
需要用到的软件包;
- Atlas-2.2.1.el6.x86_64.rpm
- mha4mysql-manager-0.56-0.el6.noarch.rpm
- mha4mysql-node-0.56-0.el6.noarch.rpm
分别上传到三个主从节点上
基于GTID的1主2从构建过程参见:https://cakepanit.com/forward/c3e1b71a.html
配置关键程序软连接
ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /application/mysql/bin/mysql /usr/bin/mysql
#MHA 无法调用环境变量各个节点配置互信
#db01
rm -rf /root/.ssh
ssh-keygen //生成密钥对
cd /root/.ssh/
mv id_rsa.pub authorized_keys
scp -r /root/.ssh 192.168.56.3:/root
scp -r /root/.ssh 192.168.56.4:/root各节点验证
db01:
ssh 192.168.56.2 date
ssh 192.168.56.3 date
ssh 192.168.56.4 datedb02:
ssh 192.168.56.2 date
ssh 192.168.56.3 date
ssh 192.168.56.4 datedb03:
ssh 192.168.56.2 date
ssh 192.168.56.3 date
ssh 192.168.56.4 date安装软件
所有节点安装Node软件依赖包
yum install perl-DBD-MySQL -y
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm在db01主库中创建mha需要的用户
mysql -e "grant all privileges on *.* to mha@'192.168.56.%' identified by 'mha';"
mysql -e "select host,user,authentication_string from mysql.user;"
| 192.168.56.% | mha | *F4C9AC49A736981AE2739FC2F4A1FD92B4F07929 |检查其他从库节点是否同步
db02 db03:
| 192.168.56.% | mha | *F4C9AC49A736981AE2739FC2F4A1FD92B4F07929 |Manager软件安装(db03)
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm配置文件准备(db03)
创建配置文件目录 mkdir -p /etc/mha 创建日志目录 mkdir -p /var/log/mha/app1 编辑mha配置文件
cat > /etc/mha/app1.cnf<<EOF
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/binlog
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=repl
ssh_user=root
[server1]
hostname=192.168.56.2
port=3306
[server2]
hostname=192.168.56.3
candidate_master=1
port=3306
[server3]
hostname=192.168.56.4
port=3306
EOF状态检查(db03)
masterha_check_ssh --conf=/etc/mha/app1.cnf //检查ssh互信
masterha_check_repl --conf=/etc/mha/app1.cnf //检查主从状态开启MHA(db03):
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
指定配置文件 主节点宕机自动删除 跳过最后一次故障转移检查MHA状态(db03)
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:16488) is running(0:PING_OK), master:192.168.56.2MHA介绍
MHA目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为;MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
逻辑架构图
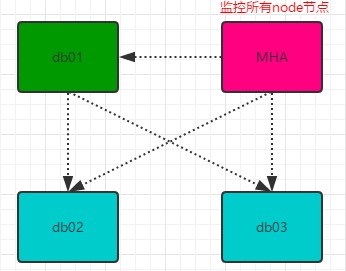
说明:物理上为3个node,一主两从结构。其中db03 同时充当Manager。
软件结构
Manager :
masterha_manger_启动MHAmasterha_check_ssh_检查MHA的SSH配置状况masterha_check_repl_检查MySQL复制状况masterha_master_monitor_检测master是否宕机masterha_check_status_检测当前MHA运行状态masterha_master_switch_控制故障转移(自动或者手动)masterha_conf_host_添加或删除配置的server信息
Node : 这些工具通常由MHA Manager的脚本触发,无需人为操作
save_binary_logs_保存和复制master的二进制日志apply_diff_relay_logs_识别差异的中继日志事件并将其差异的事件应用于其他的purge_relay_logs_清除中继日志(不会阻塞SQL线程)
MHA工作过程
安装过程说明
- 1.1 配置关键程序软连接,#MHA 无法调用环境变量。
- 1.2 各个节点配置互信,#为了故障转移时对新的master进行数据补偿
- 1.4 安装软件,在主库中创建mha用户,#控制端安装在所有节点上,mha用户用于监控所有节点状态
- manager安装在s3(db03)而不是m1或s2上,因为故障转移一般优先转至第一个从库即s2
- 1.5 配置文件准备(db03)
/etc/mha配置文件路径/var/log/mha/app1相关日志路径
- 1.6 状态检查(db03)#检查ssh互信和主从状态
mha配置文件:
cat > /etc/mha/app1.cnf<<EOF
[server default] //全局默认配置,所有节点生效
manager_log=/var/log/mha/app1/manager //工作日志存放位置
manager_workdir=/var/log/mha/app1 //工作目录位置
master_binlog_dir=/data/binlog //主库二进制日志存放位置
user=mha //1.4步所创建的用户
password=mha
ping_interval=2 //心跳检查间隔
repl_password=123
repl_user=repl //复制相关用户
ssh_user=root //配置互信的用户
[server1] //节点1名称
hostname=192.168.56.2
port=3306
[server2]
hostname=192.168.56.3
port=3306
[server3]
hostname=192.168.56.4
port=3306
//默认故障转移按照如上节点的顺序进行切换
EOFMHA工作过程(宕机)
manager 启动
- (1)读取
--conf=/etc/mha/app1.cnf配置文件 - (2)获取到node相关的信息(1主2从)
- (3)调用
masterha_check_ssh脚本 ,使用ssh_user=root进行互信检查 - (4)调用
masterha_check_repl检查主从复制情况 - (5)3 4 通过后,manager启动成功。
- (6)立即通过
masterha_master_monitor以ping_interval=2为间隔持续监控主库的状态- 网络,主机,数据库状态(利用mha用户)
- (7)当Manager监控到master宕机
- (8)开始选主过程
- 算法一:判断是否有《强制主》参数
- 算法二: 判断两个从库谁更新
- 算法三:按照配置文件书写顺序来选主
- (9)判断主库SSH的连通性
- 能:S1 和 S2 立即保存(save_binary_logs)缺失部分的binlog到本地
- 不能:
- 传统模式下:调用apply_diff_relay_logs计算S1和S2的 relay-log的差异(需要通过内容进行复杂的对比)
- 在GTID模式下:调用apply_diff_relay_logs计算S1和S2的 relay-log的差异(只需要对比GTID号码即可,效率较高)
- 最后进行数据补偿
- (10)解除S1从库身份
- (11)S2和S1构建新的主从关系
- (12)移除配置文件中故障节点
- (13)manager工作完成,自杀。(一次性的高可用)
额外的功能:
- (1) 提供了Binlog Server //异地实时保存主库binlog
- (2) 应用透明(VIP)
- (3) 实时通知管员(send_report)
- (4) 自愈系统(待开发。。。。)
MHA故障模拟&修复过程
故障模拟
停止主库
[root@db01 ~]# systemctl stop mysqld查看db02,db03
db02 [(none)]>show slave status \G;
Empty set (0.00 sec) //此时db02被选择并切换为了主库
ERROR:
No query specified
db03 [(none)]>show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.56.3 //这里主库ip指向了db02
db03 [(none)]>^DBye
[1]+ 完成 nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 //退出db03数据库时,manager自杀了MHA配置文件,及日志变化
日志:
[root@db03 ~]# tail -15 /var/log/mha/app1/manager //查看故障转移报告
----- Failover Report -----
app1: MySQL Master failover 192.168.56.2(192.168.56.2:3306) to 192.168.56.3(192.168.56.3:3306) succeeded
//MySQL主故障转移192.168.56.2(192.168.56.2:3306)到192.168.56.3(192.168.56.3:3306)成功
Master 192.168.56.2(192.168.56.2:3306) is down!
//原本的主库db01 down了
Check MHA Manager logs at db03:/var/log/mha/app1/manager for details.
//查看位于db03的MHA Manager日志:var/log/MHA/app1/Manager以了解详细信息。
Started automated(non-interactive) failover. //已启动自动(非交互式)故障转移。
Selected 192.168.56.3(192.168.56.3:3306) as a new master. //56.3作为新主控形状。
192.168.56.3(192.168.56.3:3306): OK: Applying all logs succeeded. //确定:应用所有日志成功。
192.168.56.4(192.168.56.4:3306): OK: Slave started, replicating from 192.168.56.3(192.168.56.3:3306) //确定:从机启动,从56.3复制
192.168.56.3(192.168.56.3:3306): Resetting slave info succeeded. //重设从机信息成功。
Master failover to 192.168.56.3(192.168.56.3:3306) completed successfully. //已成功完成到192.168.56.3(192.168.56.3:3306)的主故障转移。
配置文件:
[root@db03 ~]# cat /etc/mha/app1.cnf
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/binlog
password=mha
ping_interval=2
repl_password=123
repl_user=repl
ssh_user=root
user=mha
//原主库server1被剔除
[server2]
hostname=192.168.56.3
port=3306
[server3]
hostname=192.168.56.4
port=3306MHA故障修复
重新启动故障节点
[root@db01 ~]# systemctl start mysqld恢复主从结构
思路:
- 1.继续沿用之前故障转移之后的主库,将恢复后的故障库作为从库,挂到db02上。
- 2.如果db01损坏了,需要重新构建全新的mysql。记得将现在的主库db02进行全备,恢复到新的db01上,再重新构建主从
1.在原manager上查找构建从库语句
[root@db03 ~]# grep -i 'change master to ' /var/log/mha/app1/manager
Wed Apr 29 13:28:08 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.56.3', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx';
修改:
CHANGE MASTER TO
MASTER_HOST='192.168.56.3',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='repl',
MASTER_PASSWORD='123';
在db01上重新执行:
db01 [(none)]>CHANGE MASTER TO
-> MASTER_HOST='192.168.56.3',
-> MASTER_PORT=3306,
-> MASTER_AUTO_POSITION=1,
-> MASTER_USER='repl',
-> MASTER_PASSWORD='123';
Query OK, 0 rows affected, 2 warnings (0.01 sec)
db01 [(none)]>start slave;
Query OK, 0 rows affected (0.00 sec)
db01 [(none)]>show slave status \G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes修复MHA Manager
1.修改配置文件 (db03)
vim /etc/mha/app1.cnf
[server1]
hostname=192.168.56.2
port=3306
2.启动MHA
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
3.检查状态
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:26225) is running(0:PING_OK), master:192.168.56.3Manager额外参数介绍
说明:
主库宕机谁来接管?
- 所有从节点日志都是一致的,默认会以配置文件的顺序去选择一个新主。
- 从节点日志不一致,自动选择最接近于主库的从库
- 如果对于某节点设定了权重(candidate_master=1),权重节点会优先选择。 注意:但是此节点日志量落后主库100M日志的话,也不会被选择。可以配合
check_repl_delay=0,关闭日志量的检查,强制选择候选节点。
参数:
(1)ping_interval=1 #设置监控主库,发送ping包的时间间隔,尝试三次没有回应的时候自动进行failover
(2)candidate_master=1 #设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave #一般用于“两地三中心”的架构
(3)check_repl_delay=0 #默认情况下如果一个slave落后master 100M的relay logs的话, MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master,配合参数(2)
