
redis cluster 分布式集群介绍
高性能:
- 在多分片节点中,将16384个槽位,均匀分布到多个分片节点中
- 存数据时,将key做crc16(key),然后和16384进行取模,得出槽位(0-16383)
- 根据计算得出的槽位值,找到想对应的分片节点的主节点,存储到相应槽位上
- 如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接却换至真正存储节点进行数据存储
高可用:
在搭建集群时,会为每一个分片的主节点,对应一个从节点,实现slaveof的功能,同时当主节点down,实现类似于sentinel的自动fileover的功能。
- redis会为多组分片构成(3组)
- redis cluster 使用固定个数的slot存储数据(一个16384slot)
- 每组分片分得1/3 slot个数(0-5500 5501-11000 11001-16383)
- 基于CRC16(key)% 16384 --> 值 (槽位号)
分布式架构部署
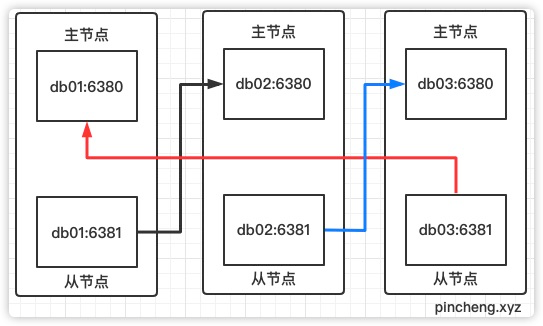
6个redis实例,一般会放到3台硬件服务器
| Role | IP | Port | Server |
|---|---|---|---|
| Master | 10.0.0.51 | 6380 | db01 |
| Slave | 6381 | ||
| Master | 10.0.0.52 | 6380 | db02 |
| Slave | 6381 | ||
| Master | 10.0.0.53 | 6380 | db03 |
| Slave | 6381 |
架构图:
手动搭建部署集群
思路:
- 1)部署一台服务器上的 2 个集群节点
- 2)使用 ansible 批量部署
db01操作步骤:
创建必要目录:
mkdir -p /application/redis_cluster/redis_{6380,6381}/{conf,logs,pid}
mkdir –p /data/redis_cluster/redis_{6380,6381}添加db01主节点配置文件
cat >/application/redis_cluster/redis_6380/conf/redis_6380.conf<<EOF
bind 10.0.0.51
port 6380
daemonize yes
pidfile "/application/redis_cluster/redis_6380/pid/redis_6380.pid"
logfile "/application/redis_cluster/redis_6380/logs/redis_6380.log"
dbfilename "redis_6380.rdb"
dir "/data/redis_cluster/redis_6380/"
cluster-enabled yes
#以集群模式启动redis
cluster-config-file nodes_6380.conf
#定义集群配置文件名
cluster-node-timeout 15000
#超时时间
EOF添加db01从节点配置文件:
cd /application/redis_cluster/
cp redis_6380/conf/redis_6380.conf redis_6381/conf/redis_6381.conf
sed -i 's#6380#6381#g' redis_6381/conf/redis_6381.conf推送配置文件到其余服务器:
rsync -avz /application/redis_cluster/redis_638* db02:/application/redis_cluster/
rsync -avz /application/redis_cluster/redis_638* db03:/application/redis_cluster/
redis-server /application/redis_cluster/redis_6380/conf/redis_6380.conf
redis-server /application/redis_cluster/redis_6381/conf/redis_6381.conf
[root@db01 /application/redis_cluster]# tree redis_638*
redis_6380
├── conf
│ └── redis_6380.conf
├── logs
└── pid
redis_6381
├── conf
│ └── redis_6381.conf
├── logs
└── pid
[root@db01 ~]# ps -ef | grep redis
root 926 1 0 12:14 ? 00:00:00 redis-server 10.0.0.51:6380 [cluster]
root 931 1 0 12:14 ? 00:00:00 redis-server 10.0.0.51:6381 [cluster]
[root@db01 ~]# netstat -lntup | grep redis-server
tcp 0 0 10.0.0.51:16380 0.0.0.0:* LISTEN 926/redis-server 10
tcp 0 0 10.0.0.51:16381 0.0.0.0:* LISTEN 931/redis-server 10
tcp 0 0 10.0.0.51:6380 0.0.0.0:* LISTEN 926/redis-server 10
tcp 0 0 10.0.0.51:6381 0.0.0.0:* LISTEN 931/redis-server 10db02 操作:
find /application/redis_cluster/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#51#52#g"
mkdir –p /data/redis_cluster/redis_{6380,6381}
redis-server /application/redis_cluster/redis_6380/conf/redis_6380.conf
redis-server /application/redis_cluster/redis_6381/conf/redis_6381.conf
[root@db02 ~]# ps -ef | grep redis
root 965 1 0 12:16 ? 00:00:00 redis-server 10.0.0.52:6380 [cluster]
root 975 1 0 12:16 ? 00:00:00 redis-server 10.0.0.52:6381 [cluster]
[root@db02 ~]# netstat -lntup | grep redis-server
tcp 0 0 10.0.0.52:16380 0.0.0.0:* LISTEN 965/redis-server 10
tcp 0 0 10.0.0.52:16381 0.0.0.0:* LISTEN 975/redis-server 10
tcp 0 0 10.0.0.52:6380 0.0.0.0:* LISTEN 965/redis-server 10
tcp 0 0 10.0.0.52:6381 0.0.0.0:* LISTEN 975/redis-server 10db03 操作:
find /application/redis_cluster/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#51#53#g"
mkdir –p /data/redis_cluster/redis_{6380,6381}
redis-server /application/redis_cluster/redis_6380/conf/redis_6380.conf
redis-server /application/redis_cluster/redis_6381/conf/redis_6381.conf
#当把所有节点都启动后查看进程会有 cluster 的字样
[root@db03 ~]# ps -ef | grep redis
root 936 1 0 12:17 ? 00:00:00 redis-server 10.0.0.53:6380 [cluster]
root 941 1 0 12:17 ? 00:00:00 redis-server 10.0.0.53:6381 [cluster]
[root@db03 ~]# netstat -lntup | grep redis-server
tcp 0 0 10.0.0.53:16380 0.0.0.0:* LISTEN 936/redis-server 10
tcp 0 0 10.0.0.53:16381 0.0.0.0:* LISTEN 941/redis-server 10
tcp 0 0 10.0.0.53:6380 0.0.0.0:* LISTEN 936/redis-server 10
tcp 0 0 10.0.0.53:6381 0.0.0.0:* LISTEN 941/redis-server 10注意:集群通讯端口为配置文件里的port加10000,比如6380,通讯端口就是16380
启动后观察配置文件:
还未发现集群内其他节点
[root@db01 ~]# cat /data/redis_cluster/redis_6380/nodes_6380.conf
8e94563f580c0cf12a14a0b04dce3aac36332545 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[root@db01 ~]# cat /data/redis_cluster/redis_6381/nodes_6381.conf
3af4c1f67e95906cf7863bfcc998540dbf9813b6 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0编写redis维护脚本:
#!/bin/bash
###################################################
# File Name: redis_shell.sh
# Created Time: 2019年05月12日 星期二 12时54分39秒
# Version: V1.0
# Author: Felix
# Organization: 360JR OPS
###################################################
USAG(){
echo "sh $0 {start|stop|restart|login|ps|tail} PORT"
}
if [ "$#" = 1 ]
then
REDIS_PORT='6379'
elif
[ "$#" = 2 -a -z "$(echo "$2"|sed 's#[0-9]##g')" ]
then
REDIS_PORT="$2"
else
USAG
exit 0
fi
REDIS_IP=$(ip addr show enp0s8|sed -nr '3s#^.*inet (.*)/.*$#\1#gp')
PATH_DIR=/application/redis_cluster/redis_${REDIS_PORT}/
PATH_CONF=/application/redis_cluster/redis_${REDIS_PORT}/conf/redis_${REDIS_PORT}.conf
PATH_LOG=/application/redis_cluster/redis_${REDIS_PORT}/logs/redis_${REDIS_PORT}.log
CMD_START(){
redis-server ${PATH_CONF}
}
CMD_SHUTDOWN(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT} shutdown
}
CMD_LOGIN(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT}
}
CMD_PS(){
ps -ef|grep redis
}
CMD_TAIL(){
tail -f ${PATH_LOG}
}
CMD_STATUS(){
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT} CLUSTER INFO|grep -Ew "cluster_state|cluster_known_nodes|cluster_slots_assigned"
echo -e "\nSlots state:"
redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT} CLUSTER NODES|awk '{print $2,$3,$NF}'
}
case $1 in
start)
CMD_START
CMD_PS
;;
stop)
CMD_SHUTDOWN
CMD_PS
;;
restart)
CMD_SHUTDOWN
CMD_START
CMD_PS
;;
login)
CMD_LOGIN
;;
ps)
CMD_PS
;;
tail)
CMD_TAIL
;;
csstatus)
CMD_STATUS
;;
*)
USAG
esac
[root@db01 ~]# scp redis_shell.sh db02:/root/
redis_shell.sh 100% 1121 1.3MB/s 00:00
[root@db01 ~]# scp redis_shell.sh db03:/root/
redis_shell.sh集群配置文件(不要手动修改)
#但是登录后执行 CLUSTER NODES 命令会发现只有每个节点自己的 ID,目前集群内的节点还没有互相发现,所以搭建 redis 集群我们第一步要做的就是让集群内的节点互相发现.
[root@db01 ~]# sh redis_shell.sh login 6380
10.0.0.51:6380> CLUSTER NODES
8e94563f580c0cf12a14a0b04dce3aac36332545 :6380@16380 myself,master - 0 0 0 connected
[root@db02 ~]# sh redis_shell.sh login 6380
10.0.0.52:6380> CLUSTER NODES
255c069d63375b3cb537006584c7a02d64b1162e :6380@16380 myself,master - 0 0 0 connected
[root@db03 ~]# sh redis_shell.sh login 6380
10.0.0.53:6380> CLUSTER NODES
5c49f33f4fa7debeb8665e345adf47c16c079c07 :6380@16380 myself,master - 0 0 0 connected
//在执行节点发现命令之前我们先查看一下集群的数据目录会发现有生成集群的配置文件
[root@db01 ~]# tree /data/redis_cluster/redis_638*
/data/redis_cluster/redis_6380
└── nodes_6380.conf
/data/redis_cluster/redis_6381
└── nodes_6381.conf
//查看后发现只有自己的节点内容,等节点全部发现后会把所发现的节点 ID 写入这个文件
[root@db01 ~]# cat //data/redis_cluster/redis_6380/nodes_6380.conf
8e94563f580c0cf12a14a0b04dce3aac36332545 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
[root@db01 ~]# sh redis_shell.sh login 6380
10.0.0.51:6380> CLUSTER NODES
8e94563f580c0cf12a14a0b04dce3aac36332545 :6380@16380 myself,master - 0 0 0 connected注意事项
- 集群模式的 Redis 除了原有的配置文件之外又加了一份集群配置文件.
- 当集群内节点信息发生变化,如添加节点,节点下线,故障转移等.
- 节点会自动保存集群状态到配置文件.
- 需要注意的是,Redis 自动维护集群配置文件,不需要手动修改,防止节点重启时产生错乱.
集群内节点的互相发现
遵循redis集群原则:
- 集群内消息传递是同步的
- 集群内的所有已经发现的节点配置文件是自动更新的
根据如上原则,可知。只需在任意集群内单节点执行发现操作,可将节点信息同步至集群内所有节点的集群配置文件中:
任意单节点执行:
redis-cli -h db01 -p 6380 cluster meet 10.0.0.51 6381
redis-cli -h db01 -p 6380 cluster meet 10.0.0.52 6380
redis-cli -h db01 -p 6380 cluster meet 10.0.0.52 6381
redis-cli -h db01 -p 6380 cluster meet 10.0.0.53 6380
redis-cli -h db01 -p 6380 cluster meet 10.0.0.53 6381检查:
[root@db01 ~]# redis-cli -h db01 -p 6380 CLUSTER NODES
9f7a4d2aef1a9538c49113419adf554548d38d95 10.0.0.53:6381@16381 master - 0 1589269179222 3 connected
5c49f33f4fa7debeb8665e345adf47c16c079c07 10.0.0.53:6380@16380 master - 0 1589269178138 1 connected
ef6a5f1343ed4bfbda5cd21ee68d7e4d98201d97 10.0.0.52:6381@16381 master - 0 1589269179000 0 connected
3af4c1f67e95906cf7863bfcc998540dbf9813b6 10.0.0.51:6381@16381 master - 0 1589269180228 5 connected
255c069d63375b3cb537006584c7a02d64b1162e 10.0.0.52:6380@16380 master - 0 1589269176000 4 connected
8e94563f580c0cf12a14a0b04dce3aac36332545 10.0.0.51:6380@16380 myself,master - 0 1589269178000 2 connected
[root@db01 ~]# redis-cli -h db02 -p 6380 CLUSTER NODES
8e94563f580c0cf12a14a0b04dce3aac36332545 10.0.0.51:6380@16380 master - 0 1589269185661 2 connected
9f7a4d2aef1a9538c49113419adf554548d38d95 10.0.0.53:6381@16381 master - 0 1589269187858 3 connected
5c49f33f4fa7debeb8665e345adf47c16c079c07 10.0.0.53:6380@16380 master - 0 1589269186000 1 connected
ef6a5f1343ed4bfbda5cd21ee68d7e4d98201d97 10.0.0.52:6381@16381 master - 0 1589269187000 0 connected
3af4c1f67e95906cf7863bfcc998540dbf9813b6 10.0.0.51:6381@16381 master - 0 1589269187000 5 connected
255c069d63375b3cb537006584c7a02d64b1162e 10.0.0.52:6380@16380 myself,master - 0 1589269183000 4 connected
[root@db01 ~]# redis-cli -h db03 -p 6380 CLUSTER NODES
8e94563f580c0cf12a14a0b04dce3aac36332545 10.0.0.51:6380@16380 master - 0 1589269189463 2 connected
255c069d63375b3cb537006584c7a02d64b1162e 10.0.0.52:6380@16380 master - 0 1589269187314 4 connected
5c49f33f4fa7debeb8665e345adf47c16c079c07 10.0.0.53:6380@16380 myself,master - 0 1589269188000 1 connected
9f7a4d2aef1a9538c49113419adf554548d38d95 10.0.0.53:6381@16381 master - 0 1589269188321 3 connected
3af4c1f67e95906cf7863bfcc998540dbf9813b6 10.0.0.51:6381@16381 master - 0 1589269187000 5 connected
ef6a5f1343ed4bfbda5cd21ee68d7e4d98201d97 10.0.0.52:6381@16381 master - 0 1589269190646 0 connected
//节点互相发现已完成Redis Cluster 通讯流程
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障灯状态信息,redis 集群采用 Gossip(流言)协议,Gossip 协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点都会知道集群完整信息,这种方式类似流言传播。
通信过程:
- 1)集群中的每一个节点都会单独开辟一个
Tcp通道,用于节点之间彼此通信, 通信端口在基础端口上家10000. - 2)每个节点在固定周期内通过特定规则选择结构节点发送
ping消息 - 3)接收到
ping消息的节点用pong消息作为响应。集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终他们会打成一致的状态,当节点出现故障,新节点加入,主从角色变化等,它能够给不断的ping/pong消息,从而达到同步目的。
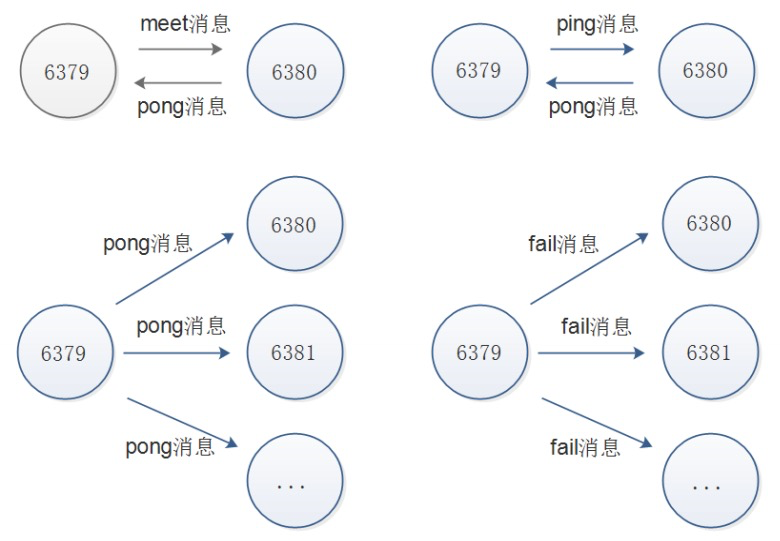
通讯消息类型:
Gossip
Gossip 协议职责就是信息交换,信息交换的载体就是节点间彼此发送 Gossip 消息。 常见 Gossip 消息分为:ping、 pong、 meet、 fail 等
meet
meet消息:用于通知新节点加入,消息发送者通知接受者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行ping、 pong消息交换ping
ping消息:集群内交换最频繁的消息,集群内每个节点每秒想多个其他节点发送ping消息,用于检测节点是否 在线和交换彼此信息。pong
pong消息:当接收到ping,meet消息时,作为相应消息回复给发送方确认消息正常通信,节点也可以向集群内 广播自身的pong消息来通知整个集群对自身状态进行更新。fail
fail消息:当节点判定集群内另一个节点下线时,回向集群内广播一个fail消息,其他节点收到fail消息之 后把对应节点更新为下线状态。
通讯示意图:
分配槽位
要点:
- redis集群一共有16384个槽,所有的槽都必须分配完毕,
- 有一个槽没分配整个集群都不可用,每个节点上槽位的顺序无所谓,重点是槽位的个数,
- hash分片算法足够随机,足够平均
- 不要去手动修改集群的配置文件
为什么是16384(2^14)个槽位?
参见:https://www.php.cn/redis/423851.html
为什么要分配槽位
- 虽然节点之间已经互相发现了,但是此时集群还是不可用的状态,因为并没有给节点分配槽位,而且必须是所有的槽位都分配完毕后整个集群才是可用的状态.
- 反之,也就是说只要有一个槽位没有分配,那么整个集群就是不可用的.
测试命令:
[root@db01 ~]# sh redis_shell.sh login 6380
10.0.0.51:6380> set k1 v1
(error) CLUSTERDOWN Hash slot not served查看状态:
//CLUSTER INFO查看
[root@db01 ~]# sh redis_shell.sh csstatus 6380
cluster_state:fail
cluster_slots_assigned:0
cluster_known_nodes:6根据架构图,6个redis节点,其中3个是主节点「db01:6380 | db02:6380 | bd03:6380」,另外三个是从节点「db01:6381 | db02:6381 | bd03:6381」
槽位分配方法:
分配槽位需要在每个主节点上来配置,此时有 2 种方法执行:
- 分别登录到每个主节点的客户端来执行命令
- 在其中一台机器上用 redis 客户端远程登录到其他机器的主节点上执行命令
槽位规划和分配(有的版本有坑,会报错,需要注意):
[root@db01 ~]# redis-cli -h db01 -p 6380 cluster addslots {0..5461}
OK
[root@db01 ~]# redis-cli -h db02 -p 6380 cluster addslots {5462..10922}
OK
[root@db01 ~]# redis-cli -h db03 -p 6380 cluster addslots {10923..16383}
OK检查槽位和集群状态
//执行脚本查看或者
[root@db01 ~]# sh redis_shell.sh csstatus 6380
cluster_state:ok
cluster_slots_assigned:16384
cluster_known_nodes:6
Slots state:
10.0.0.53:6381@16381 connected
10.0.0.53:6380@16380 10923-16383
10.0.0.52:6381@16381 connected
10.0.0.51:6381@16381 connected
10.0.0.52:6380@16380 5462-10922
10.0.0.51:6380@16380 0-5461
手动查看:
[root@db01 ~]# sh redis_shell.sh login 6380
10.0.0.51:6380> CLUSTER NODES
9f7a4d2aef1a9538c49113419adf554548d38d95 10.0.0.53:6381@16381 master - 0 1589273873963 3 connected
5c49f33f4fa7debeb8665e345adf47c16c079c07 10.0.0.53:6380@16380 master - 0 1589273872940 1 connected 10923-16383
ef6a5f1343ed4bfbda5cd21ee68d7e4d98201d97 10.0.0.52:6381@16381 master - 0 1589273875978 0 connected
3af4c1f67e95906cf7863bfcc998540dbf9813b6 10.0.0.51:6381@16381 master - 0 1589273872000 5 connected
255c069d63375b3cb537006584c7a02d64b1162e 10.0.0.52:6380@16380 master - 0 1589273875000 4 connected 5462-10922
8e94563f580c0cf12a14a0b04dce3aac36332545 10.0.0.51:6380@16380 myself,master - 0 1589273874000 2 connected 0-5461
10.0.0.51:6380> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:2
cluster_stats_messages_ping_sent:4593
cluster_stats_messages_pong_sent:4694
cluster_stats_messages_meet_sent:7
cluster_stats_messages_sent:9294
cluster_stats_messages_ping_received:4694
cluster_stats_messages_pong_received:4600
cluster_stats_messages_received:9294Redis Cluster ASK路由介绍
- 在集群模式下,Redis接受任何键相关命令时首先会计算键对应的槽,再根据槽找出所对应的节点 如果节点是自身,则处理键命令;
- 否则回复MOVED重定向错误,通知客户端请求正确的节点,这个过程称为Mover重定向.
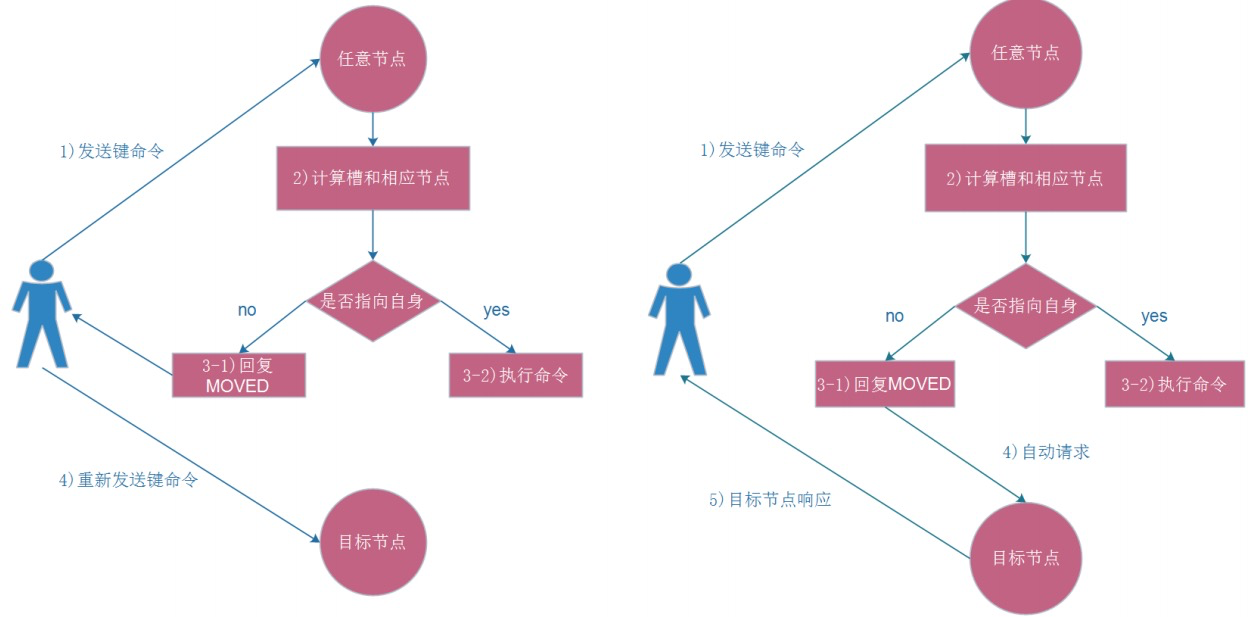
知道了ask路由后,我们使用-c选项批量插入一些数据
[root@redis01 ~]# cat input_key.sh
#!/bin/bash
for i in $(seq 1 1000)
do
redis-cli -c -h 10.0.0.51 -p 6380 set k_${i} v_${i} && echo "set k_${i} is ok"
done写入后我们同样使用-c选项来读取刚才插入的键值,然后查看下redis集群中1000个key数据分布情况
10.0.0.51:6380>
[root@db01 ~]# redis-cli -h 10.0.0.51 -p 6380 -c
db01:6380> DBSIZE
(integer) 339
[root@db02 ~]# redis-cli -h 10.0.0.52 -p 6380
10.0.0.52:6380> DBSIZE
(integer) 326
[root@db03 ~]# redis-cli -h 10.0.0.53 -p 6380
10.0.0.53:6380> DBSIZE
(integer) 335由此可以看出-c选项就会帮我们执行了要去跳转到另一台机器执行
高可用构建:
虽然这时候集群是可用的了,但是整个集群只要有一台机器坏掉了,那么整个集群都是不可用的.所以这时候需要用到其他三个节点分别作为现在三个主节点的从节点,以应对集群主节点故障时可以进行自动故障转移以保证集群持续可用. 注意:
- 1.不要让复制节点复制本机器的主节点, 因为如果那样的话机器挂了集群还是不可用状态, 所以复制节点要复制其他服务器的主节点.
- 2.使用 redis-trid 工具自动分配的时候会出现复制节点和主节点在同一台机器上的情况,需要注意
主从高可用关系如图:
思路:这一次我们采用在一台机器上使用 redis 客户端远程操作集群其他节点 注意:
- 需要执行命令的是每个服务器的从节点
- 注意主从的 ID 不要搞混了.
过滤出所有主节点的ID号
[root@db01 ~]# redis-cli -c -h db01 -p 6381 cluster nodes|grep -v "6381"|awk '{print $1,$2}'
5c49f33f4fa7debeb8665e345adf47c16c079c07 10.0.0.53:6380@16380
8e94563f580c0cf12a14a0b04dce3aac36332545 10.0.0.51:6380@16380
255c069d63375b3cb537006584c7a02d64b1162e 10.0.0.52:6380@16380需要在所有从节点(6381)执行,构建和主节点的主从关系
//如图db01:6381 ---->db02:6380
[root@db01 ~]# redis-cli -h db01 -p 6381 CLUSTER REPLICATE 255c069d63375b3cb537006584c7a02d64b1162e
//如图db02:6381 ---->db03:6380
[root@db01 ~]# redis-cli -h db02 -p 6381 CLUSTER REPLICATE 5c49f33f4fa7debeb8665e345adf47c16c079c07
//如图db03:6381 ---->db01:6380
[root@db01 ~]# redis-cli -h db03 -p 6381 CLUSTER REPLICATE 8e94563f580c0cf12a14a0b04dce3aac36332545结果: 
模拟故障转移
至此,我们已经手动的把一个 redis 高可用的集群部署完毕了, 但是还没有模拟过故障 这里我们就模拟故障,停掉期中一台主机的 redis 节点,然后查看一下集群的变化我们使用暴力的 kill -9 杀掉 db02 上的 redis 集群节点,然后观察节点状态。 根据规划图,应该是 db01 上的 6381 从节点升级为主节点: 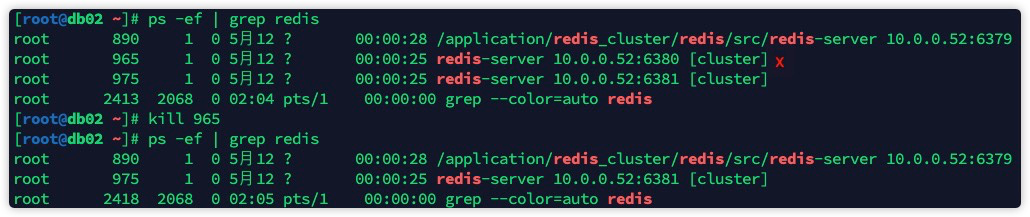 检查集群状态:
检查集群状态: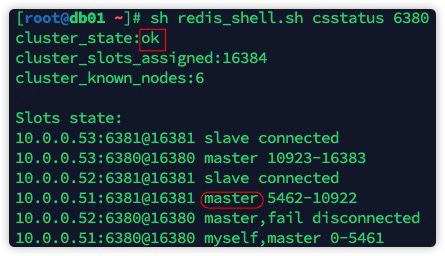
故障节点修复上线
观察db01:6381、db02:6380日志
修复db02:6380
[root@db02 ~]# sh redis_shell.sh start 6380
root 890 1 0 5月12 ? 00:00:29 /application/redis_cluster/redis/src/redis-server 10.0.0.52:6379
root 975 1 0 5月12 ? 00:00:26 redis-server 10.0.0.52:6381 [cluster]
root 2460 2437 0 02:13 pts/0 00:00:00 sh redis_shell.sh tail 6380
root 2467 2460 0 02:13 pts/0 00:00:00 tail -f /application/redis_cluster/redis_6380/logs/redis_6380.log
root 2468 2068 0 02:14 pts/1 00:00:00 sh redis_shell.sh start 6380
root 2476 1 0 02:14 ? 00:00:00 redis-server 10.0.0.52:6380 [cluster]
root 2478 2468 0 02:14 pts/1 00:00:00 grep redisdb01日志: 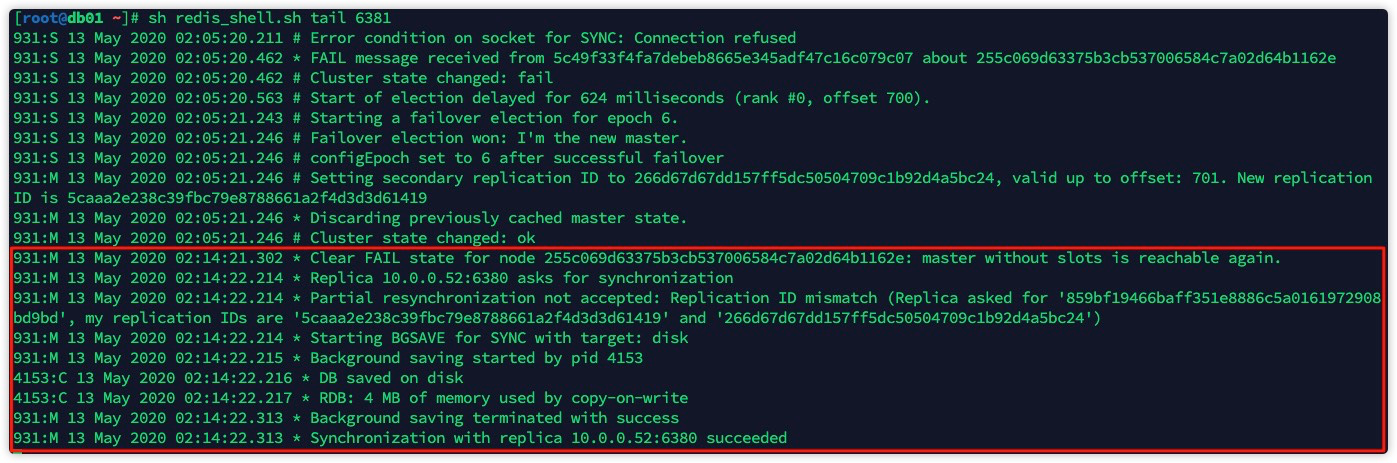
db02日志: 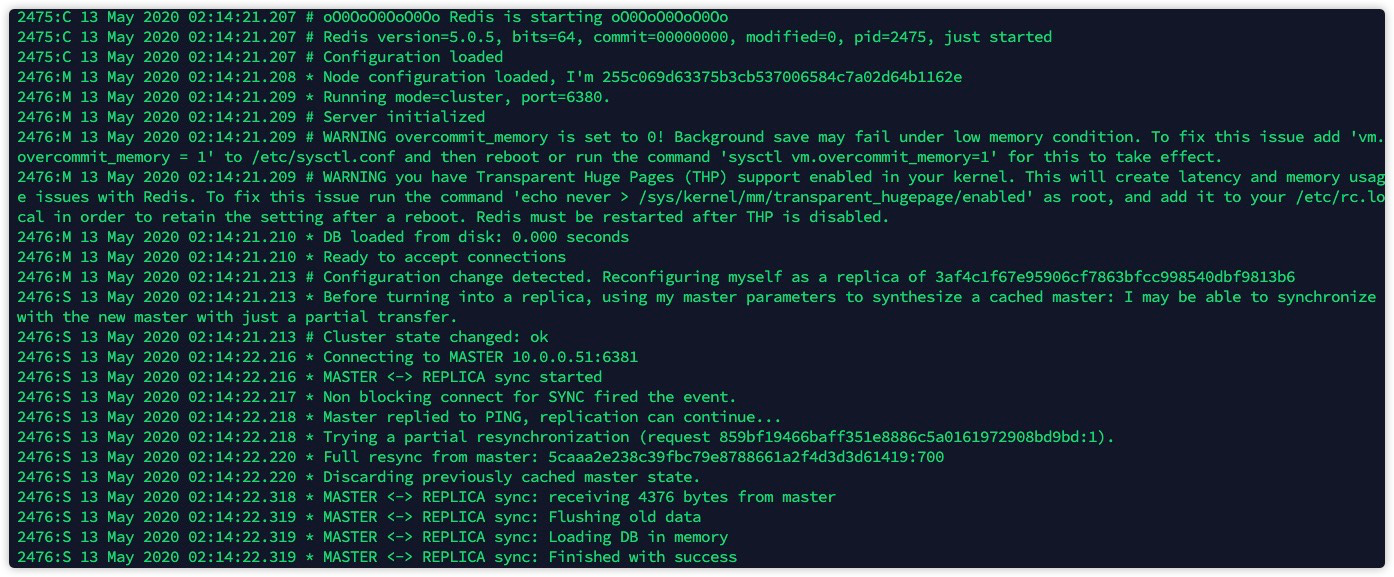 此时,db02:6380成为了db01:6381的从节点。并进行数据同步。
此时,db02:6380成为了db01:6381的从节点。并进行数据同步。
[root@db01 ~]# sh redis_shell.sh csstatus 6380
cluster_state:ok
cluster_slots_assigned:16384
cluster_known_nodes:6
Slots state:
10.0.0.53:6381@16381 slave connected
10.0.0.53:6380@16380 master 10923-16383
10.0.0.52:6381@16381 slave connected
10.0.0.51:6381@16381 master 5462-10922
10.0.0.52:6380@16380 slave connected <===
10.0.0.51:6380@16380 myself,master 0-5461数据同步完成后我们需要将db02:6380提升为主库
- 在db02:6380中执行命令
CLUSTER FAILOVER
[root@db01 ~]# sh redis_shell.sh csstatus 6380
cluster_state:ok
cluster_slots_assigned:16384
cluster_known_nodes:6
Slots state:
10.0.0.53:6381@16381 slave connected
10.0.0.53:6380@16380 master 10923-16383
10.0.0.52:6381@16381 slave connected
10.0.0.51:6381@16381 slave connected
10.0.0.52:6380@16380 master 5462-10922. <===
10.0.0.51:6380@16380 myself,master 0-5461利用工具部署集群:
简介:手动搭建集群便于理解集群创建的流程和细节,不过手动搭建集群需要很多步骤,当集群节点众多 时,必然会加大搭建集群的复杂度和运维成本,因此官方提供了 redis-trib.rb 的工具方便我们快速搭 建集群。
redis-trib.rb 是采用 Ruby 实现的 redis 集群管理工具,内部通过 Cluster 相关命令帮我们简化集群 创建、检查、槽迁移和均衡等常见运维操作,使用前要安装 ruby 依赖环境。
环境准备:
EPEL源安装ruby管理包支持
yum install ruby rubygems -y
配置gem源,并安装驱动
//gem安装需要repo源
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
更新ruby的“yum”
gem sources -l
gem sources -a http://mirrors.aliyun.com/rubygems/
gem sources --remove https://rubygems.org/
gem update -system
gem install redis -v 3.3.5环境初始化
停掉所有的节点,然后清空数据,恢复成一个全新的集群,所有机器执行命令
所有节点执行:
pkill redis
rm -rf /data/redis_cluster/redis_{6380,6381}/*全部清空之后启动所有的节点,所有机器执行
sh redis_shell.sh start 6380
sh redis_shell.sh start 6381
[root@db01 ~]# sh redis_shell.sh csstatus 6380
cluster_state:fail
cluster_slots_assigned:0
cluster_known_nodes:1
Slots state:
10.0.0.51:6380@16380 myself,master connected
[root@db01 ~]# sh redis_shell.sh csstatus 6381
cluster_state:fail
cluster_slots_assigned:0
cluster_known_nodes:1
Slots state:
10.0.0.51:6381@16381 myself,master connecteddb01 执行创建集群命令
利用ruby脚本 创建 副本为1
[root@db01 ~]# which redis-trib.rb
/application/redis_cluster/redis/src/redis-trib.rb
旧版本调用redis-trib.rb脚本:
redis-trib.rb create --replicas 1 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380 \
10.0.0.53:6381 10.0.0.51:6381 10.0.0.52:6381
... 敲yes
注:0,1,2说主节点,3,4,5是对应的从节点。主从节点不能在同一台主机.
-replicas 1 表示每个主库拥有一个从节点。
新版本redis-cli --cluster:
redis-cli --cluster create 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380 10.0.0.53:6381 10.0.0.51:6381 10.0.0.52:6381 --cluster-replicas 1
M: f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380
slots:[0-5460] (5461 slots) master
M: e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a 10.0.0.52:6380
slots:[5461-10922] (5462 slots) master
M: e26fe5d0fc1276abca61ad2998756dd90ede9fda 10.0.0.53:6380
slots:[10923-16383] (5461 slots) master
S: 6d1572a7349c21e8f70b34ee0b13f536acaa680b 10.0.0.53:6381
replicates e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a
S: 84a0719464b3cae31e9c85e25a02c8748a169c44 10.0.0.51:6381
replicates e26fe5d0fc1276abca61ad2998756dd90ede9fda
S: 804af32bdeeeaf89303406b198346bc539ef0d48 10.0.0.52:6381
replicates f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d
理想对应关系:
10.0.0.51:6381 --> 10.0.0.52:6380
10.0.0.52:6381 --> 10.0.0.53:6380
10.0.0.53:6381 --> 10.0.0.51:6380
此时对应关系:
10.0.0.53:6381 --> 10.0.0.52:6380
10.0.0.52:6381 --> 10.0.0.51:6380
10.0.0.51:6381 --> 10.0.0.53:6380
//搭建好后,可以根据需要进行复制关系的调整。调整方法,登陆各个从库手动执行
CLUSTER REPLICATE master_id集群检查:
检查集群状态:
redis-trib.rb check 10.0.0.51:6380 //旧版本
redis-cli --cluster check 10.0.0.51:6380 //新版本检查槽位误差:
redis-trib.rb rebalance 10.0.0.51:6380 //旧版本
redis-cli --cluster rebalance 10.0.0.51:6380 //新版本
>>> Performing Cluster Check (using node 10.0.0.51:6380)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.工具构建集群要点
- 正确安装gem和ruby环境
- 所有节点必须数据为空,且没有分配任何槽位才能用脚本创建集群
- 所有节点必须全部在线且能连接上才能用脚本创建集群
集群扩容
逻辑架构:  槽位变化:
槽位变化: 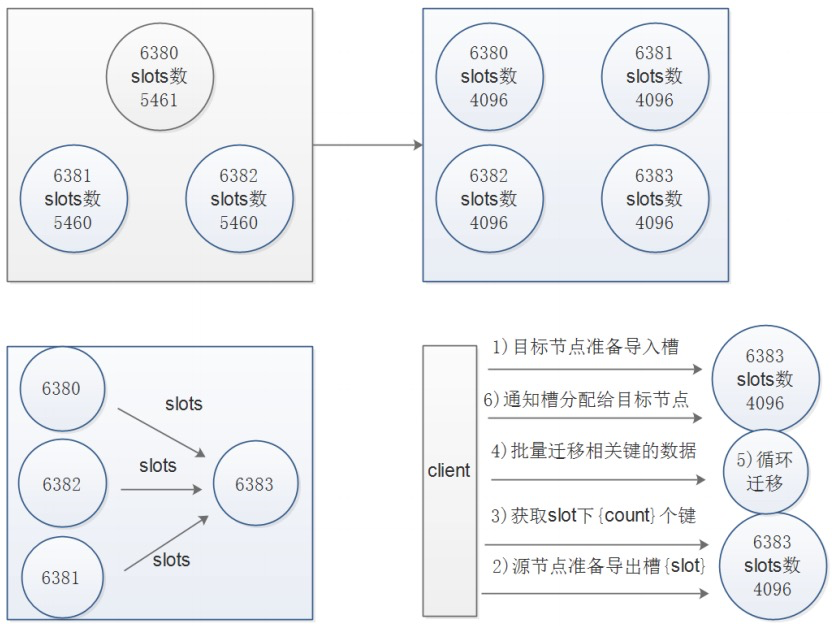
步骤: Redis 集群的扩容操作可分为以下几个步骤
- 1)准备新节点
- 2)加入集群
- 3)迁移槽和数据
环境准备:
这里我在db01上开启两个新的实例替代db04上的新节点
10.0.0.51:6390 new master
10.0.0.51:6391 new slave
mkdir -p /application/redis_cluster/redis_{6390,6391}/{conf,logs,pid}
mkdir -p /data/redis_cluster/redis_{6390,6391}
cd /application/redis_cluster/
cp redis_6380/conf/redis_6380.conf redis_6390/conf/redis_6390.conf
cp redis_6380/conf/redis_6380.conf redis_6391/conf/redis_6391.conf
sed -i 's#6380#6390#g' redis_6390/conf/redis_6390.conf
sed -i 's#6380#6391#g' redis_6391/conf/redis_6391.conf启动节点
bash redis_shell.sh start 6390
bash redis_shell.sh start 6391发现节点
//手动:
redis-cli -c -h db01 -p 6380 cluster meet 10.0.0.51 6390
redis-cli -c -h db01 -p 6380 cluster meet 10.0.0.51 6391
//工具
新版本:
redis-cli --cluster add-node 10.0.0.51:6390 10.0.0.51:6380
redis-cli --cluster add-node 10.0.0.51:6391 10.0.0.51:6380
新节点 集群内任意节点
旧版本:
redis-trib.rb add-node 10.0.0.51:6390 10.0.0.51:6380
redis-trib.rb add-node 10.0.0.51:6391 10.0.0.51:6380
新节点 集群内任意节点发现完成后检查集群状态
[root@db01 ~]# sh redis_shell.sh csstatus 6390
cluster_state:ok
cluster_slots_assigned:16384
cluster_known_nodes:8 //6==>8个节点
Slots state:
10.0.0.52:6380@16380 master 5461-10922
10.0.0.51:6391@16391 master connected
10.0.0.51:6381@16381 slave connected
10.0.0.52:6381@16381 slave connected
10.0.0.53:6381@16381 slave connected
10.0.0.53:6380@16380 master 10923-16383
10.0.0.51:6380@16380 master 0-5460
10.0.0.51:6390@16390 myself,master connected执行槽位迁移
首先计算总共16384个槽位
- 扩容前:16384/3=5461.33333333333333
- 扩容后:16384/4=4096
在 db01 上使用工具扩容
//旧版redis
连接集群内任意节点:redis-trib.rb reshard 10.0.0.51:6380
//新版redis
连接集群内任意节点:redis-cli --cluster reshard 10.0.0.51:6380
[root@db01 ~]# redis-cli --cluster reshard 10.0.0.51:6380
>>> Performing Cluster Check (using node 10.0.0.51:6380)
M: f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 3aea2183787f583888b581946cbeb5fb9135bcdc 10.0.0.51:6391
slots: (0 slots) master
M: 2611fddb9194b38e45e301b7ae835cf09c6cd4c6 10.0.0.51:6390
slots: (0 slots) master
M: e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a 10.0.0.52:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 804af32bdeeeaf89303406b198346bc539ef0d48 10.0.0.52:6381
slots: (0 slots) slave
replicates f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d
M: e26fe5d0fc1276abca61ad2998756dd90ede9fda 10.0.0.53:6380
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 84a0719464b3cae31e9c85e25a02c8748a169c44 10.0.0.51:6381
slots: (0 slots) slave
replicates e26fe5d0fc1276abca61ad2998756dd90ede9fda
S: 6d1572a7349c21e8f70b34ee0b13f536acaa680b 10.0.0.53:6381
slots: (0 slots) slave
replicates e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
//打印出集群每个节点信息后,reshard 命令需要确认迁移的槽数量,这里我们输入 4096 个:
How many slots do you want to move (from 1 to 16384)? 4096
//输入 new_master 的节点 ID 作为目标节点,也就是要扩容的节点,目标节点只能指定一个
What is the receiving node ID? 2611fddb9194b38e45e301b7ae835cf09c6cd4c6
//之后输入源节点的 ID,这里分别输入每个主节点的 ID 最后输入 done,或者直接输入 all
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots. //从所有节点进行分拆
Type 'done' once you entered all the source nodes IDs. //选择需要分拆的节点,结束时输入done
Source node #1: all
Ready to move 4096 slots.
Source nodes:
M: f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 3aea2183787f583888b581946cbeb5fb9135bcdc 10.0.0.51:6391
slots: (0 slots) master
M: e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a 10.0.0.52:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
M: e26fe5d0fc1276abca61ad2998756dd90ede9fda 10.0.0.53:6380
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
Destination node:
M: 2611fddb9194b38e45e301b7ae835cf09c6cd4c6 10.0.0.51:6390
slots: (0 slots) master
Resharding plan:
Moving slot 5461 from e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a
Moving slot 5462 from e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a
.....
Do you want to proceed with the proposed reshard plan (yes/no)? yes
.....
Moving slot 12286 from 10.0.0.53:6380 to 10.0.0.51:6390:
Moving slot 12287 from 10.0.0.53:6380 to 10.0.0.51:6390:检查槽位迁移结果
//旧版本
redis-trib.rb rebalance 10.0.0.51:6380
//新版本
[root@db01 ~]# redis-cli --cluster rebalance 10.0.0.51:6380
>>> Performing Cluster Check (using node 10.0.0.51:6380)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.根据扩容逻辑图,对新加入的节点做主从高可用
理想状态: db04:6381 ---->db01:6380 db03:6381 ---->db04:6380
实际状态: db01:6391 ---->db01:6380 db03:6381 ---->db01:6390
//登陆db03:6381构建到db01:6390的主从
10.0.0.53:6381> CLUSTER NODES
6d1572a7349c21e8f70b34ee0b13f536acaa680b 10.0.0.53:6381@16381 myself,slave f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 0 1589349091000 4 connected
f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380@16380 master - 0 1589349092000 1 connected 1365-5460
...
2611fddb9194b38e45e301b7ae835cf09c6cd4c6 10.0.0.51:6390@16390 master - 0 1589349095417 7 connected 0-1364 5461-6826 10923-12287
10.0.0.53:6381> CLUSTER REPLICATE 2611fddb9194b38e45e301b7ae835cf09c6cd4c6
10.0.0.53:6381> CLUSTER NODES
6d1572a7349c21e8f70b34ee0b13f536acaa680b 10.0.0.53:6381@16381 myself,slave 2611fddb9194b38e45e301b7ae835cf09c6cd4c6 0 1589349144000 4 connected
...
2611fddb9194b38e45e301b7ae835cf09c6cd4c6 10.0.0.51:6390@16390 master - 0 1589349141000 7 connected 0-1364 5461-6826 10923-12287
...
---
登陆db01:6391构建到db01:6380的主从
10.0.0.51:6391> CLUSTER NODES
...
f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380@16380 master - 0 1589349368591 1 connected 1365-5460
...
3aea2183787f583888b581946cbeb5fb9135bcdc 10.0.0.51:6391@16391 myself,master - 0 1589349368000 0 connected
10.0.0.51:6391> CLUSTER NODES
...
f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380@16380 master - 0 1589349465615 1 connected 1365-5460
...
3aea2183787f583888b581946cbeb5fb9135bcdc 10.0.0.51:6391@16391 myself,slave f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 0 1589349458000 0 connected集群修复命令
目前fix命令能修复两种异常
- 节点中存在处于迁移中(importing或migrating状态)的slot。
- 节点中存在未分配的slot。
- 旧版本:redis-trib.rb fix 10.0.0.51:6380
- 新版本:redis-cli --cluster fix 10.0.0.51 6380
其它异常不能通过fix命令修复。
集群缩容
流程说明: 1).首先需要确定下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性. 2).当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭.
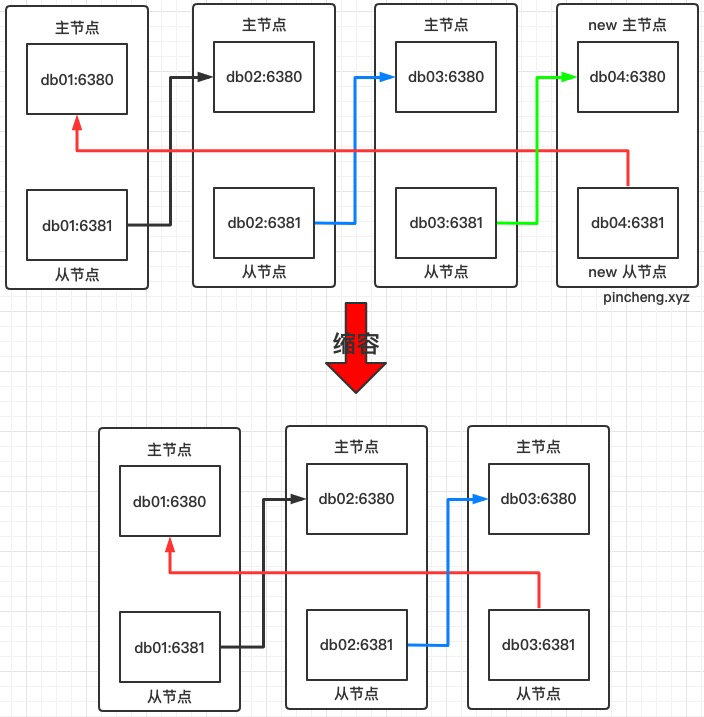
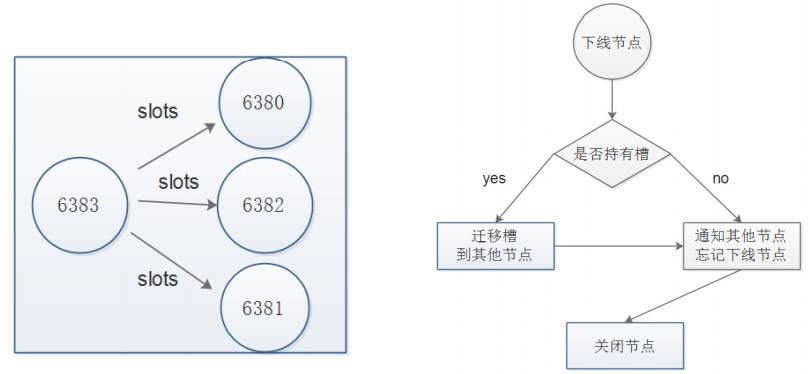
这里我们准备将刚才新添加的节点下线,也就是 6390 和 6391
- 收缩和扩容迁移的方向相反,6390 变为源节点,其他节点变为目标节点,源节点把自己负责的 4096 个槽均匀的迁移到其他节点上,.
- 由于 redis-trib..rb reshard 命令只能有一个目标节点,因此需要执行 3 次 reshard 命令,分别迁移1365,1365,1366 个槽.
计算:
4096/3=1365..... 持有槽位数/剩余master数量=需归还每节点数量
持有槽位数量查看:
[root@db01 ~]# redis-cli --cluster fix 10.0.0.51 6390
10.0.0.51:6390 (2611fddb...) -> 0 keys | 4096 slots | 1 slaves. <==获得槽位数
10.0.0.52:6380 (e6225763...) -> 0 keys | 4096 slots | 1 slaves.
10.0.0.53:6380 (e26fe5d0...) -> 0 keys | 4096 slots | 1 slaves.
10.0.0.51:6380 (f3ac33eb...) -> 0 keys | 4096 slots | 1 slaves.缩容-槽位迁移:
//新版本:
redis-cli --cluster reshard 10.0.0.51:6380
集群内任意节点
//旧版本:
redis-trib.rb reshard 10.0.0.51:6380
归还db01:6390->db01:6380
[root@db01 ~]# redis-cli --cluster reshard 10.0.0.51:6380
>>> Performing Cluster Check (using node 10.0.0.51:6380)
M: f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380
slots:[1365-5460] (4096 slots) master
1 additional replica(s)
...
M: 2611fddb9194b38e45e301b7ae835cf09c6cd4c6 10.0.0.51:6390
slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) master
1 additional replica(s)
...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365 //每节点归还数量
What is the receiving node ID? f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d //接受者id
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 2611fddb9194b38e45e301b7ae835cf09c6cd4c6 //发送者id
Source node #2: done
归还db01:6390->db02:6380
[root@db01 ~]# redis-cli --cluster reshard 10.0.0.51:6380
>>> Performing Cluster Check (using node 10.0.0.51:6380)
...
M: 2611fddb9194b38e45e301b7ae835cf09c6cd4c6 10.0.0.51:6390
slots:[5461-6826],[10923-12287] (2731 slots) master
1 additional replica(s)
M: e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a 10.0.0.52:6380
slots:[6827-10922] (4096 slots) master
1 additional replica(s)
...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 2611fddb9194b38e45e301b7ae835cf09c6cd4c6
Source node #2: done
归还db01:6390->db03:6380
[root@db01 ~]# redis-cli --cluster reshard 10.0.0.51:6380
>>> Performing Cluster Check (using node 10.0.0.51:6380)
...
M: 2611fddb9194b38e45e301b7ae835cf09c6cd4c6 10.0.0.51:6390
slots:[6826],[10923-12287] (1366 slots) master
1 additional replica(s)
...
M: e26fe5d0fc1276abca61ad2998756dd90ede9fda 10.0.0.53:6380
slots:[12288-16383] (4096 slots) master
1 additional replica(s)
...
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1366
What is the receiving node ID? e26fe5d0fc1276abca61ad2998756dd90ede9fda
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: 2611fddb9194b38e45e301b7ae835cf09c6cd4c6
Source node #2: done检查状态:
[root@db01 ~]# sh redis_shell.sh csstatus 6380
cluster_state:ok
cluster_slots_assigned:16384
cluster_known_nodes:8
Slots state:
10.0.0.51:6391@16391 slave connected
10.0.0.51:6390@16390 master connected //全没了
10.0.0.52:6380@16380 master 6827-10922
10.0.0.52:6381@16381 slave connected
10.0.0.53:6380@16380 master 10923-16383
10.0.0.51:6381@16381 slave connected
10.0.0.51:6380@16380 myself,master 0-5460
10.0.0.53:6381@16381 slave connected
槽位分布:
[root@db01 ~]# redis-cli --cluster rebalance 10.0.0.51:6380
>>> Performing Cluster Check (using node 10.0.0.51:6380)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.
```
### 缩容-删除节点
**工具删除节点**
1. 从库可以直接删除
2. 主库必须是没有槽位并且没有数据
命令:
```bash
//旧版本
./redis-trib.rb del-node 10.0.0.51:6390 2611fddb9194b38e45e301b7ae835cf09c6cd4c6
//新版本 目标节点ip:port 目标节点id
[root@db01 ~]# redis-cli --cluster del-node 10.0.0.51:6390 2611fddb9194b38e45e301b7ae835cf09c6cd4c6
>>> Removing node 2611fddb9194b38e45e301b7ae835cf09c6cd4c6 from cluster 10.0.0.51:6390
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
[root@db01 ~]# redis-cli --cluster del-node 10.0.0.51:6391 3aea2183787f583888b581946cbeb5fb9135bcdc
>>> Removing node 3aea2183787f583888b581946cbeb5fb9135bcdc from cluster 10.0.0.51:6391
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.
//检查
[root@db01 ~]# sh redis_shell.sh login 6380
10.0.0.51:6380> CLUSTER NODES
e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a 10.0.0.52:6380@16380 master - 0 1589354349000 9 connected 5461-6825 6827-10922
804af32bdeeeaf89303406b198346bc539ef0d48 10.0.0.52:6381@16381 slave e26fe5d0fc1276abca61ad2998756dd90ede9fda 0 1589354349915 10 connected
e26fe5d0fc1276abca61ad2998756dd90ede9fda 10.0.0.53:6380@16380 master - 0 1589354348735 10 connected 6826 10923-16383
84a0719464b3cae31e9c85e25a02c8748a169c44 10.0.0.51:6381@16381 slave e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a 0 1589354350000 9 connected
f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380@16380 myself,master - 0 1589354349000 8 connected 0-5460
6d1572a7349c21e8f70b34ee0b13f536acaa680b 10.0.0.53:6381@16381 slave e26fe5d0fc1276abca61ad2998756dd90ede9fda 0 1589354351282 10 connected
//db03:6381复制关系不正确
```
### 缩容-调整复制关系
```bash
//登陆db03
10.0.0.53:6381> CLUSTER REPLICATE f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d
OK
10.0.0.53:6381> CLUSTER NODES
6d1572a7349c21e8f70b34ee0b13f536acaa680b 10.0.0.53:6381@16381 myself,slave f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 0 1589354735000 4 connected
f3ac33ebbbbfd8078f32f269c7d2a32e4e86bd5d 10.0.0.51:6380@16380 master - 0 1589354737640 8 connected 0-5460
e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a 10.0.0.52:6380@16380 master - 0 1589354735420 9 connected 5461-6825 6827-10922
84a0719464b3cae31e9c85e25a02c8748a169c44 10.0.0.51:6381@16381 slave e6225763f9f8f4e2ce715e2161f5e9bac74ccd6a 0 1589354735000 9 connected
e26fe5d0fc1276abca61ad2998756dd90ede9fda 10.0.0.53:6380@16380 master - 0 1589354737000 10 connected 6826 10923-16383
804af32bdeeeaf89303406b198346bc539ef0d48 10.0.0.52:6381@16381 slave e26fe5d0fc1276abca61ad2998756dd90ede9fda 0 1589354736513 10 connected
```
至此,redis分布式集群,以及集群的扩容缩容,故障转移等全部完成。