
本文介绍Canal服务容器化+Kubernetes部署
参考文档:
- https://github.com/alibaba/canal
- https://github.com/kubernetes/kubernetes/issues/81450
- https://hub.docker.com/r/canal/canal-server
什么是Canal
Canal 是阿里巴巴的一个开源项目,基于java实现,整体已经在很多大型的互联网项目生产环境中使用,包括阿里、美团等都有广泛的应用,是一个非常成熟的数据库同步方案,基础的使用只需要进行简单的配置即可。
- canal是通过模拟成为mysql 的slave的方式,监听mysql 的binlog日志来获取数据,binlog设置为row模式以后,不仅能获取到执行的每一个增删改的脚本,同时还能获取到修改前和修改后的数据。
基于这个特性,canal就能高性能的获取到mysql数据数据的变更。简而言之就是做MySQL数据异构的。想具体了解可以参考官方文档这里不再赘述
Canal容器化
通过查看官方的Dockerfile发现写的并不专业,镜像中存在很多冗余配置如Prometheus获取监控指标的客户端、服务可用性健康检查脚本并不纯粹,而且镜像前台启动是通过tail -f /dev/null & 这个命令启动的。相当于吧容器当成虚拟机使用。这样做其实并不合理所以决定动手修改并用Alpine作为基础镜像重新打包
官方镜像800M+,自己打包的镜像400M+

修改1:入口启动脚本app.sh
#!/bin/bash
source /etc/profile
export JAVA_HOME=/app/jdk1.8.0_181
export PATH=$JAVA_HOME/bin:$PATH
touch /tmp/start.log
host=`hostname -i`
function start_canal() {
echo "start canal ..."
managerAddress=`perl -le 'print $ENV{"canal.admin.manager"}'`
if [ ! -z "$managerAddress" ] ; then
# canal_local.properties mode
adminPort=`perl -le 'print $ENV{"canal.admin.port"}'`
if [ -z "$adminPort" ] ; then
adminPort=11110
fi
cd /app/canal-server/bin/ && bash restart.sh
else
metricsPort=`perl -le 'print $ENV{"canal.metrics.pull.port"}'`
if [ -z "$metricsPort" ] ; then
metricsPort=11112
fi
destination=`perl -le 'print $ENV{"canal.destinations"}'`
if [[ "$destination" =~ ',' ]]; then
echo "multi destination:$destination is not support"
exit 1;
else
if [ "$destination" != "" ] && [ "$destination" != "example" ] ; then
if [ -d /app/canal-server/conf/example ]; then
mv /app/canal-server/conf/example /app/canal-server/conf/$destination
fi
fi
fi
cd /app/canal-server/bin/ && bash restart.sh
fi
}
main () {
echo "==> START STATUS"
start_canal
}
main修改2:canal启动脚本startup.sh
#!/bin/bash
current_path=`pwd`
case "`uname`" in
Linux)
bin_abs_path=$(readlink -f $(dirname $0))
;;
*)
bin_abs_path=`cd $(dirname $0); pwd`
;;
esac
base=${bin_abs_path}/..
canal_conf=$base/conf/canal.properties
canal_local_conf=$base/conf/canal_local.properties
logback_configurationFile=$base/conf/logback.xml
export LANG=en_US.UTF-8
export BASE=$base
if [ -f $base/bin/canal.pid ] ; then
echo "found canal.pid , Please run stop.sh first ,then startup.sh" 2>&2
exit 1
fi
if [ ! -d $base/logs/canal ] ; then
mkdir -p $base/logs/canal
fi
## set java path
if [ -z "$JAVA" ] ; then
JAVA=$(which java)
fi
ALIBABA_JAVA="/usr/alibaba/java/bin/java"
TAOBAO_JAVA="/opt/taobao/java/bin/java"
if [ -z "$JAVA" ]; then
if [ -f $ALIBABA_JAVA ] ; then
JAVA=$ALIBABA_JAVA
elif [ -f $TAOBAO_JAVA ] ; then
JAVA=$TAOBAO_JAVA
else
echo "Cannot find a Java JDK. Please set either set JAVA or put java (>=1.5) in your PATH." 2>&2
exit 1
fi
fi
case "$#"
in
0 )
;;
1 )
var=$*
if [ "$var" = "local" ]; then
canal_conf=$canal_local_conf
else
if [ -f $var ] ; then
canal_conf=$var
else
echo "THE PARAMETER IS NOT CORRECT.PLEASE CHECK AGAIN."
exit
fi
fi;;
2 )
var=$1
if [ "$var" = "local" ]; then
canal_conf=$canal_local_conf
else
if [ -f $var ] ; then
canal_conf=$var
else
if [ "$1" = "debug" ]; then
DEBUG_PORT=$2
DEBUG_SUSPEND="n"
JAVA_DEBUG_OPT="-Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,address=$DEBUG_PORT,server=y,suspend=$DEBUG_SUSPEND"
fi
fi
fi;;
* )
echo "THE PARAMETERS MUST BE TWO OR LESS.PLEASE CHECK AGAIN."
exit;;
esac
str=`file -L $JAVA | grep 64-bit`
if [ -n "$str" ]; then
# JAVA_OPTS="-server -Xms2048m -Xmx3072m -Xmn1024m -XX:SurvivorRatio=2 -XX:PermSize=96m -XX:MaxPermSize=256m -Xss256k -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError"
JAVA_OPTS="-server -Xms1024m -Xmx2048m -Xmn1024m -XX:SurvivorRatio=2 -XX:PermSize=96m -XX:MaxPermSize=256m -Xss256k -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError"
else
JAVA_OPTS="-server -Xms1024m -Xmx1024m -XX:NewSize=256m -XX:MaxNewSize=256m -XX:MaxPermSize=128m "
fi
JAVA_OPTS=" $JAVA_OPTS -Djava.awt.headless=true -Djava.net.preferIPv4Stack=true -Dfile.encoding=UTF-8"
CANAL_OPTS="-DappName=otter-canal -Dlogback.configurationFile=$logback_configurationFile -Dcanal.conf=$canal_conf"
if [ -e $canal_conf -a -e $logback_configurationFile ]
then
for i in $base/lib/*;
do CLASSPATH=$i:"$CLASSPATH";
done
CLASSPATH="$base/conf:$CLASSPATH";
echo "cd to $bin_abs_path for workaround relative path"
cd $bin_abs_path
echo LOG CONFIGURATION : $logback_configurationFile
echo canal conf : $canal_conf
echo CLASSPATH :$CLASSPATH
$JAVA $JAVA_OPTS $JAVA_DEBUG_OPT $CANAL_OPTS -classpath .:$CLASSPATH com.alibaba.otter.canal.deployer.CanalLauncher
echo $! > $base/bin/canal.pid
echo "cd to $current_path for continue"
cd $current_path
else
echo "canal conf("$canal_conf") OR log configration file($logback_configurationFile) is not exist,please create then first!"
fi编写Dockefile
FROM registry.cn-shanghai.aliyuncs.com/wikifx/base:alpine-glibc-Shanghai
MAINTAINER https://cakepanit.com
WORKDIR /app
COPY . .
RUN apk add --no-cache perl &&\
apk add --no-cache file &&\
apk add --no-cache bash &&\
chmod +x /app/*.sh
# admin , 11111 canal , 11112 metrics
EXPOSE 11110 11111 11112
CMD ["/app/app.sh"]构建并上传:
docker build . -t registry.cn-shanghai.aliyuncs.com/xxxx/base:canal-server-v1.1.5 -f Dockerfile
docker push registry.cn-shanghai.aliyuncs.com/xxxx/base:canal-server-v1.1.5部署至k8s
这里将Canal-Client和刚打包好的Canal-Server启动到同一个pod中,Canal-Client为公司开发人员开发,处理自己业务逻辑的。
apiVersion: v1
kind: Namespace
metadata:
name: bservices
---
apiVersion: v1
kind: ConfigMap
metadata:
name: canalconfig
namespace: bservices
labels:
k8s-app: canalconfig
kubernetes.io/cluster-service: "true"
data:
canal.properties: |-
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers = zk-service.baseservice:2181
#zookeeper存储位置点信息
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = spring
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
#canal.instance.global.spring.xml = classpath:spring/file-instance.xml
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
#将位置点存入zookeeper
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:9092
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = test
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = 127.0.0.1:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
userdb.properties: |-
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=1000
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=rm-xxxx.mysql.rds.aliyuncs.com:3306
#数据库连接串
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=false
canal.instance.tsdb.dir=${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url=jdbc:mysql://rm-xxxx.mysql.rds.aliyuncs.com:3306/canal_tsdb
canal.instance.tsdb.dbUsername=wikifx
canal.instance.tsdb.dbPassword=Wikifx123
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=wikifx
#数据账户
canal.instance.dbPassword=Wikifx2021
#数据库密码
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=fxskyeye\\..*
#订阅的数据库名称
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=forum
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: canal-userdb
namespace: bservices
spec:
replicas: 1
strategy: #滚动更新改为重新构建
type: Recreate
selector:
matchLabels:
app: canal-userdb
template:
metadata:
labels:
app: canal-userdb
spec:
volumes:
- name: logsmk #volume名字
hostPath:
path: /var/applogs
- name: canalconfig
configMap:
defaultMode: 0444
name: canalconfig
containers:
- name: canalserver-userdb
image: registry.cn-shanghai.aliyuncs.com/xxxx/base:canal-server-v1.1.5
imagePullPolicy: IfNotPresent
resources:
requests:
memory: 1024Mi
cpu: 100m
limits:
memory: 2048Mi
cpu: 1000m
readinessProbe:
httpGet:
path: /
port: 11112
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 15
timeoutSeconds: 5
volumeMounts:
- name: canalconfig #通过configmp挂载canalserver主配置
mountPath: /app/canal-server/conf/canal.properties
readOnly: true
subPath: canal.properties
- name: canalconfig #通过configmp挂载canalserver子配置
mountPath: /app/canal-server/conf/userdb/instance.properties
readOnly: true
subPath: userdb.properties
lifecycle:
postStart:
exec:
command:
- /bin/bash
- '-c'
- >-
while [ ! -d "/app/canal-server/logs/userdb" ]; do sleep 5; done #阻塞启动,等canalserver完全启动,再启动下一个容器canalclient
- name: wikiuserdbcanal
image: ${IMAGE}
imagePullPolicy: IfNotPresent
env:
- name: TZ
value: "Asia/Shanghai"
- name: ENVIRONMENT
valueFrom:
configMapKeyRef:
name: environment
key: ENVIRONMENT
resources:
requests:
memory: 100Mi
cpu: 50m
limits:
memory: 1000Mi
cpu: 2000m
readinessProbe:
exec:
command:
- ls
initialDelaySeconds: 6
timeoutSeconds: 1
periodSeconds: 2
volumeMounts:
- name: logsmk
mountPath: /var/applogs/关键配置项都有注释,不懂的可以在下面留言。比较重要的
postStart配置,通过检查Canal日志目录是否存在,确定Canal是否完全启动。这个配置会干扰Canal-Client这个容器启动的时间。确保Canal-Server启动完成后再启动Canal-Client。Zookeeper配置,通过将CanalServer位置点等信息放入Zookeeper将CanalServer变成无状态应用。zookeeper目录结构:
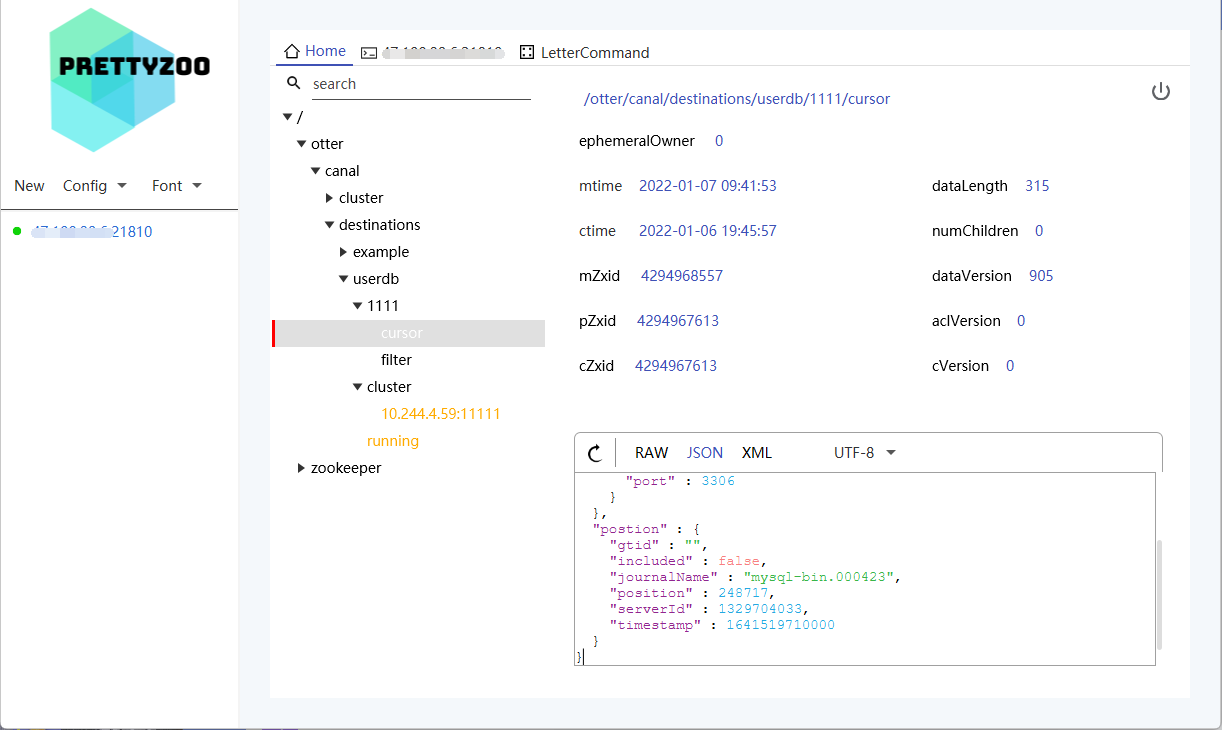
安利一个好用的zk客户端: PrettyZoo
再精彩的文字解说都是枯燥的,下面看下启动效果图。
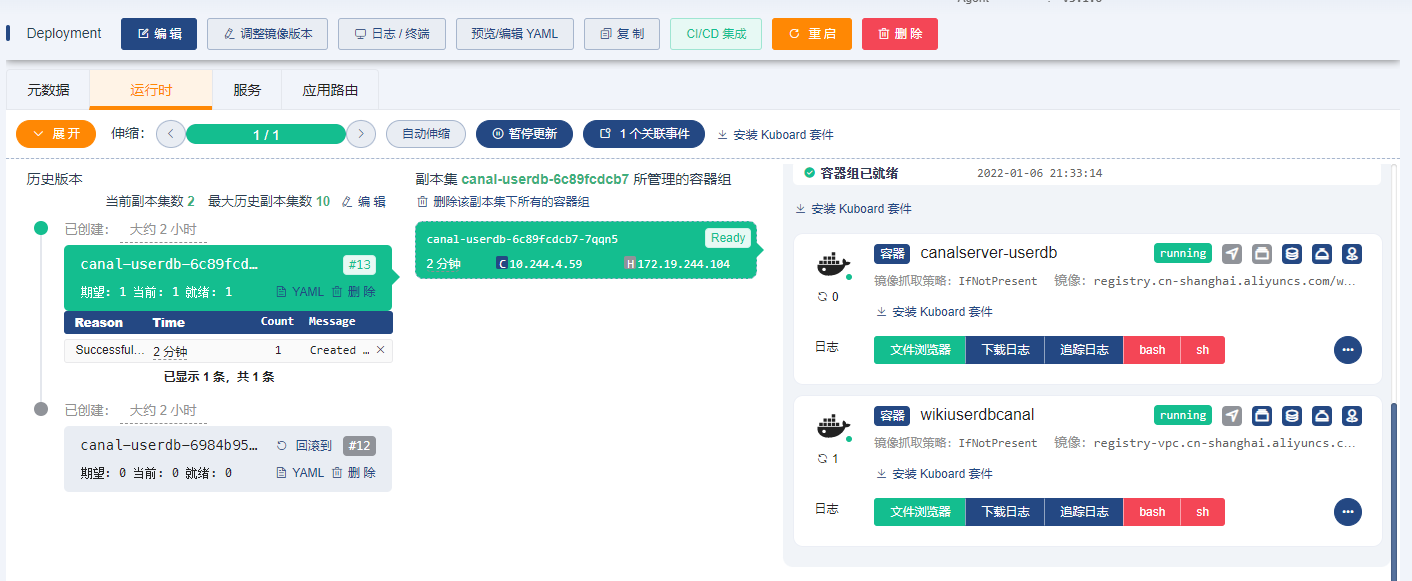
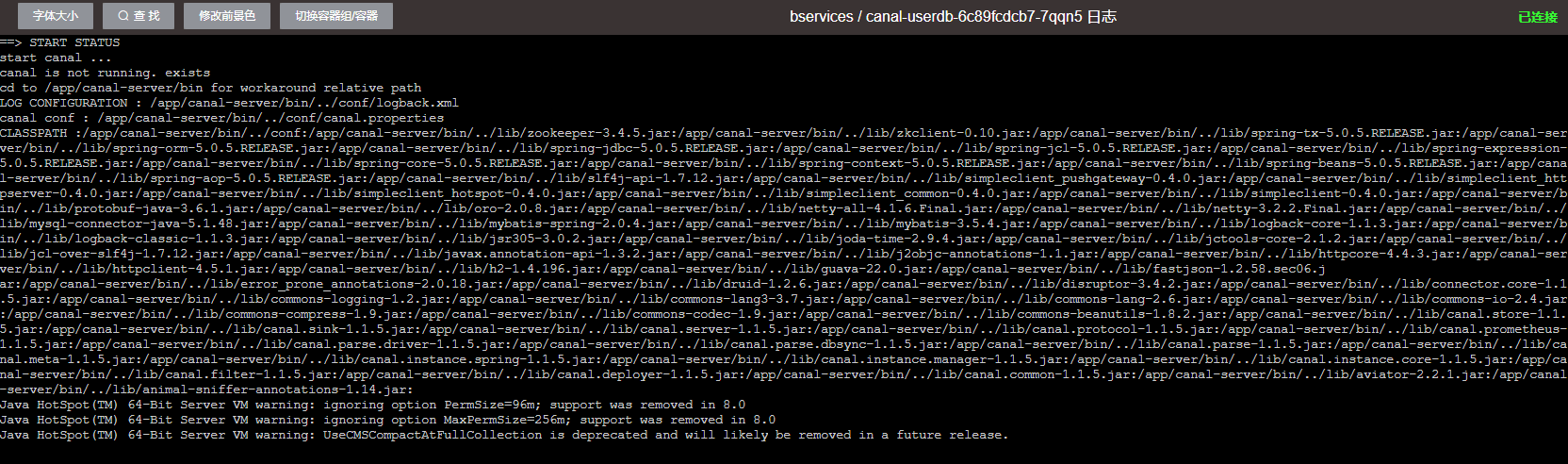
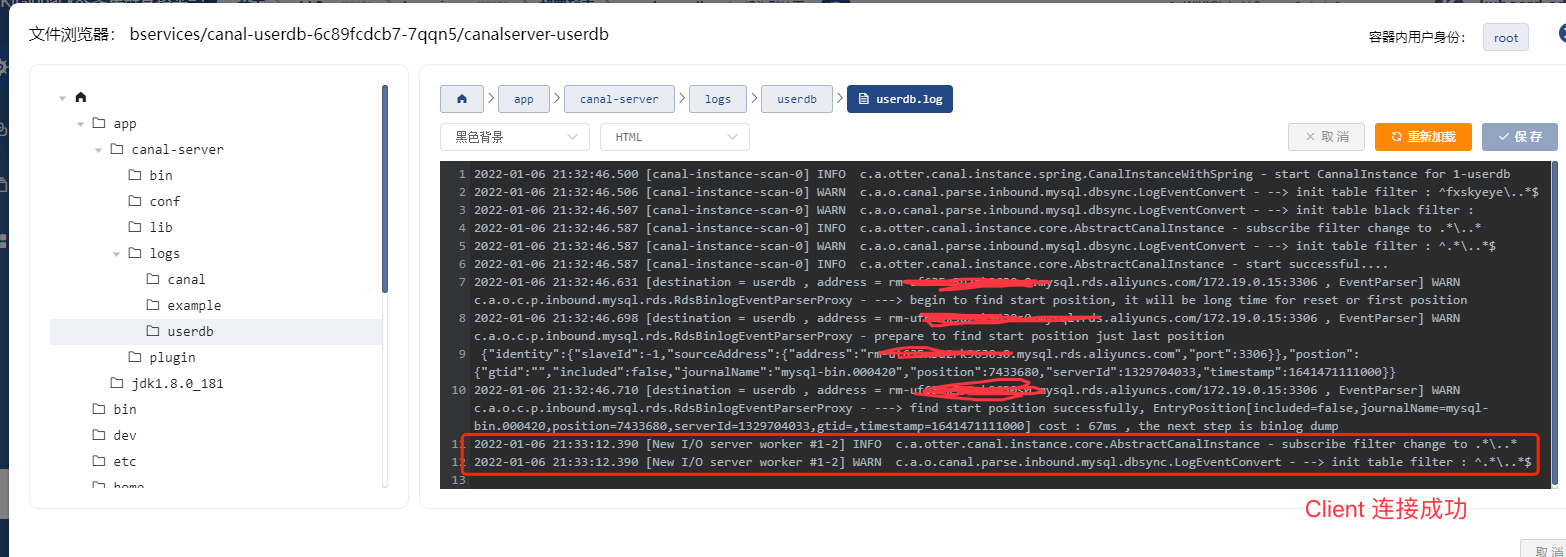
下载地址





评论