
变量、常量
变量声明
标准声明:
var name string
var age int
var isOk bool
//变量声明以关键字var开头,变量类型放在变量的后面,行尾无需分号。
批量声明:
var (
a string
b int
c bool
d float32
)
//每声明一个变量就需要写var关键字会比较繁琐,go语言中还支持批量变量声明:语法格式
var 变量名 变量类型变量的初始化
Go语言在声明变量的时候,会自动对变量对应的内存区域进行初始化操作。每个变量会被初始化成其类型的默认值,例如: 整型和浮点型变量的默认值为0。 字符串变量的默认值为空字符串。 布尔型变量默认为false。 切片、函数、指针变量的默认为nil。
var 变量名 类型 = 表达式
//在声明变量的时候为其指定初始值。变量初始化的标准格式举个例子:
var name string = "Q1mi"
var age int = 18一次性初始化多个变量
var name, age = "Q1mi", 20类型推导
编译器根据等号右边的值来推导变量的类型完成初始化。
var name := "Q1mi"
var age := 18短变量声明
在函数内部,可以使用更简略的 := 方式声明并初始化变量。
package main
import (
"fmt"
)
// 全局变量m
var m = 100
func main() {
n := 10
m := 200 // 此处声明局部变量m
fmt.Println(m, n)
}匿名变量
package main
import "fmt"
func foo()(string,int){
return "felix",1
}
func main() {
aa, _ := foo() //匿名变量,垃圾桶用于接收不需要的变量值
fmt.Println("\n",aa)
}注意
在同一作用域内不能声明重复变量
:=简短声明之内存在于函数内
常量
常量声明
标准声明:
const pi = 3.1415
const e = 2.7182
批量声明:
const (
pi = 3.1415
e = 2.7182
)
相同常量声明:
const (
n1 = 100
n2
n3
)//四个常量值均为100时,只需要在批量声明中声明第一个常量示例
package main
import "fmt"
const felix = 3.14
const (
a1 = 1
a2
a3
)
func main(){
//felix = 3.2 //注意1
fmt.Println(felix,a1,a2,a3)
}注意
常量不允许修改
常量在定义的时候必须赋值
iota枚举[常量计数器]
package main
import "fmt"
const (
aa = iota //0
bb //1
cc //2
_ //3无,跳过某些值
ee //4
)
func main (){
fmt.Println(aa,bb,cc,ee)
}iota中,每新增一行变量声明就累加一次。
iota中,遇见const则归零。
iota只能在常量表达式中使用。
const中声明如果不写,默认就和上一行一样。
iota声明插队
const (
aa = iota //0 iota初始值
bb = 100 //100 固定值100
cc = iota //2 iota对每一行变量声明都会进行累加
_ //3 跳过该值
ee //4 累加
)
const ff = iota //0 iota遇到const关键字归零
func main (){
fmt.Println(aa,bb,cc,ee,ff)
}应用案例:
二进制:10000000000==十进制:1024
const (
_ = iota
kb = 1<<(10 * iota) //10*1=10,将1向左挪10位=1000000000,转为十进制为1024
mb = 1<<(10 * iota)
gb = 1<<(10 * iota)
tb = 1<<(10 * iota)
pb = 1<<(10 * iota)
)
func main(){
fmt.Println(kb,mb,gb,tb,pb)
}
/const>go run main.go
1024 1048576 1073741824 1099511627776 1125899906842624const (
a,b = iota+1,iota+2 //1 2
c,d //1+1=2,1+2=3
e,f //2+1=3,2+2=4
)
func main(){
fmt.Println(a,b,c,d,e,f)
}基本数据类型
Go语言中有丰富的数据类型,除了基本的整型、浮点型、布尔型、字符串外,还有数组、切片、结构体、函数、map、通道(channel)等。Go 语言的基本类型和其他语言大同小异。
整型
按长度分类
按长度分类:int8、int16、int32、int64
对应无符号:uint8、uint16、uint32、uint64
| 类型 | 描述 |
|---|---|
| uint8 | 无符号 8位整型 (0 到 255) |
| uint16 | 无符号 16位整型 (0 到 65535) |
| uint32 | 无符号 32位整型 (0 到 4294967295) |
| uint64 | 无符号 64位整型 (0 到 18446744073709551615) |
| int8 | 有符号 8位整型 (-128 到 127) |
| int16 | 有符号 16位整型 (-32768 到 32767) |
| int32 | 有符号 32位整型 (-2147483648 到 2147483647) |
| int64 | 有符号 64位整型 (-9223372036854775808 到 9223372036854775807) |
特殊整型
| 类型 | 描述 |
|---|---|
| uint | 32位操作系统上就是uint32,64位操作系统上就是uint64 |
| int | 32位操作系统上就是int32,64位操作系统上就是int64 |
| uintptr | 无符号整型,用于存放一个指针 |
2.1.3 注意
在使用
int和 uint类型时,不能假定它是32位或64位的整型,而是考虑int和uint可能在不同平台上的差异。获取对象的长度的内建
len()函数返回的长度可以根据不同平台的字节长度进行变化。实际使用中,切片或map的元素数量等都可以用int来表示。在涉及到二进制传输、读写文件的结构描述时,为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用int和 uint。
案例:
package main
import "fmt"
func main(){
// 十进制
var a int = 10
fmt.Printf("%d \n", a) // 10
fmt.Printf("%b \n", a) // 1010 占位符%b表示二进制
// 八进制 以0开头
var b int = 077
fmt.Printf("%o \n", b) // 77 占位符%o表示八进制
// 十六进制 以0x开头
var c int = 0xff
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF 占位符%X表示十六进制
}浮点型
Go语言支持两种浮点型数:float32和float64。这两种浮点型数据格式遵循IEEE 754标准: float32 的浮点数的最大范围约为 3.4e38,可以使用常量定义:math.MaxFloat32。 float64 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
打印浮点数时,可以使用fmt包配合动词%f,代码如下:
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("%f\n", math.Pi)
fmt.Printf("%.2f\n", math.Pi)
}复数
complex64和complex128
var c1 complex64
c1 = 1 + 2i
var c2 complex128
c2 = 2 + 3i
fmt.Println(c1)
fmt.Println(c2)复数有实部和虚部,complex64的实部和虚部为32位,complex128的实部和虚部为64位。
布尔型
Go语言中以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值。
注意:
布尔类型变量的默认值为
false。Go 语言中不允许将整型强制转换为布尔型.
布尔型无法参与数值运算,也无法与其他类型进行转换。
字符型
Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。 Go 语言里的字符串的内部实现使用UTF-8编码。 字符串的值为双引号(")中的内容,可以在Go语言的源码中直接添加非ASCII码字符,例如:
s1 := "hello"
s2 := "你好"字符串转义符
Go 语言的字符串常见转义符包含回车、换行、单双引号、制表符等,如下表所示。
| 转义符 | 含义 |
|---|---|
| \r | 回车符(返回行首) |
| \n | 换行符(直接跳到下一行的同列位置) |
| \t | 制表符 |
| ' | 单引号 |
| " | 双引号 |
| \ | 反斜杠 |
举个例子,打印一个Windows平台下的一个文件路径:
package main
import (
"fmt"
)
func main() {
fmt.Println("str := \"c:\\Code\\lesson1\\go.exe\"")
}多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符:
s1 := `第一行
第二行
第三行
`
fmt.Println(s1) //原样输出,不用转义反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
字符串的常用操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| #NAME? | 拼接字符串 |
| strings.Split | 分割 |
| strings.contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
name := "felix"
age := "20"
//字符串长度
fmt.Println(len(name),len(age))
运行结果:5 2
//字符串拼接
fmt.Println(name+age) //方法一
s1 := fmt.Sprintf("%s##%s",name,age) //方法二
fmt.Println(s1)
运行结果:felix##20
// 分割
ret := strings.Split(name, "x")
//“x”代表分隔符
fmt.Println(ret)
运行结果:[feli ]
// 判断是否包含
ret2 := strings.Contains(name, "lix")
fmt.Println(ret2)
运行结果:true
// 判断前缀和后缀 包含
ret3 := strings.HasPrefix(name, "fe")
ret4 := strings.HasSuffix(name, "lix")
fmt.Println(ret3, ret4)
运行结果:true true
// 求子串的位置 第一次和最后一次
s4 := "applepen"
fmt.Println(strings.Index(s4, "p")) //第一次出现
fmt.Println(strings.LastIndex(s4, "p")) //最后一次出现
运行结果:1 5 //从0开始
// join
a1 := []string{"Python", "PHP", "JavaScript", "Ruby", "Golang"}
fmt.Println(strings.Join(a1, "-"))
运行结果:Python-PHP-JavaScript-Ruby-Golangbyte和rune类型
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来,如:
var a := '中'
var b := 'x'
var a := '中'
var b := 'x'Go 语言的字符有以下两种
uint8类型,或者叫byte型,代表了ASCII码的一个字符。
rune类型,代表一个 UTF-8字符。
当需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32。
Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾。
s := "hello饼铛"
for i:=0;i<len(s);i++{ //byte类型
fmt.Printf("%v(%c)\n",i,s[i])
}
for k,v := range s{ //rune类型
fmt.Printf("%v(%c)\n",k,v)
}
//%c为单字符处理 %v打印索引
运行结果:
0(h)1(e)2(l)3(l)4(o)5(é)6(¥)7(¼)8(é)9()10()
0(h)1(e)2(l)3(l)4(o)5(饼)8(铛)因为UTF8编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。
字符串底层是一个byte数组,所以可以和[]byte类型相互转换。字符串是不能修改的 字符串是由byte字节组成,所以字符串的长度是byte字节的长度。 rune类型用来表示utf8字符,一个rune字符由一个或多个byte组成。
修改字符串
要修改字符串,需要先将其转换成[]rune或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
func changeString() {
s1 := "big"
// 强制类型转换
byteS1 := []byte(s1) //字符串转换为byte数组
byteS1[0] = 'p'
fmt.Println(string(byteS1))
s2 := "白萝卜"
runeS2 := []rune(s2) //包含中文字符串转换为byte数组
runeS2[0] = '红'
fmt.Println(string(runeS2))
}字符串反转
s6 := "hello" //01234
s7 := "" //定义一个空变量
for i:=len(s6)-1;i>=0;i--{
s6arry := []byte(s6) //h e l l o
s7 = s7+string(s6arry[i]) //o l l e h 从后往前遍历,并且拼接赋值给s7
}
fmt.Println(s7)流程控制
流程控制是每种编程语言控制逻辑走向和执行次序的重要部分,流程控制可以说是一门语言的“经脉”。
Go语言中最常用的流程控制有if和for,而switch和goto主要是为了简化代码、降低重复代码而生的结构,属于扩展类的流程控制。
if else(分支结构)
var age = 18
func main(){
if age > 18{
fmt.Printf("澳门首家线上赌场开业了\n")
}else if age == 18{
fmt.Printf("成年了\n")
}else{
fmt.Printf("好好念书")
}
}
//if条件判断还有一种特殊的写法,可以在 if 表达式之前添加一个执行语句,再根据变量值进行判断
if age:=18;age>=18 { //age变作用范围只在if内生效
fmt.Printf("函数内执行,成年了\n")
}for(循环结构)
Go语言中所有的循环类型都可以用for关键字来完成
for 初始语句;条件表达式;结束语句{
循环结构
}
//结束语句是指单词循环结束之后,下一轮循环执行之前需要执行的语句条件表达式返回true时循环体不停地进行循环,直到条件表达式返回false时自动退出循环。
for age :=18;age>0;age -- {
fmt.Println(age)
}for循环的初始语句可以被忽略,但是初始语句后的分号必须要写,例如:
age :=18
for ;age>0;age -- {
fmt.Println(age)
}for循环的初始语句和结束语句都可以省略,例如:
age :=18
for age>0 {
fmt.Println(age)
age --
}这种写法类似于其他编程语言中的while,在while后添加一个条件表达式,满足条件表达式时持续循环,否则结束循环。
无限循环
for {
fmt.Print("Hello world")
}for循环可以通过break、goto、return、panic语句强制退出循环。
for range(键值循环)
Go语言中可以使用for range遍历数组、切片、字符串、map 及通道(channel)。 通过for range遍历的返回值有以下规律:
数组、切片、字符串返回索引和值。
map返回键和值。
通道(channel)只返回通道内的值。
for k,v := range s{ //rune类型
fmt.Printf("%v(%c)\n",k,v)
}
//%c为单字符处理 %v打印索引switch case
使用switch语句可方便地对大量的值进行条件判断。if语句的变种
func switchDemo(){
felix := 1
switch felix {
case 1:
fmt.Println("felix == 1")
case 2:
fmt.Println("felix == 2")
case 3:
fmt.Println("felix == 3")
default:
fmt.Println("输入错误")
}
}Go语言规定每个switch只能有一个default分支。
一个分支可以有多个值,多个case值中间使用英文逗号分隔。
func testSwitch3(){
switch o := 4;o{
//在switch中定义变量,此变量作用域只作用于当前语句内
case 1,3,5,7,9:
fmt.Println("奇数")
case 2,4,6,8,10:
fmt.Println("偶数")
default:
fmt.Println("检查输入")
}
}分支还可以使用表达式,这时候switch语句后面不需要再跟判断变量。例如:
age := 101
switch {
case age <18:
fmt.Println("努力学习")
case age > 18 && age < 60:
fmt.Println("好好上班")
case age > 60 && <100:
fmt.Println("好好享受")
default:
fmt.Println("活着")
}fallthrough语法可以执行满足条件的case的下一个case,是为了兼容C语言中的case设计的。
a := "qq"
switch {
case a == "qq":
fmt.Println("a == qq")
fallthrough
case a == "yy":
fmt.Println("a == yy")
case a == "rr":
fmt.Println("a == rr")
default:
fmt.Println("检查输入")
}goto(跳转到指定标签)
标志位判断跳出
var flag = false //添加标志位
func main(){
for i:=0;i<10;i++{
fmt.Println(i)
//当条件满足时,重置标志位
if i == 5 {
fmt.Println("跳出单位")
flag = true
}
//跳出循环
if flag {
break
}
}
fmt.Println("跳出成功")
}goto语句通过标签进行代码间的无条件跳转。goto语句可以在快速跳出循环、避免重复退出上有一定的帮助。Go语言中使用goto语句能简化一些代码的实现过程。
例如双层嵌套的for循环要退出时:
func gotobrk(){
for x:=0;x<10;x++{
for y:=0;y<10;y++{
fmt.Println("%s-%s",x,y)
if y == 8{
goto felix
}
}
}
felix:
fmt.Println("跳出成功")
}
func main(){
gotobrk()
}break(跳出循环)
break语句可以结束for、switch和select的代码块。break语句还可以在语句后面添加标签,表示退出某个标签对应的代码块,标签要求必须定义在对应的for、switch和 select的代码块上。
举个例子:
func breakDemo1() {
BREAKDEMO1:
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
break BREAKDEMO1
//跳出当前标签下的代码,3-10行对应部份
}
fmt.Printf("%v-%v\n", i, j)
}
}
fmt.Println("...")
}continue(继续下次循环)
continue语句可以结束当前循环,开始下一次的循环迭代过程,仅限在for循环内使用。在 continue语句后添加标签时,表示开始标签对应的循环。例如:
func continueDemo() {
forloop1:
for i := 0; i < 5; i++ {
// forloop2:
for j := 0; j < 5; j++ {
if i == 2 && j == 2 {
continue forloop1
}
fmt.Printf("%v-%v\n", i, j)
}
}
}99乘法表
package main
import "fmt"
func main(){
for i:=9;i>0;i--{
//控制y轴
for j:=1;j<=i;j++{
//将j大小控制在i的范围内,控制x轴
s:=i*j
fmt.Printf("%d * %d = %d\t",j,i,s)
}
fmt.Println()
}
}
1 * 9 = 9 2 * 9 = 18 3 * 9 = 27 4 * 9 = 36 5 * 9 = 45 6 * 9 = 54 7 * 9 = 63 8 * 9 = 72 9 * 9 = 81
1 * 8 = 8 2 * 8 = 16 3 * 8 = 24 4 * 8 = 32 5 * 8 = 40 6 * 8 = 48 7 * 8 = 56 8 * 8 = 64
1 * 7 = 7 2 * 7 = 14 3 * 7 = 21 4 * 7 = 28 5 * 7 = 35 6 * 7 = 42 7 * 7 = 49
1 * 6 = 6 2 * 6 = 12 3 * 6 = 18 4 * 6 = 24 5 * 6 = 30 6 * 6 = 36
1 * 5 = 5 2 * 5 = 10 3 * 5 = 15 4 * 5 = 20 5 * 5 = 25
1 * 4 = 4 2 * 4 = 8 3 * 4 = 12 4 * 4 = 16
1 * 3 = 3 2 * 3 = 6 3 * 3 = 9
1 * 2 = 2 2 * 2 = 4
1 * 1 = 1运算符
运算符用于在程序运行时执行数学或逻辑运算。
Go 语言内置的运算符有:
算术运算符
关系运算符
逻辑运算符
位运算符
赋值运算符
算数运算符
| 运算符 | 描述 |
|---|---|
| + | 相加 |
| - | 相减 |
| * | 相乘 |
| / | 相除 |
| % | 求余 |
注意: ++(自增)和--(自减)在Go语言中是单独的语句,并不是运算符。既不能直接打印
关系运算符
| 运算符 | 描述 |
|---|---|
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False。 |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False。 |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 |
注意: 关系运算符返回值为布尔值
逻辑运算符
| 运算符 | 描述 |
|---|---|
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则为 True,否则为 False。 |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则为 True,否则为 False。 |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则为 False,否则为 True。 |
位运算符
位运算符对整数在内存中的二进制位进行操作。
| 运算符 | 描述 |
|---|---|
| & | 参与运算的两数各对应的二进位相与。(两位均为1才为1) |
| | | 参与运算的两数各对应的二进位相或。(两位有一个为1就为1) |
| ^ | 参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。(两位不一样则为1) |
| << | 左移n位就是乘以2的n次方。“a<<b”是把a的各二进位全部左移b位,高位丢弃,低位补0。 |
| >> | 右移n位就是除以2的n次方。“a>>b”是把a的各二进位全部右移b位。//二进制11往后移一位会变成1 |
赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 |
| += | 相加后再赋值 |
| -= | 相减后再赋值 |
| *= | 相乘后再赋值 |
| /= | 相除后再赋值 |
| %= | 求余后再赋值 |
| <<= | 左移后赋值 |
| >>= | 右移后赋值 |
| &= | 按位与后赋值 |
| |= | 按位或后赋值 |
| ^= | 按位异或后赋值 |
//将ip地址转为整数
var ip string = "192.168.19.200"
func main(){
iplist :=strings.Split(ip,".")
for i:=0;i<len(iplist);i++{
b,_ := strconv.Atoi(iplist[i])
fmt.Println(b)
}
}
//将ip地址转为二进制
var ip string = "192.168.19.200"
func main(){
iplist :=strings.Split(ip,".")
for i:=0;i<len(iplist);i++{
b,_ := strconv.Atoi(iplist[i])
if i == len(iplist) - 1 {
fmt.Printf("%08b",b)
}else {
fmt.Printf("%08b.",b)
}
}
}格式化打印Printf
通用占位符
| 占位符 | 说明 |
|---|---|
| %v | 值的默认格式表示 //%v永远1不会出错 |
| %+v | 类似%v,但输出结构体时会添加字段名 |
| %#v | 值的Go语法表示 |
| %T | 打印值的类型 |
| %% | 打印百分号 |
布尔型
| 占位符 | 说明 |
|---|---|
| %t | true或false |
整型
| 占位符 | 说明 |
|---|---|
| %b | 表示为二进制 |
| %c | 该值对应的unicode码值 |
| %d | 表示为十进制 %8d 右对齐空位补空格,%-8d左对齐空位补空格 |
| %o | 表示为八进制 |
| %x | 表示为十六进制,使用a-f |
| %X | 表示为十六进制,使用A-F |
| %U | 表示为Unicode格式:U+1234,等价于”U+%04X” |
| %q | 该值对应的单引号括起来的go语法字符字面值,必要时会采用安全的转义表示 |
指定长度整型
| 占位符 | 说明 |
|---|---|
| %5d | 整型长度为5,右对齐,左边留白 |
| %-5d | 左对齐,右边留白 |
| %05 | 数字前面补零 |
浮点数与复数
| 占位符 | 说明 |
|---|---|
| %b | 无小数部分、二进制指数的科学计数法,如-123456p-78 |
| %e | 科学计数法,如-1234.456e+78 |
| %E | 科学计数法,如-1234.456E+78 |
| %f | 有小数部分但无指数部分,如123.456 |
| %F | 等价于%f |
| %g | 根据实际情况采用%e或%f格式(以获得更简洁、准确的输出) |
| %G | 根据实际情况采用%E或%F格式(以获得更简洁、准确的输出) |
字符串和[]byte
| 占位符 | 说明 |
|---|---|
| %s | 直接输出字符串或者[]byte |
| %q | 该值对应的双引号括起来的go语法字符串字面值,必要时会采用安全的转义表示 |
| %x | 每个字节用两字符十六进制数表示(使用a-f |
| %X | 每个字节用两字符十六进制数表示(使用A-F) |
指针
| 占位符 | 说明 |
|---|---|
| %p | 表示为十六进制,并加上前导的0x |
数组 Array(数组)
数组是同一种数据类型元素的集合。 在Go语言中,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化。
基本语法:
// 定义一个长度为3元素类型为int的数组a
var a [3]int数组定义
var 数组变量名 [元素数量]T比如:
var a [5]int, 数组的长度必须是常量,并且长度是数组类型的一部分。一旦定义,长度不能变。
[5]int和[10]int是不同的类型,因为在go语言中 数组的长度也是类型的一部分。
var a [3]int
var b [4]int
a = b //不可以这样做,因为此时a和b是不同的类型数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1,访问越界(下标在合法范围之外),则触发访问越界,会panic。
数组的初始化
func main(){
//声明
var a1 [3]int
var a2 [4]int
//初始化 方式1
a1 = [3]int{1, 2, 3}
a2 = [4]int{1, 2, 3}
fmt.Println("方法1:",a1)
fmt.Println(a2)
//声明并初始化 方式2
//var a3 [5]string = [5]string{"f","e","l","i","x"}
var a3 = [5]string{"f","e","l","i","x"}
fmt.Println("方法2:",a3)
//让编译器决定数组初始值个数 方式3
var a4 = [...]int{1,2,3,2,4,5,5,5,6,6,54}
fmt.Println(a4)
fmt.Printf("a3:%T\ta4:%T\n",a3,a4) //a3:[5]string a4:[11]int
//根据索引值指定初始化 方式4
var a5 [20]int
a5 = [20]int{19:6} //索引为第19,赋值为6,[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6]
fmt.Println(a5)
}数组的遍历
//数组遍历方法1
for i:=0;i<len(a3);i++ {
fmt.Println(a3[i])
}
//数组遍历方法2
for k,v:= range a3{
fmt.Println(k,v)
}求数组元素和
func main() {
var a1 = [5]int{1,3,5,7,8}
var j int
for _,arry := range a1{
j += arry
}
fmt.Println(j)
//24
}求数组元素两两相加值为8的数据
func main() {
var a1 = [5]int{1,3,5,7,8}
//定义数组
for i,j := range a1 {
//遍历数组
for x:=i+1;x<len(a1);x++{
//依次求其他元素和
y:= j+a1[x]
if y == 8 {
//判断值是否为8
fmt.Printf("索引:(%d,%d) 值:(%d,%d) 和:(%d)\n",i,x,j,a1[x],y)
}
}
}
}
索引:(0,3) 值:(1,7) 和:(8)
索引:(1,2) 值:(3,5) 和:(8)多维数组
Go语言是支持多维数组的,我们这里以二维数组为例(数组中又嵌套数组)。
二维数组的定义
func main() {
a := [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
fmt.Println(a) //[[北京 上海] [广州 深圳] [成都 重庆]]
fmt.Println(a[2][1]) //支持索引取值:重庆
//声明
var mafeifei [2][2]int
//初始化
mafeifei = [2][2]int{
{11,22},
{33,44},
}
//声明并初始化
var felix = [...][2]int{ //方法1
{1,2},
{3,4}}
pincheng := [...][3]int{ //方法2
{5,6},
{7,8},
{9,10},
}
fmt.Println(mafeifei,felix,pincheng)
}
[[11 22] [33 44]] [[1 2] [3 4]] [[5 6 0] [7 8 0] [9 10 0]]注意:多维数组只能在第一层使用...来让编译器推导数组长度。
多维数组遍历
方法1:
for i:=0;i<len(pincheng);i++ {
//拿到第一层数组的长度,累加
for j:=0;j<len(pincheng[i]);j++ {
//拿到第二层数组的长度,累加
fmt.Println(pincheng[i][j])
}
}
方法2:
for _,v1 := range pincheng{
//遍历第一层数据
for _,v2 := range v1 {
//对单层再次遍历
fmt.Println(v2)
}
}数组是值类型
数组是值类型,赋值和传参会复制整个数组。因此改变副本的值,不会改变本身的值。
func main() {
nashsu := [...][3]int{
{2,3,4},
{5,6,7},
{8,9,10},
}
su := nashsu
su[1][1] = 666
fmt.Println(nashsu,su)
}
// [[2 3 4] [5 6 7] [8 9 10]] [[2 3 4] [5 666 7] [8 9 10]]切片
因为数组的长度是固定的并且数组长度属于类型的一部分,所以数组有很多的局限性。 例如:
func arraySum(x [3]int) int{
sum := 0
for _, v := range x{
sum = sum + v
}
return sum
}这个求和函数只能接受[3]int类型,其他的都不支持。 再比如,
a := [3]int{1, 2, 3}数组a中已经有三个元素了,我们不能再继续往数组a中添加新元素了。
切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片是一个引用类型(区别于值类型),它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合。
地址:数组中第一位元素的内存地址
长度:切片中总共多少个元素
容量:最大能放多少个元素
引用类型:
func main() {
a := []int{1,2,3,4,5}
b := a
//将a变量的内存地址赋值给了b
b[0] = 100
fmt.Println(a)
fmt.Println(b)
}
[100 2 3 4 5]
[100 2 3 4 5]切片的定义
声明切片类型的基本语法如下:
var name []T
var a []string //声明一个字符串切片
,此时并未申请内存
var b = []int{} //声明一个整型切片并初始化
var c = []bool{false, true} //声明一个布尔切片并初始化其中
name:表示变量名
T:表示切片中的元素类型
举个例子:
package main
import "fmt"
func main(){
//声明切片方式1:直接声明
felix := [3]int{1,2,3} //数组
mafei := []int{1,2,3} //切片
fmt.Printf("felix:%T,mafei%T\n",felix,mafei) //felix:[3]int,mafei[]int
fmt.Printf("felix:%v,mafei%v\n",felix,mafei) //felix:[1 2 3],mafei[1 2 3]
//声明切片方式2:从数组声明赋值
var (
a []int
b []int
c []int
)
a = felix[0:2] //左包含又不包含
b = felix[1:] //从1起全包含
c = felix[:] //全包含
fmt.Printf("%T_%v,%T_%v,%T_%v",a,a,b,b,c,c) //[]int_[1 2],[]int_[2 3],[]int_[1 2 3]
}切片的长度和容量
切片拥有自己的长度和容量,我们可以通过使用内置的len()函数求长度,使用内置的cap()函数求切片的容量。
package main
import "fmt"
func main(){
city := []string{"北京","上海","广州","深圳"}
fmt.Printf("city长度:%d",len(city)) //4,切片元素个数
fmt.Printf("city最大容量%d",cap(city)) //4,最大元素个数
fmt.Printf("city切片后容量%d",cap(city[1:])) //3,同上
}
//city长度:4
//city最大容量4
//city切片后容量3切片三要素:
地址(切片中第一个元素指向的内存空间)
大小(切片中目前元素的个数)
len()容量(底层数组最大能存放的元素个数)
cap()
判断切片是否为空:
要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。
func main() {
//定义切片
var a []int
//声明切片但未初始化
a[0] = 100
//直接更改
fmt.Println(a)
}
//此时编译通过,但是执行时会提示索引越界
//解决办法,切片声明后一定要初始化,例如使用make函数
runtime error: index out of range [0] with length 0扩容规律:
切片支持自动扩容策略,每次都是上一次的两倍
package main
import "fmt"
func main(){
//append(),添加元素扩容切片
var a []int
for i:=0;i<10;i++{
a = append(a,i)
fmt.Printf("%v len:%d cap:%d ptr:%p \n",a,len(a),cap(a),a)
}
//追加多个元素 citySlice = append(citySlice, "上海", "广州", "深圳")
//追加单个元素 citySlice = append(citySlice, "北京"),必须为字符串
}
[0] len:1 cap:1 ptr:0xc00000a0b0
[0 1] len:2 cap:2 ptr:0xc00000a0f0
//容量用完翻倍扩容
[0 1 2] len:3 cap:4 ptr:0xc00000e380
//容量用完翻倍扩容
[0 1 2 3] len:4 cap:4 ptr:0xc00000e380
[0 1 2 3 4] len:5 cap:8 ptr:0xc00000c380
//容量用完翻倍扩容
[0 1 2 3 4 5] len:6 cap:8 ptr:0xc00000c380
[0 1 2 3 4 5 6] len:7 cap:8 ptr:0xc00000c380
[0 1 2 3 4 5 6 7] len:8 cap:8 ptr:0xc00000c380
[0 1 2 3 4 5 6 7 8] len:9 cap:16 ptr:0xc000082080
//容量用完翻倍扩容
[0 1 2 3 4 5 6 7 8 9] len:10 cap:16 ptr:0xc000082080make()函数构造切片
基于数组来创建的切片,如果需要动态的创建一个切片,我们就需要使用内置的make()函数,格式如下:
make([]T, size, cap)其中:
T:切片的元素类型
size:切片中元素的数量
cap:切片的容量
例:
func main() {
a := make([]int, 2, 10)
fmt.Println(a) //[0 0]
fmt.Println(len(a)) //2
fmt.Println(cap(a)) //10
}上面代码中a的内部存储空间已经分配了10个,但实际上只用了2个。 容量并不会影响当前元素的个数,所以len(a)返回2,cap(a)则返回该切片的容量。
copy()函数复制切片
首先我们来看一个问题:
func main() {
a := []int{1, 2, 3, 4, 5}
b := a
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(b) //[1 2 3 4 5]
b[0] = 1000
fmt.Println(a) //[1000 2 3 4 5]
fmt.Println(b) //[1000 2 3 4 5]
}由于切片是引用类型,所以a和b其实都指向了同一块内存地址。修改b的同时a的值也会发生变化。
Go语言内建的copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式如下:
copy(destSlice, srcSlice []T)其中:
srcSlice: 数据来源切片
destSlice: 目标切片
举个例子:
func main() {
// copy()复制切片
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5) //申请内存,长度为5,容量为5
copy(c, a) //使用copy()函数将切片a中的元素深拷贝到切片c
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1 2 3 4 5]
c[0] = 1000
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1000 2 3 4 5]
}从切片中删除元素
Go语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素。 代码如下:
package main
import "fmt"
func main(){
//删除切片中某个元素
city := []string{"北京","上海","广州","深圳"}
city = append(city[:1],city[2:]...)
//append()追加
//city[:1] //"北京",包左不包右。这个代表容器
//city[2:] //"广州","深圳"。这个代表要追加的元素
//... //依次取出元素
为字符串形式
fmt.Println(city)
}总结一下就是:要从切片a中删除索引为index的元素,操作方法是a = append(a[:index], a[index+1:]...)
切片基于数组
func main() {
// 定义一个数组
a := [...]int{1,2,3,4,5,6,7,8}
// 基于数组得到一个切片
b := a[:]
// 修改切片中的元素为100
b[0] = 100
fmt.Println(a,b)
//[100 2 3 4 5 6 7 8] [100 2 3 4 5 6 7 8]
}切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)和切片的容量(cap)。
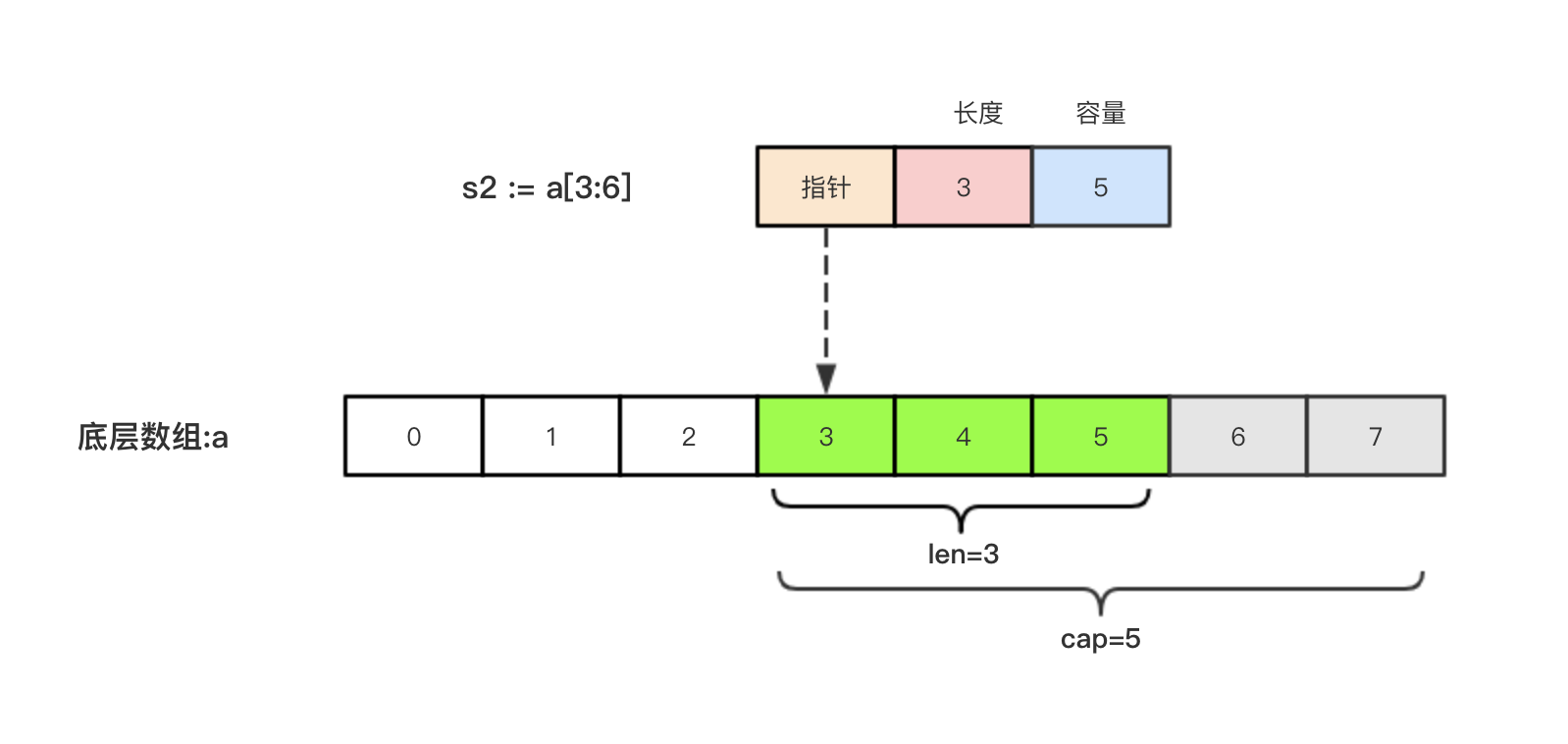
举个例子,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片s1 := a[:5],相应示意图:
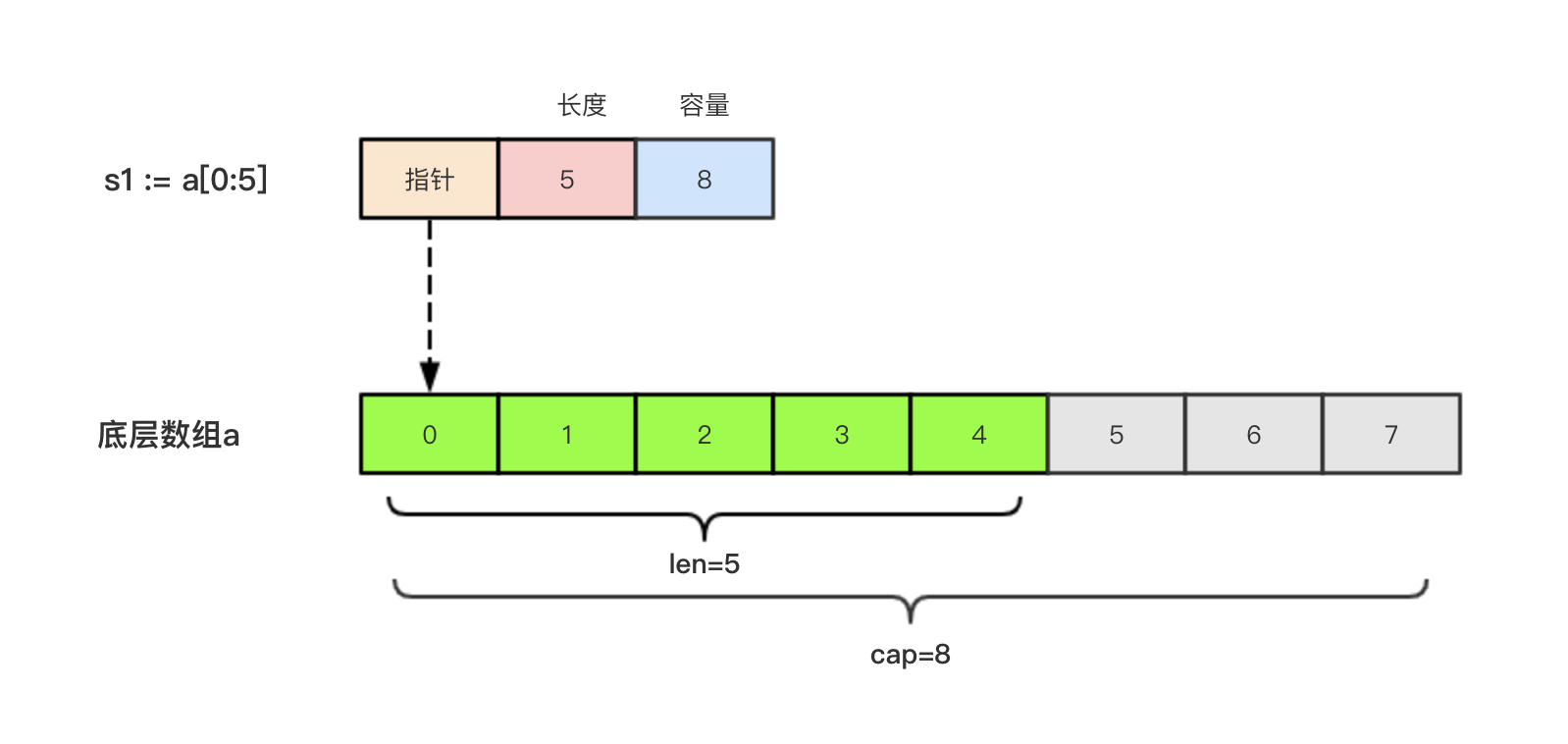
切片s2 := a[3:6],相应示意图:
切片的遍历
func main() {
//定义切片
a := []int{55,56,57,58}
//以索引方式遍历
for i:=0;i<len(a);i++{
fmt.Println(a[i])
}
//以range方式便利
for _,a := range a {
fmt.Println(a)
}
}sort切片排序
func main() {
//定义切片
var a = [...]int{8,1,3,5,4,10}
//对切片排序
,切片指向了底层数组所以对切片排序就是对底层数组排序
sort.Ints(a[:])
fmt.Println(a)
}map
golang中映射关系容器为map,其内部使用散列表(hash)实现。
map定义
Go语言中 map的定义语法如下:
map[KeyType]ValueType
key类型 值类型其中,
KeyType:表示键的类型。
ValueType:表示键对应的值的类型。
map类型的变量默认初始值为nil,需要使用make()函数来分配内存。语法为:
make(map[KeyType]ValueType, [cap])其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量。
例:
func main(){
var a map[string]int
//声明一个键类型为字符串,值类型为int的map
fmt.Println(a == nil,a)
//只声明未初始化,说明map初始值为nil
a = make(map[string]int 8) //初始化map,指定容量
fmt.Println(a == nil,a)
}
true map[]
false map[]map使用
map中的数据都是成对出现的,map的基本使用示例如下:
func main(){
socreMap := make(map[string]int, 8)
//shnm
socreMap["飞驰"] = 18
socreMap["灰驰"] = 20
fmt.Printf("%#v \n%v \nType of:%T \n",socreMap,socreMap["灰驰"],socreMap)
}
map[string]int{"灰驰":20, "飞驰":18}
20
Type of:map[string]intmap也支持在声明的同时完成初始化,例如:
func main(){
socreMap2 := map[string]int{
"马飞飞" : 21,
"卢本伟" : 22,
}
fmt.Printf("%#v \n%v \nType of:%T \n",socreMap2,socreMap2["卢本伟"],socreMap2)
}
map[string]int{"卢本伟":22, "马飞飞":21}
22
Type of:map[string]intmap使用时必须进行初始化:
func main() {
var test map[int]int
test[100] = 100
fmt.Println(test) //panic: assignment to entry in nil map,由于map只声明未进行初始化
}
修改
func main() {
var test map[int]int
test = make(map[int]int,8)
test[100] = 100
fmt.Println(test)
}map判断键值对是否存在
func main() {
var mapCredit = make(map[string]int, 8)
mapCredit["z3"] = 59
mapCredit["l4"] = 60
fmt.Printf("%#v \n",mapCredit)
//map[string]int{"l4":60, "z3":59}
value, ok := mapCredit["w5"]
fmt.Println(value,ok)
//59 true
if ok {
fmt.Printf("w5存在,值为:%v \n",value)
}else {
fmt.Println("w5查无此人")
}
}map遍历
func main() {
var mapCredit = make(map[string]int, 8)
mapCredit["z3"] = 59
mapCredit["l4"] = 60
fmt.Printf("%#v \n",mapCredit)
//range遍历map,map中的元素是无序的
for k,v := range mapCredit {
fmt.Println(k,v)
}
//只遍历键
for k := range mapCredit {
fmt.Println(k)
}
//只遍历值
for _,v :=range mapCredit {
fmt.Println(v)
}
}
z3 59
l4 60
z3
l4
59
60按指定顺序遍历map
func main() {
//按照顺序遍历map
//1.生成50个元素的map
var somap = make(map[string]int,50)
for i:=0;i<50;i++ {
key := fmt.Sprintf("sum%02d", i)
value := rand.Intn(100) //0~99的随机整数
somap[key] = value
}
for km,vm := range somap {
fmt.Printf("%v:%v ",km,vm)
}
fmt.Println("\n")
//2.将map中的key放入切片
soslice := make([]string,0,50) //长度为0,容量为50。长度必须为0,负责会产生nil值填充的元素。影响后续追加
for k := range somap{
soslice = append(soslice,k) //取出map中的k,追加进切片
}
//3.对切片进行排序
sort.Strings(soslice[:])
//fmt.Println(soslice)
//4.按照切片中的顺序遍历map
for _,sv := range soslice{
fmt.Print(sv,":",somap[sv]," ")
}
}
sum23:58 sum26:87 sum00:81 sum09:0 sum20:95 sum35:56 sum48:59 sum02:47 sum10:94 sum12:62 sum37:31 sum39:26 sum41:90 sum44:33 sum47:24 sum03:59 sum04:81 sum13:89 sum29:15 sum36:37 sum38
:85 sum46:78 sum34:29 sum42:94 sum49:53 sum01:87 sum08:56 sum15:74 sum16:11 sum17:45 sum25:47 sum28:90 sum30:41 sum32:87 sum33:31 sum40:13 sum43:63 sum06:25 sum07:40 sum14:28 sum18:37
sum19:6 sum22:28 sum24:47 sum27:88 sum05:18 sum11:11 sum21:66 sum31:8 sum45:47
sum00:81 sum01:87 sum02:47 sum03:59 sum04:81 sum05:18 sum06:25 sum07:40 sum08:56 sum09:0 sum10:94 sum11:11 sum12:62 sum13:89 sum14:28 sum15:74 sum16:11 sum17:45 sum18:37 sum19:6 sum20:
95 sum21:66 sum22:28 sum23:58 sum24:47 sum25:47 sum26:87 sum27:88 sum28:90 sum29:15 sum30:41 sum31:8 sum32:87 sum33:31 sum34:29 sum35:56 sum36:37 sum37:31 sum38:85 sum39:26 sum40:13 su
m41:90 sum42:94 sum43:63 sum44:33 sum45:47 sum46:78 sum47:24 sum48:59 sum49:53类型为map的切片
func main() {
//元素类型为map的切片
slice := make([]map[string]int,8,8) //此时只初始化了切片
fmt.Println(slice[0] == nil)
//true
//切片中[nil nil nil nil nil nil nil nil]
//slice[0]["马飞"]=1,不能赋值,因为此时切片中的map元素还没初始化
//初始化切片中的map
slice[0] = make(map[string]int,8)
slice[0]["马hu"]=1
fmt.Println(slice[:])
//[map[马hu:1] map[] map[] map[] map[] map[] map[] map[]]
}类型为切片的map
//元素为切片的map
var sliceMap = make(map[string][]int,8) //初始化外层map
sliceMap["felix"] = make([]int, 8,8) //初始化切片
sliceMap["feliy"] = make([]int, 6,6)
fmt.Println(sliceMap)
//map[felix:[0 0 0 0 0 0 0 0] feliy:[0 0 0 0 0 0]]
sliceMap["felix"][0] = 100 //给切片0元素赋值
for i := range sliceMap {
//遍历map中所有元素名,对遍历出的切片进行赋值
for x:=0;x<cap(sliceMap[i]);x++{
sliceMap[i][x] = x
}
}
fmt.Println(sliceMap)
//map[felix:[0 1 2 3 4 5 6 7] feliy:[0 1 2 3 4 5]]
for k,v := range sliceMap{
//对其中的切片进行遍历
fmt.Print(k)
for _,Sv := range v {
fmt.Printf("%v",Sv)
}
}
//felix0 1 2 3 4 5 6 7 feliy0 1 2 3 4 5统计单词出现次数
func main() {
//"How do you do"每个单词出现次数
s := "How do you do"
wordCount := make(map[string]int,10)
//字符串转切片
words := strings.Split(s, " ")
fmt.Println(words) //[How do you do]
//遍历切片并将结果放入map
for _,v := range words {
wv,ok := wordCount[v]
//值存在,那么ok=true且wv为该键的值反之则为false
if ok {
wordCount[v] = wv + 1 //如果map中存在那么将对应值+1
} else {
wordCount[v] = 1 //如果不存在,则初始化为1
}
}
for wordMap := range wordCount {
fmt.Printf("%v:%v\n",wordMap,wordCount[wordMap])
}
}
//How:1
//do:2
//you:1函数
Go语言中支持函数、匿名函数和闭包,并且函数在Go语言中属于“一等公民”。
Go语言中定义函数使用func关键字,具体格式如下:
func 函数名(参数)(返回值){
函数体
}其中:
函数名:由字母、数字、下划线组成。但函数名的第一个字母不能是数字。在同一个包内,函数名也称不能重名(包的概念详见后文)。
参数:参数由参数变量和参数变量的类型组成,多个参数之间使用
,分隔。返回值:返回值由返回值变量和其变量类型组成,也可以只写返回值的类型,多个返回值必须用
()包裹,并用,分隔。函数体:实现指定功能的代码块。
我们先来定义一个求两个数之和的函数:
func intSum(x int, y int) int {
return x + y
}函数的参数和返回值都是可选的,例如我们可以实现一个既不需要参数也没有返回值的函数:
func sayHello() {
fmt.Println("Hello 沙河")
}函数调用
//单个参数传递
func sayHallo(name string) { //定义一个为字符串类型的参数,此处和下方调用时填写的参数名称无关
fmt.Println("hello", name)
}
func main() {
n := "felix"
sayHallo(n) //hello felix
sayHallo("liupi") //hello liupi
}
//多个参数传递
func intSum(a , b int) int {
//函数的参数中如果相邻变量的类型相同,则可以省略类型;返回值类型 int;
s := a + b
return s
}
func main() {
f := intSum(35,40)
fmt.Println(f)
//75
}
//多个参数传递写法2
func intMultiply(a int,b int)(rfc int){
//声明要返回的变量
rfc = a * b
//此时不需要类型推倒
return
}
func main() {
g := intMultiply(35,40)
fmt.Println(g)
//1400
}可变参数
可变参数是指函数的参数数量不固定。Go语言中的可变参数通过在参数名后加...来标识。
注意:可变参数通常要作为函数的最后一个参数。
举个例子:
func intMultiply1(c ...int) (v int) {
fmt.Printf("Type:%T,Value:%v\n",c,c)
//Type:[]int,Value:[1 2 3 4 5]
v = 1
for _,x := range c{
v = v + x
}
return
}
func main() {
h := intMultiply1(1,2,3,4,5)
fmt.Println(h)
//16
}
func mafeifei(a int,b ...int)(rfc int) { //固定参数搭配可变参数
时,可变参数要放到最后面;go函数中没有漠然默认参数
rfc = a
for _,x := range b {
rfc = a + x
}
return
}
func main(){
fmt.Println(mafeifei(7)) //a=7,b=[]int
fmt.Println(mafeifei(10))//a=10,b=[]int
fmt.Println(mafeifei(10,20))//a=10,b=[]int{20}
fmt.Println(mafeifei(10,30))//a=10,b=[]int{30}
}多个返回值
func mafeifei(a ,b int)(sum ,sub int){
sum = a + b
sub = a - b
return
}
func main(){
x ,y :=mafeifei(100,200)
fmt.Println(x,y)
//300 -100
}defer语句
Go语言中的defer语句会将其后面跟随的语句进行延迟处理。在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行,也就是说,先被defer的语句最后被执行,最后被defer的语句,最先被执行。
defer //延迟执行
func main(){
fmt.Println("start")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("end")
}
start
end
3
2
1由于defer语句延迟调用的特性,所以defer语句能非常方便的处理资源释放问题。比如:资源清理、文件关闭、解锁及记录时间等。
变量作用域
全局变量
全局变量是定义在函数外部的变量,它在程序整个运行周期内都有效。 在函数中可以访问到全局变量。
局部变量
局部变量又分为两种:
1.函数内定义的变量无法在该函数外使用。
2.语句块定义的变量,通常我们会在if条件判断、for循环、switch语句上使用这种定义变量的方式。
高阶函数
函数可以作为参数:
//高阶函数
func add(x,y int) int {
return x + y
}
func less(x,y int) int {
return x - y
}
//参数1:x
//参数2:y
//参数3:函数类型
func cls(x,y int,fu func(int,int) int) int {
return fu(x,y)
}
func main(){
//将函数当成参数赋值给另一个函数
fmt.Println(cls(200,300,add))
//500
fmt.Println(cls(200,300,less))
//-100
}函数作为返回值:
func do(s string) (func(int, int) int, error) {
switch s {
case "+":
return add, nil
case "-":
return sub, nil
default:
err := errors.New("无法识别的操作符")
return nil, err
}
}匿名函数
匿名函数就是没有函数名的函数,匿名函数的定义格式如下:
func main() {
//匿名函数的定义并执行方法一
func(){
fmt.Println("匿名函数1")
}()
//匿名函数的定义并执行方法二
hello := func(){
fmt.Println("匿名函数2")
}
hello()
}闭包
闭包指的是一个函数和与其相关的引用环境组合而成的实体。简单来说,闭包=函数+引用环境。 例:
//定义一个函数,他的返回值是一个函数
func felix(mff string) func() {
//mff := "盖亚"
return func() {
fmt.Println("lbwlb",mff)
}
}
//闭包 + 函数+外部变量的引用
func main() {
helloLbw := felix("盖亚") //helloLbw此时就是一个闭包
helloLbw() //相当于执行了felix函数内的匿名函数 + 函数之外的一个变量引用。称之为闭包
}闭包做后缀名校验
func checkSuffix(suffix string) (func(string) string) {
return func (name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix //如果传进来的后缀名不是suffix变量,那么将文件名+suffix变量return并结束
}
return name //否则直接返回原值
}
}
func main() {
felixFunc:=checkSuffix(".txt")
//传入需要校验的后缀名
fmt.Println(felixFunc("xiaohei"))
//xiaohei.txt
}闭包示例2
func calc(base int) (func(int)int,func(int)int) {
add := func(i int) int {
base += i
return base
}
sub := func(i int) int {
base -= i
return base
}
return add,sub
}
func main(){
jia,jian:=calc(7) //将两个闭包分别赋值给了jia,jian
fmt.Println(jia(1)) //base = 7 + 1
fmt.Println(jian(1)) //base = 8 - 1
}内置函数
| 内置函数 | 介绍 |
|---|---|
| close | 主要用来关闭channel |
| len | 用来求长度,比如string、array、slice、map、channel |
| new | 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针 |
| make | 用来分配内存,主要用来分配引用类型,比如chan、map、slice |
| append | 用来追加元素到数组、slice中 |
| panic和recover | 用来做错误处理 |
panic/recover
Go语言中目前(Go1.12)是没有异常机制,但是使用panic/recover模式来处理错误。 panic可以在任何地方引发,但recover只有在defer调用的函数中有效。例子:
package main
import "fmt"
func funcA() {
fmt.Println("func A")
}
func funcB() {
defer func() {
err := recover()
if err != nil {
fmt.Println("报了个错")
//fmt.Println(recover())
}
}()
panic("panic in B")
}
func funcC() {
fmt.Println("func C")
}
func main() {
funcA()
funcB()
funcC()
}
func A
报了个错
func C分金币作业
package main
import "fmt"
//分金币作业
// 你有50枚金币,需要分配给以下几个人:Matthew,Sarah,Augustus,Heidi,Emilie,Peter,Giana,Adriano,Aaron,Elizabeth。
// 分配规则如下:
// a. 名字中每包含1个'e'或'E'分1枚金币
// b. 名字中每包含1个'i'或'I'分2枚金币
// c. 名字中每包含1个'o'或'O'分3枚金币
// d: 名字中每包含1个'u'或'U'分4枚金币
// 写一个程序,计算每个用户分到多少金币,以及最后剩余多少金币?
var (
coins = 50
users = []string{
"Matthew", "Sarah", "Augustus", "Heidi", "Emilie", "Peter", "Giana", "Adriano", "Aaron", "Elizabeth",
}
distribution = make(map[string]int, len(users))
)
func StringTraversal(name string) (int) {
//单个名字累加金币
Gophers:=0
for _,x := range name {
switch x {
case 'e','E':
Gophers ++
case 'i','I':
Gophers += 2
case 'o','O':
Gophers += 3
case 'u','U':
Gophers += 4
}
}
//金币总数减去每个人所得金币
coins -= Gophers
return Gophers
}
func dispatchCoin() {
//将每个人金币放入map对应的value中
for _,i := range users {
distribution[i] = StringTraversal(i)
}
//遍历map
for n,c := range distribution{
fmt.Println("名字:",n,"分得:",c)
}
}
func main() {
dispatchCoin()
fmt.Printf("剩下:%v \n", coins)
}