireable to keep the GPU initialized in these cases, NVIDIA provides two options for changing driver behavior: Persistence Mode (Legacy) and the Persistence Daemon.
为什么不开启Persistence Mode,GPU会掉卡?
根据我的分析,因为我在运行的程序是Antares/Ansor,这个程序不是一个单一的GPU Application,而是生成数以万计的GPU Application去验证性能,则在每一个Application运行的过程中,GPU的驱动都需要被反复加载和卸载,一方面会损失很多性能,另一方面driver频繁卸载加载,GPU频繁被初始化,CPU访问PCIe config registers时间过长导致 softlock,从而造成GPU的死机。(引用自:/bbs.gpuworld.cn/index.p)
设置方法
一般的机器上安装GPU,GPU的驱动程序会在机器的开启时被加载,机器关闭时再被卸载。而在在没有显示器的Linux操作系统(headless systems)中,尤其是HPC中非常常见,GPU的驱动程序会随着GPU运行的程序开始的时候自动被加载,程序关闭时自动被卸载。nvidia-smi -pm 1设置GPU的Persistence Mode:
nvidia-smi -pm 1开启了该模式之后,GPU的响应速度会变快,但是待机功耗会增加一点。厂商建议开启GPU的持久模式。gpu默认持久模式关闭的时候,GPU如果负载低,会休眠。之后唤起的时候,有一定几率失败,nvidia-smi -pm 1 这个命令可以使GPU一直保持准备工作的状态,解决GPU卡在低负载情况下跑着跑着被卸载休眠的情况。
在机器重新启动后,设定将会清空,如要保留则需写入 service 中编辑 /lib/systemd/system/nvidia-persistenced.service
# vim /lib/systemd/system/nvidia-persistenced.service
[Unit]
Description=NVIDIA Persistence Daemon
After=syslog.target
[Service]
Type=forking
PIDFile=/var/run/nvidia-persistenced/nvidia-persistenced.pid
Restart=always
ExecStart=/usr/bin/nvidia-persistenced --verbose
ExecStopPost=/bin/rm -rf /var/run/nvidia-persistenced/*
TimeoutSec=300
[Install]
WantedBy=multi-user.target
# systemctl enable nvidia-persistenced前后对比
开启前:GPU低负载偶尔掉卡 
开启后:单机4卡不掉 
番外-容器GPU集群
各大云厂商都支持N卡的k8s容器集群,且集群都带相关能力自动安装N卡驱动(在集群每次纳管节点时自动安装)。这里贴一下相关文档,有机会再结合我的工作实践作详细讲解。 阿里云:文档链接
- 在ACK节点池中打上对应的N卡驱动版本标签,机器纳管进入该节点池时会自行安装对应的驱动
华为云:文档链接
- 在CCE集群中添加
gpu-device-plugin,将N卡驱动传入OBS(对象存储)中。插件每次读取OBS中的驱动包为纳管的节点打上对应的驱动
腾讯云:文档链接
- 在TKE集群纳管GPU节点时可选择需要的驱动进行安装


